自然语言处理
- 156 次浏览
【NLP】2023年精通NLP 的20个项目及其源代码 --第一部分
视频号

微信公众号

知识星球

使用源代码探索一些简单、有趣和高级的NLP项目想法,您可以练习这些想法以成为一名NLP工程师。
自然语言处理(NLP)是一个跨学科的领域,主要研究使用自然语言的人与计算机之间的交互。随着数字通信的兴起,NLP已经成为现代技术的一个组成部分,使机器能够理解、解释和生成人类语言。这个博客探索了一系列有趣的NLP项目想法,从初学者的简单NLP项目到专业人士的高级NLP项目,这些项目将有助于掌握NLP技能。
根据美国劳工统计局的一份报告,从2020年到2030年,计算机和信息研究科学家的工作岗位预计将增长22%。根据世界经济论坛2020年10月发布的《未来就业报告》,到2025年,人类和机器将在公司当前任务上花费相同的时间。该报告还透露,约40%的员工将被要求重新培训,94%的企业领导人希望员工投资学习新技能。他们对采用云计算以及非人类机器人、人工智能和加密等其他技术表现出了极大的兴趣。
上述所有数字表明,对熟练实施基于人工智能的技术的人的需求将非常大。人工智能的一个子领域是自然语言处理(NLP),它正在科技界逐渐崭露头角。如果你开始回忆起你每天访问的许多网站或移动应用程序都在使用基于NLP的机器人来提供客户支持,你就可以很容易地理解这一事实。
正如我们在2021年机器学习NLP面试问答博客中所揭示的那样,在LinkedIn上快速搜索会显示约20000多个与NLP相关的工作结果。因此,现在是深入了解NLP世界的好时机,如果你想知道NLP工程师需要什么技能,请查看我们在下面准备的列表。
目录
成为NLP工程师所需的技能
15个NLP项目理念付诸实践
- 初学者感兴趣的NLP项目
- NLP项目理念#1情绪分析
- NLP项目创意#2对话机器人:聊天机器人
- NLP项目理念#3主题识别
- NLP项目理念#4总结作家
- NLP项目创意#5语法自校正
- NLP项目创意#6垃圾邮件分类
- NLP项目创意#7文本处理和分类
- 简单NLP项目
- NLP项目创意#1句子自动完成
- NLP项目创意#2市场篮子分析
- NLP项目理念#3自动问题标记系统
- NLP项目理念#4简历分析系统
- NLP开源项目
- NLP项目理念#1识别相似文本
- NLP项目创意#2不当评论扫描仪
- 高级NLP项目
- NLP项目理念#1语言标识符
- NLP项目创意#2图片标题生成器
- NLP项目创意#3家庭作业助手
常见问题解答
成为NLP工程师所需的技能
- 熟悉在至少一种流行的深度学习框架(PyTorch、Tensorflow等)中实现NLP技术。
- 熟悉常用的机器学习和深度学习算法。
- 对用于量化NLP算法结果的统计技术有很强的理解。
- 拥有AWS、Azure等基于云的平台的实践经验。
- 过去使用NLP算法的经验被认为是一个额外的优势。
- 利用自然语言数据得出有见地的结论,从而促进业务增长。
- 设计基于NLP的应用程序以解决客户需求。
20多个NLP项目理念付诸实践
除了上述技能外,招聘人员还经常要求申请人展示他们的项目组合。他们这样做是为了了解你在实现NLP算法方面有多好,以及你能在多大程度上为他们的业务扩展它们。为了帮助您克服这一挑战,我们准备了一份内容丰富的自然语言处理项目列表。为了让您的浏览无忧,我们将这些项目分为以下四类:
- 初学者感兴趣的NLP项目
- 简单NLP项目
- 高级NLP项目
- GitHub NLP项目
- NLP开源项目
所以,继续吧,选择你的类别,并尝试今天实施你最喜欢的项目!
初学者感兴趣的NLP项目
在我们的NLP项目博客的这一部分,你会发现基于NLP的项目对初学者很友好。如果你是NLP的新手,那么这些面向初学者的NLP完整项目将让你对现实生活中的NLP项目是如何设计和实现的有一个大致的了解。
NLP项目理念#1情绪分析
这是最受欢迎的NLP项目之一,你会在几乎每个NLP研究工程师的桶里找到它。它之所以受欢迎,是因为它被公司广泛用于通过客户反馈来监控对其产品的审查。如果评价大多是正面的,那么这些公司就会认为自己走在了正确的轨道上。而且,如果使用该NLP项目得出的评论大多是负面的,那么该公司可以采取措施改进其产品。
方法:开始设计情绪分析系统的第一步是对文本数据进行EDA。之后,您将不得不使用文本数据处理方法从数据中提取相关信息并去除胡言乱语。下一步是在评论中使用重要的词语来分析评论人的情绪。通过这个项目,您可以了解TF-IDF方法、马尔可夫链概念和特征工程。如果你想用python编程语言为这个项目提供详细的解决方案,请从我们的存储库中查看这个项目:电子商务产品评论-成对排名和情绪分析。
推荐阅读:如何进行文本分类?
NLP项目创意#2对话机器人:聊天机器人
正如我们在本博客开头所提到的,大多数科技公司现在都在利用被称为聊天机器人的对话机器人与客户互动并解决他们的问题。这对客户和公司来说都是节省时间的好方法。引导用户首先输入机器人要求的所有详细信息,只有在需要人工干预的情况下,客户才会与客户服务主管联系。

方法:在这个项目中,您将学习如何使用Python中的NLTK库进行文本分类和文本预处理。您还将探索如何在Python中实现标记化、引理化和词性标记。通过这个项目,您将习惯于像Bag of words、Decision tree和Naive Bayes这样的模型。要查看该项目解决方案的更详细的解决方案,请查看使用python的聊天机器人示例应用程序-使用nltk的文本分类。
NLP项目理念#3主题识别
这是一个非常基本的NLP项目,希望您使用NLP算法来深入理解它们。任务是拥有一个文档,并使用相关算法为文档标记适当的主题。这个NLP项目在现实世界中的一个很好的应用是使用这个NLP来标记客户评论。然后,公司可以使用客户评论的主题来了解哪里应该优先进行改进。

方法:该项目将向您介绍处理文本数据和使用正则表达式的方法。您将了解如何通过TF-IDF和Count vectorizer等方法将文本数据转换为矢量。您还将学习如何使用无监督的机器学习算法将类似的评论分组在一起。要了解更多信息,请阅读使用K均值聚类的主题建模。
NLP项目理念#4自动文本摘要
我们都生活在一个快节奏的世界里,只要点击一个按钮,一切都会得到满足。人们现在希望一切都能以很快的速度提供给他们。这就是为什么短新闻文章比长新闻文章更受欢迎的原因。其中一个例子是Inshorts移动应用程序的流行,该应用程序将冗长的新闻文章总结为60个单词。该应用程序能够通过使用NLP算法进行文本摘要来实现这一点。

方法:这是NLP项目中最重要的想法之一,将帮助您了解如何使用NLP算法根据其重要性对文档中的各种句子进行排名。你必须使用余弦相似度等算法来理解给定文档中哪些句子更相关,并将构成摘要的一部分。
NLP项目创意#5语法自校正
必须使用Microsoft Word进行语法检查的日子已经一去不复返了。如今,大多数文本编辑器都提供语法自动更正选项。甚至还有一个名为Grammarly的网站在作家中逐渐流行起来。该网站不仅提供了纠正给定文本语法错误的选项,还建议如何使其中的句子更具吸引力和吸引力。由于人工智能子域,自然语言处理,所有这些都成为可能。

方法:这个NLP项目将要求你不要使用先进的机器学习算法。你应该用大量的文本数据集来训练你的算法,这些文本数据集因使用正确的语法而广受赞赏。对于训练,你必须执行必要的NLP技术,如引理、删除停止词/无关词、删除标点符号等。
NLP项目创意#6垃圾邮件分类
回想一下那些使用电子邮件的不太好的日子,我们过去收到的垃圾邮件太多,相关的电子邮件很少。我们已经远离了那些日子,不是吗?这一转变的很大一部分归功于NLP。使用NLP算法,电子邮件服务提供系统可以轻松识别垃圾邮件,这有助于用户群通过避免收件箱中不必要的电子邮件来节省时间。

方法:对于这个NLP项目,你必须收集一个电子邮件数据集,然后使用电子邮件的正文来训练你的算法。你可以使用深度学习或机器算法来实现这一点,但作为初学者,我们建议你坚持使用机器学习算法,因为它们相对容易理解
NLP项目创意#7文本处理和分类
对于机器学习的新手来说,理解自然语言处理(NLP)可能相当困难。要顺利理解NLP,必须先尝试简单的项目,然后逐渐提高难度。因此,如果你是一个初学者,正在寻找一个简单的、对初学者友好的NLP项目,我们建议你从这个项目开始。

项目目标:通过处理文本分类的简单问题,从头开始理解NLP。
从项目中学习:你从这个项目中得到的第一个收获将是数据可视化和数据预处理。此外,您还将学习Stopwwords、Tokenization、使用Lancaster Stemmer的Stemming、N-grams模型、TF-IDF。您还将探索逻辑回归模型在文本数据集上的实现。
技术堆栈:语言:Python,库:pandas,seaborn,matplotlib,sklearn,nltk
- 263 次浏览
【NLP】2023年精通NLP 的20个项目及其源代码 --第三部分
视频号
微信公众号
知识星球
使用源代码探索一些简单、有趣和高级的NLP项目想法,您可以练习这些想法以成为一名NLP工程师。
自然语言处理(NLP)是一个跨学科的领域,主要研究使用自然语言的人与计算机之间的交互。随着数字通信的兴起,NLP已经成为现代技术的一个组成部分,使机器能够理解、解释和生成人类语言。这个博客探索了一系列有趣的NLP项目想法,从初学者的简单NLP项目到专业人士的高级NLP项目,这些项目将有助于掌握NLP技能。
根据美国劳工统计局的一份报告,从2020年到2030年,计算机和信息研究科学家的工作岗位预计将增长22%。根据世界经济论坛2020年10月发布的《未来就业报告》,到2025年,人类和机器将在公司当前任务上花费相同的时间。该报告还透露,约40%的员工将被要求重新培训,94%的企业领导人希望员工投资学习新技能。他们对采用云计算以及非人类机器人、人工智能和加密等其他技术表现出了极大的兴趣。
上述所有数字表明,对熟练实施基于人工智能的技术的人的需求将非常大。人工智能的一个子领域是自然语言处理(NLP),它正在科技界逐渐崭露头角。如果你开始回忆起你每天访问的许多网站或移动应用程序都在使用基于NLP的机器人来提供客户支持,你就可以很容易地理解这一事实。
正如我们在2021年机器学习NLP面试问答博客中所揭示的那样,在LinkedIn上快速搜索会显示约20000多个与NLP相关的工作结果。因此,现在是深入了解NLP世界的好时机,如果你想知道NLP工程师需要什么技能,请查看我们在下面准备的列表。
目录
成为NLP工程师所需的技能
15个NLP项目理念付诸实践
- 初学者感兴趣的NLP项目
- NLP项目理念#1情绪分析
- NLP项目创意#2对话机器人:聊天机器人
- NLP项目理念#3主题识别
- NLP项目理念#4总结作家
- NLP项目创意#5语法自校正
- NLP项目创意#6垃圾邮件分类
- NLP项目创意#7文本处理和分类
- 简单NLP项目
- NLP项目创意#1句子自动完成
- NLP项目创意#2市场篮子分析
- NLP项目理念#3自动问题标记系统
- NLP项目理念#4简历分析系统
- NLP开源项目
- NLP项目理念#1识别相似文本
- NLP项目创意#2不当评论扫描仪
- 高级NLP项目
- NLP项目理念#1语言标识符
- NLP项目创意#2图片标题生成器
- NLP项目创意#3家庭作业助手
常见问题解答
高级NLP项目
如果你认为自己是NLP专家,那么下面的项目非常适合你。它们是具有挑战性且同样有趣的项目,将使您能够进一步发展NLP技能。
NLP项目创意#1语言识别
你有多少次去过一个城市,在那里你很兴奋地知道他们会说什么语言?这是很常见的事情。要发现一种语言,你不必总是去那个城市旅行,你甚至可能在浏览互联网上的网站或浏览图书馆的书籍时遇到一份文件,并且可能有好奇心知道它是哪种语言。这个NLP项目只是为了打消你的好奇心。构建您自己的语言标识符。

方法:该项目将使用语言检测数据集来训练机器学习/深度学习算法。此数据集有两列:文本和语言。在执行文本预处理方法后,您可以使用您喜欢的算法来预测给定文本的正确语言目标变量。如果您想用Python实现这个NLP项目,我们建议您使用Pandas、Numpy、Seaborn、NLTK和Matplotlib等库。
NLP项目创意#2图片标题生成器
假设你得到了一个系统,并被要求描述它。这听起来像是一项简单的任务,但对于视力较弱或没有视力的人来说,这将是困难的。这就是为什么设计一个可以为图像提供描述的系统对他们有很大帮助的原因。

方法:这个高级的NLP项目有点复杂,但同样有趣。为了实现这个项目,人们必须对深度学习算法和图像处理技术有一个公平的想法。所以,如果你还没有尝试过,这个项目会激励你去理解它们。你必须首先使用图像处理和深度学习算法来标记图像中的对象,然后通过NLP方法将这些信息转换为相关的句子。
NLP项目创意#3家庭作业助手
这是一个非常酷的NLP项目,适用于所有努力帮助孩子完成作为家庭作业分配给孩子的复杂任务的家长。原因很简单:他们觉得自己太老了,已经忘记了大部分事情。但亲爱的家长们别担心,NLP在这里提供帮助。通过设计一个简单的基于NLP的应用程序,你可以帮助你的孩子完成家庭作业。

方法:对于这个基于NLP的项目,您可以使用NCERT或任何其他免费出版物的pdfs作为您的数据集。您可以实现NLP方法来分析数据,然后使用特定的机器学习或深度学习算法来找到用户提出的问题的答案/相关文本。
GitHub NLP项目
在本节中,您将探索NLP-github项目以及github存储库链接。
NLP项目创意#1分析言语情感
在这个项目中,目标是建立一个使用RAVDESS数据集分析语音中情绪的系统。它将帮助研究人员和开发人员更好地理解人类情绪,并开发能够识别语音中情绪的应用程序。

该项目使用了演员描绘各种情绪的语音记录数据集,包括快乐、悲伤、愤怒和中性。使用EDA工具对数据集进行了清理和分析,并最终确定了数据预处理方法。在实现这些方法后,该项目实现了几种机器学习算法,包括SVM、随机森林、KNN和多层感知器,以根据识别的特征对情绪进行分类。
GitHub Repository: Speech Emotion Analyzer by Mitesh Puthran
NLP Projects Idea #2 Detecting Paraphrases
这个项目非常适合在作业中遇到转述答案的研究人员和教师。你将致力于建立一个系统来识别两个句子是否是相互转述的。这个项目也将对研究人员和开发人员有帮助,因为它将使他们能够建立能够识别转述并改进自然语言处理应用程序的系统。
该项目使用微软研究同义词语料库,其中包含被标记为转述或非转述的成对句子。在通过特征选择方法提取相关特征后,训练包括逻辑回归、支持向量机、决策树和随机森林在内的机器学习算法,根据识别出的特征将句子对分类为转述或非转述。
GitHub Repository: Paraphrase Identification by Wasiahmad
NLP开源项目
本标题列出了NLP项目的列表,您可以轻松处理这些项目,因为它们的数据集是开源的。
NLP项目理念#1识别相似文本
这个NLP项目对于任何一个NLP爱好者来说都是必须的。大约4年前,它作为对Kaggle的挑战而推出。如果你曾经访问过Quora网站,你会注意到,有时网站上的两个问题含义相同,但答案不同。这就产生了一个问题,因为该网站希望读者能够获得与他们的问题相关的所有答案。为了解决这个问题,Quora发起了Quora问题对挑战,并要求数据科学家提供一个解决方案来识别具有类似意图的问题。这个想法是向读者提供所有问题的答案,这些问题看起来可能不同,但意图相同。
方法:在这个NLP项目中,在使用任何机器学习算法之前,你可以使用条形图和直方图来可视化文本数据。你必须使用矢量化技术执行引理、删除停止词、将文本转换为数字。之后,您应该使用各种机器学习算法,如逻辑回归、梯度增强、随机森林和网格搜索CV来调整超参数。要了解这方面的分步解决方案,请单击NLP项目-Kaggle Quora问题对解决方案。
NLP项目创意#2不当评论扫描器
二十一世纪是社交媒体的时代。一方面,许多小企业从中受益,另一方面,它也有黑暗的一面。由于社交媒体,人们开始意识到他们不习惯的想法。虽然很少有人积极对待并努力习惯,但许多人开始把它带向错误的方向,并开始传播有毒的话语。因此,许多社交媒体应用程序采取必要的步骤来删除此类评论以预测其用户,并且他们通过使用NLP技术来做到这一点。
方法:该项目的数据集可在Kaggle上免费获得。您可以使用此数据集将评论分为有毒和无毒两类。对于这个项目,您必须首先使用文本数据预处理技术。之后,您必须执行基本的NLP方法,如将文本数据转换为数字的TF-IDF,然后使用机器学习算法来标记注释
NLP项目理念#3 GPT-3
GPT-3(Generative Pre-trained Transformer 3)是由OpenAI开发的最先进的自然语言处理模型。由于它能够以类似人类的准确性执行各种语言任务,如语言翻译、问答和文本完成,因此受到了极大的关注
GPT-3基于大量数据进行训练,并使用一种名为transformers的深度学习架构来生成连贯自然的语言。其令人印象深刻的性能使其成为各种NLP应用程序的流行工具,包括聊天机器人、语言模型和自动内容生成
NLP项目理念#4 BERT
BERT(来自Transformers的双向编码器表示)是谷歌开发的另一种最先进的自然语言处理模型。BERT是一种基于转换器的神经网络架构,可以针对各种NLP任务进行微调,如问题回答、情绪分析和语言推理。与传统的语言模型不同,BERT使用双向方法来根据句子中的前一个和后一个单词来理解单词的上下文。这使得它在处理复杂的语言任务和理解人类语言的细微差别方面非常有效。由于其卓越的性能,BERT已成为NLP数据科学项目中的一种流行工具,并被用于各种应用,如聊天机器人、机器翻译和内容生成。
NLP项目理念#5Hugging Face
Hugging Face是一个开源软件库,为自然语言处理(NLP)任务提供了一系列工具。该库包括预先训练的模型、模型体系结构和数据集,这些数据集可以很容易地集成到NLP机器学习项目中。拥抱脸因其易用性和多功能性而广受欢迎,它支持一系列NLP任务,包括文本分类、问答和语言翻译。

Hugging Face的一个关键优势是它能够在特定任务上微调预先训练的模型,使其在处理复杂的语言任务时非常有效。此外,图书馆有一个充满活力的贡献者社区,这确保了它不断发展和改进。查看拥抱脸的官方网站了解更多信息。
如果您喜欢阅读这些NLP项目想法,并正在寻找更多的NLP数据科学项目想法和解决方案,请查看我们的存储库:顶级NLP项目|自然语言处理项目。
常见问题解答
什么是NLP任务?
NLP包括多个任务,允许您调查非结构化内容并从中提取信息。这些任务包括词缀、引理、单词嵌入、词性标记、命名实体消歧、命名实体识别、情感分析、语义文本相似性、语言识别、文本总结等。
如何启动NLP项目?
启动一个NLP项目需要遵循五个步骤。
1) 词汇分析——它需要识别和分析单词结构。使用词汇分析将文本分为段落、短语和单词。
2) 句法分析——它检查语法、单词布局和单词关系。
3) 语义分析检索精确且语义正确的语句的所有可选含义。
4) 语篇整合是由之前的句子和之后的句子的含义决定的。
5) 语用分析——它使用一套规则来描述合作对话的特点,以帮助你达到预期的效果。
如何处理NLP项目中的文本数据预处理?
NLP项目中的文本数据预处理包括几个步骤,包括文本规范化、标记化、停止字去除、词干/引理化和矢量化。每一步都有助于将原始文本数据清理并转换为可用于建模和分析的格式。
如何评估NLP模型的性能?
NLP模型的性能可以使用各种指标来评估,如准确性、精确度、召回率、F1分数和混淆矩阵。此外,BLEU、ROUGE和METEOR等领域特定指标可用于机器翻译或摘要等任务。
- 63 次浏览
【NLP】2023年精通NLP 的20个项目及其源代码 --第二部分
视频号
微信公众号
知识星球
使用源代码探索一些简单、有趣和高级的NLP项目想法,您可以练习这些想法以成为一名NLP工程师。
自然语言处理(NLP)是一个跨学科的领域,主要研究使用自然语言的人与计算机之间的交互。随着数字通信的兴起,NLP已经成为现代技术的一个组成部分,使机器能够理解、解释和生成人类语言。这个博客探索了一系列有趣的NLP项目想法,从初学者的简单NLP项目到专业人士的高级NLP项目,这些项目将有助于掌握NLP技能。
根据美国劳工统计局的一份报告,从2020年到2030年,计算机和信息研究科学家的工作岗位预计将增长22%。根据世界经济论坛2020年10月发布的《未来就业报告》,到2025年,人类和机器将在公司当前任务上花费相同的时间。该报告还透露,约40%的员工将被要求重新培训,94%的企业领导人希望员工投资学习新技能。他们对采用云计算以及非人类机器人、人工智能和加密等其他技术表现出了极大的兴趣。
上述所有数字表明,对熟练实施基于人工智能的技术的人的需求将非常大。人工智能的一个子领域是自然语言处理(NLP),它正在科技界逐渐崭露头角。如果你开始回忆起你每天访问的许多网站或移动应用程序都在使用基于NLP的机器人来提供客户支持,你就可以很容易地理解这一事实。
正如我们在2021年机器学习NLP面试问答博客中所揭示的那样,在LinkedIn上快速搜索会显示约20000多个与NLP相关的工作结果。因此,现在是深入了解NLP世界的好时机,如果你想知道NLP工程师需要什么技能,请查看我们在下面准备的列表。
目录
成为NLP工程师所需的技能
15个NLP项目理念付诸实践
- 初学者感兴趣的NLP项目
- NLP项目理念#1情绪分析
- NLP项目创意#2对话机器人:聊天机器人
- NLP项目理念#3主题识别
- NLP项目理念#4总结作家
- NLP项目创意#5语法自校正
- NLP项目创意#6垃圾邮件分类
- NLP项目创意#7文本处理和分类
- 简单NLP项目
- NLP项目创意#1句子自动完成
- NLP项目创意#2市场篮子分析
- NLP项目理念#3自动问题标记系统
- NLP项目理念#4简历分析系统
- NLP开源项目
- NLP项目理念#1识别相似文本
- NLP项目创意#2不当评论扫描仪
- 高级NLP项目
- NLP项目理念#1语言标识符
- NLP项目创意#2图片标题生成器
- NLP项目创意#3家庭作业助手
常见问题解答
简单NLP项目
本标题中有一些关于NLP的示例项目,它们不像上一节中提到的那样毫不费力。对于NLP的初学者来说,他们正在寻找一项具有挑战性的任务来测试自己的技能,这些很酷的NLP项目将是一个很好的起点。此外,您可以将这些NLP项目理念用于研究生班的NLP项目。
NLP项目创意#1句子自动完成
这是一个令人兴奋的NLP项目,您可以将其添加到NLP项目组合中,因为您几乎每天都会观察到它的应用程序。想知道在哪里?很简单,当你在WhatsApp这样的聊天应用程序上输入消息时。我们都发现这些建议可以让我们毫不费力地完成句子。事实证明,使用NLP制作自己的句子自动补全应用程序并没有那么困难。

方法:这是一个完美的NLP项目,用于理解n-gram模型及其在Python中的实现。您可以使用各种深度学习算法,如RNN、LSTM、Bi-LSTM、编码器和解码器来实现该项目。当然,您首先必须使用基本的NLP方法来使您的数据适合上述算法。
NLP项目创意#2市场篮子分析
每次你去超市买杂货时,你一定注意到柜台附近放着一个装有巧克力、糖果等的架子。超市把货架放在那里是一个非常明智和深思熟虑的决定。大多数人在进入超市时都会抵制购买大量不必要的商品,但当他们到达结账柜台时,意志力最终会减弱。放置巧克力的另一个原因可能是人们不得不在柜台前等待,因此,他们在某种程度上被迫看着糖果,并被引诱购买。因此,对商店来说,分析顾客购买的产品/顾客的购物篮以了解如何产生更多利润是很重要的。

方法:这个NLP项目将给你一个关于市场篮子分析如何与公司相关的好主意。您将了解不同的关联规则,并学习apriori和Fp-Growth算法。你还将了解单变量和双变量分析。要了解更多关于这个NLP项目的信息,请参阅使用apriori和fpgrowth算法的市场篮子分析教程示例实现。
NLP项目理念#3自动问题标记系统
专门为用户提供问答的网站,如Quora和Stackoverflow,通常会要求用户在提问时提交五个单词,以便轻松分类。但是,有时用户提供了错误的标签,这使得其他用户很难浏览。因此,他们需要一个自动问题标记系统,该系统可以自动识别用户提交的问题的正确和相关的标签。

方法:为了实现这个项目,你可以使用数据集StackSample。这是一个庞大的数据集,包含三个文件:答案、问题和标签。这三个文件都是CSV格式的,因此您可以使用Python Pandas库来执行必要的分析。这三个文件由列“id”连接,该列对每个问题都是唯一的。每个问题至少有三个标签,您的任务是使用问题和答案来预测这些标签。
NLP项目理念#4简历分析系统
简历解析系统是一种应用程序,它将公司候选人的简历作为输入,并在彻底阅读其中的文本后尝试对其进行分类。如果正确实施该应用程序,可以为人力资源部及其公司节省大量宝贵的时间,并将其用于更高效的工作。

方法:该解析系统可以使用NLP技术和通用的机器学习框架来构建。通过这个NLP项目,您将了解光学字符识别和JSON到Spacy格式的转换。由于简历大多以PDF格式提交,您将了解如何从PDF中提取文本。访问简历解析的源代码,请参阅实现简历解析应用程序。
NLP项目理念#5疾病诊断
如果你正在医疗保健项目中寻找NLP,那么这个项目是必须尝试的。自然语言处理(NLP)可以通过分析自然语言文本中表达的患者的症状和病史来诊断疾病。NLP技术可以帮助识别最相关的症状及其严重程度,以及可能预示某些疾病的潜在风险因素和合并症。
方法:NLP技术可用于从非结构化临床笔记和电子健康记录中提取信息,用于预测和诊断疾病。这些信息包括患者人口统计、病史、药物和治疗计划以及实验室结果。您可以使用NLP来识别文本数据中可能指示特定疾病或状况的特定模式或信号。
- 823 次浏览
【NLP】2023年迄今为止最受欢迎的12个NLP项目
视频号
微信公众号
知识星球
自然语言处理仍然是2022年最热门的话题之一。通过使用GitHub明星(尽管肯定不是唯一的衡量标准)作为受欢迎程度的指标,我们了解了今年迄今为止哪些NLP项目最受欢迎,就像我们最近对机器学习项目所做的那样。这是一个有一些熟悉名字的列表,但也有很多惊喜!
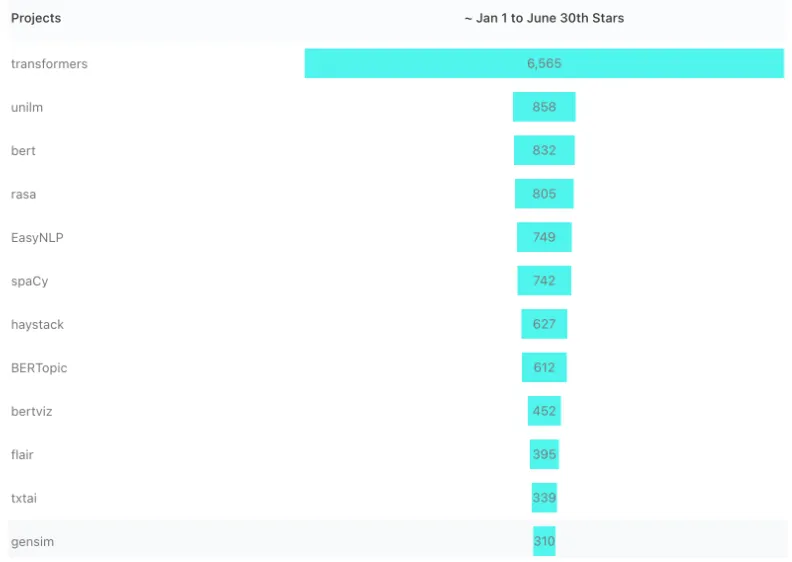
#1:Transformers:
Pytorch、TensorFlow和JAX的最先进机器学习
https://github.com/huggingface/transformers
从业者们喜欢变压器项目,自1月份以来,它有2154颗星,很容易成为我们的首选。该库提供了易于使用的、最先进的模型,这些模型已经扩展到NLP转换器之外,包括PyTorch、JAX和TensorFlow。为使用预训练模型提供统一的API,可以降低人工智能从业者在NLP理解和生成以及计算机视觉和音频任务中的进入门槛。
#2:UniLM
跨任务、语言和模式的大规模自我监督预培训
|https://github.com/microsoft/unilm
UniLM是由李东等人在一篇论文中提出的,并在一些顶级学术会议上发表,包括Neurips(19)、ICML(20)和ACL(21)。UniLM是一个统一的预训练语言模型(UniLM),可以针对自然语言理解和生成任务进行微调。使用三种类型的语言建模任务对模型进行预训练:单向、双向和序列到序列预测。它仍然是一个受欢迎和活跃的项目,最近添加了新的预训练模型,包括BEiT-3、SimLM、DiT、LayoutLMv3和MetaLM等。
#3:BERT
BERT的TensorFlow代码和预训练模型
https://github.com/google-research/bert
在2018年的一篇论文中提出,被引用超过46500次,你可能已经知道BERT及其在NLP革命中的变革作用。BERT的体系结构使其能够理解双向内容,从而在NER、语言理解、问答和其他一些通用NLP任务方面提供最先进的结果。在大规模语料库上预先训练(按照2018年的标准),它在今天的LLM(大型语言模型)空间中仍然非常流行。这并不是最活跃的项目,最近一次更新是在2020年3月,该项目增加了20多个较小的BERT模型。
两个流行的相关项目是BERTopic(Star Gain,612),用于利用BERT和c-TF-IDF创建易于解释的主题,以及BertViz(Star Gain,452),一个交互式工具,用于在诸如BERT、GPT2或T5的Transformer语言模型中可视化注意力。

#4:Rasa
用于对话管理的开源机器学习框架
https://github.com/RasaHQ/rasa
会话助手是NLP的一个顶级用例,Rasa是一个基于python的开源机器学习框架,用于在Twillo、Slack、MS Bot、Facebook Messenger等平台上实现基于文本和语音的助手自动化。Rasa模块包括处理自然语言理解的NLU和处理API并利用LSTM和强化学习等深度学习模型提供文本预测的Core。
#5:EasyNLP
全面易用的NLP工具包
https://github.com/alibaba/EasyNLP
今年6月刚刚发布的这个基于PyTorch的NLP项目很快吸引了一批追随者。EasyNLP最初由阿里巴巴于2021年构建,它提供了易于使用且简洁的命令来调用尖端模型,这些模型涵盖了许多常见NLP现实世界应用程序的NLP算法的广泛集合。它集成了知识提取和少量学习,用于着陆大型预训练模型,以及包括DKPLM和KGBERT在内的各种流行的多模态预训练模型。它是另一个统一的框架,包括模型训练、推理和部署。
#6:spaCy
Python中的工业实力自然语言处理
https://github.com/explosion/spaCy
spaCy是任何python开发人员最喜欢的库,是端到端NLP工作流的首选库。它不仅处理基本的NLP任务,如标记化、解析、NER、标记和文本分类,而且现在还包含了预训练的转换器模型,如BERT。开发ML管道是当今NLP系统的重要组成部分,spaCy训练管道将解析器、标记器、NER和引理器等各种组件编织在一起,以帮助实现NLP工作流的自动化。您可以通过替换、添加和删除各种组件来轻松地定制您的管道,以构建可扩展的生产级NLP。
#7:HayStack
利用预先训练的Transformer模型的开源NLP框架
https://github.com/deepset-ai/haystack
综上所述,Haystack是一个问答框架,根据其Github的描述,“Haystack是一个端到端的框架,使您能够为不同的搜索用例构建强大的、可用于生产的管道。无论您是想执行问答还是语义文档搜索,您都可以在Haystack中使用最先进的NLP模型来提供独特的搜索体验,并允许您的用户使用自然语言进行查询。Haystack以模块化的方式构建,因此您可以结合其他开源项目的最佳技术,如Huggingface的Transformers、Elasticsearch或Milvus。”
#8: Flair
最先进的自然语言处理的一个非常简单的框架
https://github.com/flairNLP/flair
另一个PyTorch和Python库Flair除了构建自己的模型外,还包括文本分类、预训练的名称实体识别和词性标记。Fliar的与众不同之处在于其简单的API,它封装了BERT、ELMo和其他流行的模型。Flair序列标记模型,如NER和词性标记等,现在托管在HuggingFace模型中心上。Flair类似于spaCy,但可能有更好的语言支持,根据使用情况,Flair可能更适合
#9:Txtai
构建人工智能支持的语义搜索应用程序
|https://github.com/neuml/txtai
由于性能的提高,语义搜索正在加快其进入ML工作流的速度,开源项目正在引领这一潮流。Txtai擅长使用向量来识别不同关键字中具有相同含义的搜索结果。基于HuggingFace Transformers和FastAPI的构建不仅提供了模型培训,还提供了工作流和管道,其中包括问题解答、零样本标记、机器翻译、语言检测和文本音频文件等。其他Txtai用例包括文本标记、图像搜索、文章汇总数据和实体提取。

#10:Gensim
面向人类的主题建模
https://github.com/RaRe-Technologies/gensim
近年来,主题建模已经从简单的文档中类似作品的提取和分组扩展到更强大的技术。十多年来,Gensim是NLP项目中最受欢迎的基于Python的无监督主题建模库之一。关键功能包括轻松添加自己的语料库的能力,以及流行主题建模算法的广泛实现,包括在线word2vec深度学习、潜在狄利克雷分配(LDA)、随机投影(RP)、分层狄利克雷过程(HDP)等。由于其许多算法的多核实现,它具有可扩展性,并且可以快速轻松地处理大量文档
#11:NLTK
自然语言工具包
如果不提及目前为3.10版的NLTK,就没有完整的NLP项目和工具包清单。这个扩展的Python工具包还包括支持研究和开发的数据集和教程。NLKT通常与spaCy相比,并被标记为研究工具而非生产工具,它确实提供了对NLP任务的更直接的访问(更少的抽象)。由于其全面的基本NLP任务库,它无疑是初学者的首选库。
#12:nlpaug
NLP的数据扩充
https://github.com/makcedward/nlpaug
由于大型语言模型(LLM)和NLP的其他趋势,数据扩充和合成数据生成正在获得更多的关注,但对于许多人工智能从业者来说,这仍然是相对较新的领域,当然也是新的技术。数据扩充的目标是在不增加数据收集的情况下增加训练数据的多样性。nlpaug是一个python库,可以帮助您为机器学习项目增强NLP。该库包括两个关键模块:增广器,这是增广的基本元素,而Flow是将多个增广器编排在一起的管道。该库可以在几行代码中生成合成数据,并与其他流行的框架(包括Tensorflow、PyTorch和sci kit-learn)配合良好。
在ODSC West 2022了解更多关于NLP和NLP项目的信息
关于这些趋势NLP项目,如何使用NLP,以及如何在业务中实现NLP,有很多东西需要学习。通过今年11月1日至3日参加ODSC West 2022,并查看NLP Track,您可以通过专家主导的讲座、培训课程和研讨会了解如何做到这一切。这里有一些你可以参加的会议。
- Self-Supervised and Unsupervised Learning for Conversational AI and NLP
- Building Modern Search Pipelines with Haystack, Large Language Models, and Hybrid Retrieval
- Bagging to BERT — A Tour of Applied NLP
- Applications of NLP in Retail/E-commerce
- Hyper-productive NLP with Hugging Face Transformers
- The Next Thousand Languages
- Transforming The Retail Industry with Transformers
- 989 次浏览
【NLP】Simple Transformers:命名实体识别规范
视频号
微信公众号
知识星球
命名实体识别规范
在此页面上
使用步骤
命名实体识别的目标是在序列中定位和分类命名实体。命名实体是根据用例选择的预定义类别,例如人名、组织、地点、代码、时间符号、货币价值等。本质上,NER旨在为序列中的每个令牌(通常是一个单词)分配一个类。正因为如此,NER也被称为令牌分类。
在简单变换器中执行命名实体识别的过程没有偏离标准模式。
- 初始化NERModel
- 使用Train_model()训练模型
- 使用eval_mode()评估模型
- 使用predict()对(未标记的)数据进行预测
支持的型号类型
新的模型类型会定期添加到库中。命名实体识别任务当前支持下面给出的模型类型。
| Model | Model code for NERModel |
|---|---|
| ALBERT | albert |
| BERT | bert |
| BERTweet | bertweet |
| BigBird | bigbird |
| CamemBERT | camembert |
| DeBERTa | deberta |
| DeBERTa | deberta |
| DeBERTaV2 | deberta-v2 |
| DistilBERT | distilbert |
| ELECTRA | electra |
| HerBERT | herbert |
| LayoutLM | layoutlm |
| LayoutLMv2 | layoutlmv2 |
| Longformer | longformer |
| MobileBERT | mobilebert |
| MPNet | mpnet |
| RemBERT | rembert |
| RoBERTa | roberta |
| SqueezeBert | squeezebert |
| XLM | xlm |
| XLM-RoBERTa | xlmroberta |
| XLNet | xlnet |
提示:模型代码用于指定Simple Transformers模型中的model_type。
自定义标签
NERModel中使用的默认标签列表来自使用以下标签/标签的CoNLL数据集。
[“O”,“B-MISC”,“I-MISC”、“B-PER”、“I-PER”、”B-ORG“、”I-ORG“、“B-LOC”、”I-LOC“]
然而,命名实体识别是一项非常通用的任务,有许多不同的应用。您很可能希望定义并使用自己的令牌标记/标签。
这可以通过在创建NERModel时将标签列表传递给labels参数来实现。
custom_labels = ["O", "B-SPELL", "I-SPELL", "B-PER", "I-PER", "B-ORG", "I-ORG", "B-PLACE", "I-PLACE"] model = NERModel( "bert", "bert-cased-base", labels=custom_labels )
预测警告
默认情况下,NERModel会在空格上将输入序列拆分为predict()方法,并为拆分序列的每个“单词”分配一个NER标记。这在某些语言(例如中文)中可能是不可取的。为了避免这种情况,可以在调用NERModel.product()方法时指定split_on_space=False。在这种情况下,必须提供一个列表列表作为predict()方法的to_predict输入。内部列表将是属于单个序列的拆分“单词”列表,外部列表是所有序列的列表。
延迟加载Data
在内存中保存大型数据集所需的系统内存可能非常大。在这种情况下,可以延迟从磁盘加载数据,以最大限度地减少内存消耗。
若要启用延迟加载,必须在NEArgs中将lazy_loading标志设置为True。
model_args = NERArgs() model_args.lazy_loading = True
注意:数据必须以CoNLL格式作为文件的路径输入,才能使用延迟加载。请参阅此处以获取正确的格式。
注意:这通常会比较慢,因为功能转换是动态完成的。然而,速度和内存消耗之间的权衡应该是合理的。
提示:有关配置模型以正确读取延迟加载数据文件的信息,请参阅配置NER模型。
- 72 次浏览
【NLP】spacy的嵌入、变换和迁移学习
视频号
微信公众号
知识星球
spaCy支持许多转移和多任务学习工作流,这些工作流通常有助于提高管道的效率或准确性。迁移学习指的是单词向量表和语言模型预训练等技术。这些技术可以用于将原始文本中的知识导入到您的管道中,以便您的模型能够更好地从带注释的示例中进行概括。
你可以从FastText和Gensim等流行工具转换单词向量,或者如果你安装了spacy transformer,你可以加载到任何预先训练的transformer模型中。您也可以通过spacy pretrain命令进行自己的语言模型预训练。您甚至可以在多个组件之间共享转换器或其他上下文嵌入模型,这可以使长管道的效率提高数倍。要使用迁移学习,你需要至少几个带注释的例子来说明你试图预测的内容。否则,您可以尝试使用向量和相似性的“一次性学习”方法。
单词向量和语言模型之间有什么区别?
transformer是一种大型强大的神经网络,可以为您提供更好的准确性,但更难在生产中部署,因为它们需要GPU才能有效运行。单词向量是一种稍老的技术,它可以使模型的准确性得到较小的提高,还可以提供一些额外的功能。
单词向量和上下文语言模型(如transformer)之间的关键区别在于,单词向量建模的是词汇类型,而不是标记。如果你有一个没有上下文的术语列表,像BERT这样的转换器模型并不能真正帮助你。BERT旨在理解上下文中的语言,而上下文并不是你所拥有的。单词向量表将更适合您的任务。然而,如果你在上下文中确实有单词——整个句子或正在运行的文本的段落——单词向量只能提供文本内容的非常粗略的近似值。
单词向量在计算上也是非常高效的,因为它们通过单个索引操作将单词映射到向量。因此,单词向量作为提高神经网络模型准确性的一种方法是有用的,尤其是那些较小或很少或没有经过预训练的模型。在spaCy中,单词向量表仅用作静态特征。spaCy不向预训练的字向量表反向传播梯度。静态向量表通常与较小的学习任务特定嵌入表结合使用。
我什么时候应该将单词向量添加到我的模型中?
单词向量与大多数转换器模型不兼容,但如果你正在训练另一种类型的NLP网络,那么在你的模型中添加单词向量几乎总是值得的。除了提高你的最终准确性外,单词向量通常会使实验更加一致,因为你达到的准确性对网络如何随机初始化不太敏感。随机机会导致的高方差会显著减慢你的进度,因为你需要进行许多实验来从噪声中过滤信号。
单词向量功能需要在训练前启用,并且在运行时也需要提供相同的单词向量表。一旦模型已经训练好,就无法添加单词向量特征,而且通常无法在不造成显著性能损失的情况下用另一个单词向量表替换一个单词矢量表。
共享嵌入层
spaCy允许您在多个组件之间共享单个转换器或其他令牌到向量(“tok2vec”)嵌入层。您甚至可以更新共享层,执行多任务学习。在组件之间重用tok2vec层可以使管道运行得更快,并产生更小的模型。然而,它可能会降低管道的模块化程度,并使交换组件或重新培训管道部件变得更加困难。多任务学习会影响你的准确性(无论是积极的还是消极的),并且可能需要重新调整你的超参数。

| SHARED | INDEPENDENT |
|---|---|
| smaller: models only need to include a single copy of the embeddings | larger: models need to include the embeddings for each component |
| faster: embed the documents once for your whole pipeline | slower: rerun the embedding for each component |
| less composable: all components require the same embedding component in the pipeline | modular: components can be moved and swapped freely |
通过在管道起点附近添加一个transformer或tok2vec组件,您可以在多个组件之间共享单个transformer或其他tok2vec模型。管道中稍后的组件可以通过在其模型中包含像Tok2VecListener这样的侦听器层来“连接”到它。
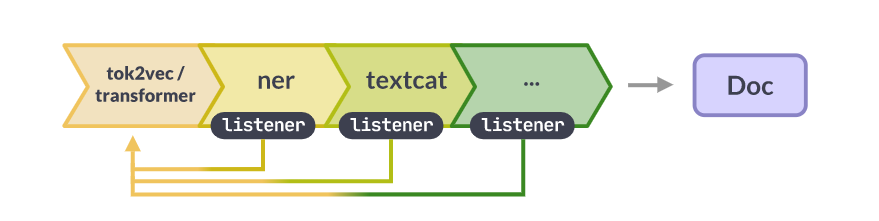
在培训开始时,Tok2Vec组件将获取对管道其余部分中相关侦听器层的引用。当它处理一批文档时,它会将其预测转发给侦听器,从而允许侦听器在最终调用预测时重用这些预测。类似的机制用于将梯度从侦听器传递回模型。Transformer组件和TransformerListener层对Transformer模型执行相同的操作,但Transformer组件也会将Transformer输出保存到Doc._中。trf_data扩展属性,使您能够在管道运行完成后访问它们。
示例:共享配置与独立配置
配置系统允许您表达共享嵌入层和独立嵌入层的模型配置。共享设置使用一个具有Tok2Vec架构的Tok2Vec组件。所有其他组件,如实体识别器,都使用Tok2VecListener层作为其模型的tok2vec参数,该参数连接到tok2vec组件模型。
SHARED [components.tok2vec] factory = "tok2vec" [components.tok2vec.model] @architectures = "spacy.Tok2Vec.v2" [components.tok2vec.model.embed] @architectures = "spacy.MultiHashEmbed.v2" [components.tok2vec.model.encode] @architectures = "spacy.MaxoutWindowEncoder.v2" [components.ner] factory = "ner" [components.ner.model] @architectures = "spacy.TransitionBasedParser.v1" [components.ner.model.tok2vec] @architectures = "spacy.Tok2VecListener.v1"
在独立设置中,实体识别器组件定义自己的Tok2Vec实例。其他组件也会这样做。这使得它们完全独立,并且不需要在管道中存在上游Tok2Vec组件。
INDEPENDENT [components.ner] factory = "ner" [components.ner.model] @architectures = "spacy.TransitionBasedParser.v1" [components.ner.model.tok2vec] @architectures = "spacy.Tok2Vec.v2" [components.ner.model.tok2vec.embed] @architectures = "spacy.MultiHashEmbed.v2" [components.ner.model.tok2vec.encode] @architectures = "spacy.MaxoutWindowEncoder.v2"
使用变型器模型
Transformers是一个神经网络体系结构家族,用于计算文档中标记的密集、上下文敏感的表示。然后,管道中的下游模型可以使用这些表示作为输入特征来改进其预测。您可以将多个组件连接到单个转换器模型,其中任何或所有组件都会向转换器提供反馈,以根据您的任务对其进行微调。spaCy的transformer支持与PyTorch和HuggingFace transformer库互操作,使您可以访问数千个预训练的管道模型。变压器模型有很多很好的指南,但出于实际目的,您可以简单地将其视为替代品,让您获得更高的准确性,以换取更高的培训和运行成本。
设置和安装
系统要求
我们建议使用至少具有10GB内存的NVIDIA GPU,以便与变压器型号配合使用。确保你的GPU驱动程序是最新的,并且你已经安装了CUDA v9+。
具体要求取决于变压器型号。在没有GPU的情况下训练基于转换器的模型对于大多数实际目的来说太慢了。
配置一台新机器需要下载大约5GB的数据:3GB CUDA运行时、800MB PyTorch、400MB CuPy、500MB权重、200MB spaCy和依赖项。
一旦安装了CUDA,我们建议您按照包管理器和CUDA版本的PyTorch安装指南安装PyTorch。如果您跳过这一步,pip将在下面作为依赖项安装PyTorch,但它可能找不到适合您安装的最佳版本。
EXAMPLE: INSTALL PYTORCH 1.11.0 FOR CUDA 11.3 WITH PIP# See: https://pytorch.org/get-started/locally/pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
接下来,安装spaCy和您的CUDA版本和变压器的额外功能。CUDA extra(例如,cuda102、cuda113)安装了cupy的正确版本,它与numpy一样,但适用于GPU。如果CUDA运行时安装在非标准位置,则可能还需要设置CUDA_PATH环境变量。综合来看,如果您在/opt/nvidia/CUDA中安装了CUDA 11.3,您将运行:
INSTALLATION WITH CUDA
export CUDA_PATH="/opt/nvidia/cuda" pip install -U spacy[cuda113,transformers]
pip install -U spacy[cuda113,transformers]对于变压器v4.0.0+和需要PencePiece的型号(例如,ALBERT、CamemBERT、XLNet、Marian和T5),安装以下附加依赖项:
INSTALL SENTENCEPIECE
pip install transformers[sentencepiece]
运行时使用
Transformer模型可以用作其他类型神经网络的替代品,因此您的spaCy管道可以以用户完全不可见的方式包含它们。用户将以标准方式下载、加载和使用该模型,就像任何其他spaCy管道一样。您也可以通过Transformer管道组件使用它们,而不是直接将Transformer用作子网络。
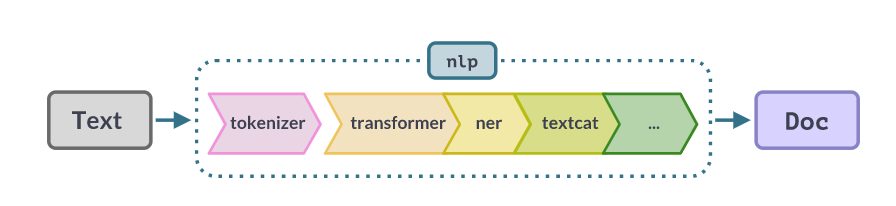
Transformer组件设置文档。trf_data扩展属性,使您可以在运行时访问transformer输出。spaCy提供的经过训练的基于变压器的管道在_trf上结束,例如en_core_web_trf。
python -m spacy download en_core_web_trf
EXAMPLE
import spacy
from thinc.api import set_gpu_allocator, require_gpu
# Use the GPU, with memory allocations directed via PyTorch.
# This prevents out-of-memory errors that would otherwise occur from competing
# memory pools.
set_gpu_allocator("pytorch")
require_gpu(0)
nlp = spacy.load("en_core_web_trf")
for doc in nlp.pipe(["some text", "some other text"]):
tokvecs = doc._.trf_data.tensors[-1]您还可以通过指定自定义的set_extra_annotations函数来自定义Transformer组件在文档上设置注释的方式。这个回调将与整个批次的原始输入和输出数据以及一批Doc对象一起调用,允许您实现所需的任何内容。使用一批Doc对象和包含该批转换器数据的FullTransformerBatch调用注释setter。
def custom_annotation_setter(docs, trf_data):
doc_data = list(trf_data.doc_data)
for doc, data in zip(docs, doc_data):
doc._.custom_attr = data
nlp = spacy.load("en_core_web_trf")
nlp.get_pipe("transformer").set_extra_annotations = custom_annotation_setter
doc = nlp("This is a text")
assert isinstance(doc._.custom_attr, TransformerData)
print(doc._.custom_attr.tensors)培训使用情况
建议的培训工作流程是使用spaCy的配置系统,通常通过spaCy-train命令。训练配置在一个地方定义了所有组件设置和超参数,并允许您通过引用创建函数(包括您自己注册的函数)来描述对象树。有关如何开始训练自己的模特的详细信息,请查看训练快速入门。
config.cfg中的[components]部分描述了管道组件和用于构建它们的设置,包括它们的模型实现。以下是Transformer组件的配置片段,以及匹配的Python代码。在这种情况下,[components.transformer]块描述了变压器组件:
CONFIG.CFG
[components.transformer]
factory = "transformer"
max_batch_items = 4096
[components.transformer.model]
@architectures = "spacy-transformers.TransformerModel.v3"
name = "bert-base-cased"
tokenizer_config = {"use_fast": true}
[components.transformer.model.get_spans]
@span_getters = "spacy-transformers.doc_spans.v1"
[components.transformer.set_extra_annotations]
@annotation_setters = "spacy-transformers.null_annotation_setter.v1"[components.transformer.model]块描述传递给transformer组件的模型参数。它是一个将被传递到组件中的ThincModel对象。在这里,它引用了在体系结构注册表中注册的函数spacy-transformers.TransformerModel.v3。如果块中的键以@开头,那么它将被解析为一个函数,所有其他设置都将作为参数传递给该函数。在本例中,使用name、tokenizer_config和get_span。
get_Span是一个函数,它接受一批Doc对象,并返回可能重叠的Span对象列表,由转换器处理。有几个内置功能可用,例如,处理整个文档或单个句子。解析配置后,将创建函数并将其作为参数传递到模型中。
name值是任何HuggingFace模型的名称,该模型将在第一次使用时自动下载。您也可以使用本地文件路径。有关完整的详细信息,请参阅TransformerModel文档。
支持各种各样的PyTorch模型,但有些可能不起作用。如果一个模型似乎不起作用,请随意打开一个问题。此外,请注意,spaCy中加载的Transformers只能用于张量,并且预训练的任务专用头或文本生成功能不能用作transformer管道组件的一部分。
请记住,用于训练的config.cfg不应包含丢失的值,并且需要定义所有设置。你不希望任何隐藏的默认值悄悄出现并改变你的结果!spaCy会告诉您是否缺少设置,您可以运行spaCy-init-fill-config来自动填充所有默认值。
自定义设置
要更改任何设置,您可以编辑config.cfg并重新运行培训。要更改任何函数,如span getter,您可以替换引用函数的名称,例如@span_getters=“spacytransformers.sent_spans.v1”来处理语句。您也可以使用span_getters注册表注册自己的函数。例如,以下自定义函数返回句子边界后的Span对象,除非一个句子后面有一定数量的标记,在这种情况下,最多返回max_length标记的子内容。
import spacy_transformers
@spacy_transformers.registry.span_getters("custom_sent_spans")
def configure_custom_sent_spans(max_length: int):
def get_custom_sent_spans(docs):
spans = []
for doc in docs:
spans.append([])
for sent in doc.sents:
start = 0
end = max_length
while end <= len(sent):
spans[-1].append(sent[start:end])
start += max_length
end += max_length
if start < len(sent):
spans[-1].append(sent[start:len(sent)])
return spans
return get_custom_sent_spans要在训练期间解决配置问题,spaCy需要了解您的自定义函数。您可以通过--code参数使其可用,该参数可以指向Python文件。有关使用自定义代码进行培训的更多详细信息,请参阅培训文档。
python -m spacy train ./config.cfg --code ./code.py
自定义模型实现
Transformer组件希望传入一个Thinc Model对象作为其模型参数。您并不局限于spacy transformers提供的实现——唯一的要求是您注册的函数必须返回Model[List[Doc],FullTransformerBatch]类型的对象:也就是说,一个Thinc模型,它接受Doc对象的列表,并返回带有transformer数据的FullTransformerBatch对象。
同样的想法也适用于为下游组件提供动力的任务模型。spaCy的大多数内置模型创建函数都支持tok2vec参数,该参数应该是model[List[Doc]、List[Floats2d]]类型的Thinc层。这就是我们将使用TransformerListener层插入transformer模型的地方,该层偷偷地委托给transformer管道组件。
CONFIG.CFG (EXCERPT) [components.ner] factory = "ner" [nlp.pipeline.ner.model] @architectures = "spacy.TransitionBasedParser.v1" state_type = "ner" extra_state_tokens = false hidden_width = 128 maxout_pieces = 3 use_upper = false [nlp.pipeline.ner.model.tok2vec] @architectures = "spacy-transformers.TransformerListener.v1" grad_factor = 1.0 [nlp.pipeline.ner.model.tok2vec.pooling] @layers = "reduce_mean.v1"
TransformerListener层需要一个池化层作为参数池,该池化层的类型需要为Model[Ragged,Floats2d]。该层确定如何根据标记对齐的零个或多个源行计算每个spaCy标记的向量。这里我们使用reduce_ma均值层,它对单词行进行平均。我们可以使用reduce_max,或者您自己编写的自定义函数。
你可以让多个组件都监听同一个转换器模型,并将所有渐变返回给它。默认情况下,所有渐变都将被同等加权。您可以通过grad_factor设置来控制这一点,该设置允许您重新调整来自不同侦听器的渐变。例如,设置grad_factor=0将禁用其中一个侦听器的渐变,而grad_factol=2.0将它们乘以2。这类似于每个组件都有一个自定义的学习率。您还可以提供一个时间表,让您在训练开始时冻结共享参数,而不是常数。
静态矢量
如果你的管道包括一个单词向量表,你将能够在Doc、Span、Token和Lexeme对象上使用.ssimilarity()方法。您还可以使用.vvector属性访问向量,或者直接使用Vocab对象查找一个或多个向量。带有单词向量的管道也可以使用向量作为统计模型的特征,这可以提高组件的准确性。
spaCy中的单词向量是“静态的”,因为它们不是统计模型的学习参数,spaCy本身也没有任何学习单词向量表的算法。您可以使用floret、Gensim、FastText或GloVe等工具来训练单词向量表,或者下载现有的预训练向量。init vectors命令允许您转换向量以与spaCy一起使用,并将为您提供一个可以在训练配置中加载或引用的目录。
📖词向量与相似性
有关将单词向量加载到spaCy、使用它们进行相似性以及通过截断和修剪向量来提高单词向量覆盖率的更多详细信息,请参阅单词向量和相似性的使用指南。
在模型中使用词向量
许多神经网络模型能够使用词向量表作为附加特征,这有时会显著提高准确性。spaCy的内置嵌入层MultiHashEmbed可以配置为使用include_static_vvectors标志使用单词向量表。
[tagger.model.tok2vec.embed] @architectures = "spacy.MultiHashEmbed.v2" width = 128 attrs = ["LOWER","PREFIX","SUFFIX","SHAPE"] rows = [5000,2500,2500,2500] include_static_vectors = true
💡它是如何工作的
配置系统将在体系结构注册表中查找字符串“spacy.MultiHashEmbed.v2”,并使用块中的其余参数调用返回的对象。这将导致对MultiHashEmbed函数的调用,该函数将返回一个具有类型签名model[List[Doc],List[Floats2d]]的Thinc模型对象。因为嵌入层采用Doc对象列表作为输入,所以不需要存储矢量表的副本。向量将通过Doc.vocab.vectors属性从传入的Doc对象中检索。该过程的这一部分由StaticVectors层处理。
创建自定义嵌入层
MultiHashEmbed层是spaCy推荐的为神经网络模型构建初始单词表示的策略,但您也可以实现自己的策略。您可以将任何函数注册为字符串名称,然后在配置中引用该函数(有关更多详细信息,请参阅培训文档)。要尝试这个方法,您可以将以下小示例保存到一个新的Python文件中:
from spacy.ml.staticvectors import StaticVectors
from spacy.util import registry
print("I was imported!")
@registry.architectures("my_example.MyEmbedding.v1")
def MyEmbedding(output_width: int) -> Model[List[Doc], List[Floats2d]]:
print("I was called!")
return StaticVectors(nO=output_width)如果使用--code参数将文件的路径传递给spacy train命令,则文件将被导入,这意味着注册该函数的装饰器将运行。您的函数现在与spaCy的任何内置函数处于同等地位,因此您可以将其放入,而不是使用相同输入和输出签名的任何其他模型。例如,您可以在tagger模型中使用它,如下所示:
[tagger.model.tok2vec.embed] @architectures = "my_example.MyEmbedding.v1" output_width = 128
既然你有了一个连接到网络中的自定义函数,你就可以开始实现你感兴趣的逻辑了。例如,假设你想尝试一种相对简单的嵌入策略,它利用静态单词向量,但通过求和将它们与一个较小的学习嵌入表相结合。
from thinc.api import add, chain, remap_ids, Embed
from spacy.ml.staticvectors import StaticVectors
from spacy.ml.featureextractor import FeatureExtractor
from spacy.util import registry
@registry.architectures("my_example.MyEmbedding.v1")
def MyCustomVectors(
output_width: int,
vector_width: int,
embed_rows: int,
key2row: Dict[int, int]
) -> Model[List[Doc], List[Floats2d]]:
return add(
StaticVectors(nO=output_width),
chain(
FeatureExtractor(["ORTH"]),
remap_ids(key2row),
Embed(nO=output_width, nV=embed_rows)
)
)预训练
spacy pretrain命令允许您使用原始文本中的信息初始化模型。如果不进行预训练,组件的模型通常会被随机初始化。预训练背后的想法很简单:随机可能不是最优的,所以如果我们有一些文本可以学习,我们可能会找到一种方法让模型有一个更好的开始。
预训练使用与常规训练相同的config.cfg文件,这有助于保持设置和超参数的一致性。额外的[预训练]部分有几个配置子部分,这些子部分在训练块中很熟悉:[预训练.批处理程序]、[预训练..优化器]和[预训练.\语料库]都以相同的方式工作,期望使用相同类型的对象,尽管预训练时你的语料库不需要任何注释,所以你通常会使用不同的阅读器,例如JsonlCorpus。
原始文本格式
原始文本可以用spaCy的二进制.spaCy格式提供,该格式由序列化的Doc对象组成,也可以用JSONL(换行符分隔的JSON)提供,每个条目都有一个键“text”。这样可以逐行读取数据,同时还可以在文本中包含换行符。
{"text": "Can I ask where you work now and what you do, and if you enjoy it?"}
{"text": "They may just pull out of the Seattle market completely, at least until they have autonomous vehicles."}
您也可以使用自己的自定义语料库加载程序。
您可以通过在init-config或init-fill-config上设置--pretraining标志,将[pretraining]块添加到您的配置中:
python -m spacy init fill-config config.cfg config_pretrain.cfg --pretraining
然后,您可以使用更新的配置运行spacy预训练,并传入可选的配置覆盖,如原始文本文件的路径:
python -m spacy pretrain config_pretrain.cfg ./output --paths.raw_text text.jsonl
以下默认值用于[pretraining]块,并在使用--pretraining运行init-config或init-fill-config时合并到现有配置中。如果需要,您可以配置设置和超参数或更改目标。
[paths]
raw_text = null
[pretraining]
max_epochs = 1000
dropout = 0.2
n_save_every = null
n_save_epoch = null
component = "tok2vec"
layer = ""
corpus = "corpora.pretrain"
[pretraining.batcher]
@batchers = "spacy.batch_by_words.v1"
size = 3000
discard_oversize = false
tolerance = 0.2
get_length = null
[pretraining.objective]
@architectures = "spacy.PretrainCharacters.v1"
maxout_pieces = 3
hidden_size = 300
n_characters = 4
[pretraining.optimizer]
@optimizers = "Adam.v1"
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
L2 = 0.01
grad_clip = 1.0
use_averages = true
eps = 1e-8
learn_rate = 0.001
[corpora]
[corpora.pretrain]
@readers = "spacy.JsonlCorpus.v1"
path = ${paths.raw_text}
min_length = 5
max_length = 500
limit = 0预培训的工作原理
spacy预训练的影响各不相同,但如果你没有使用transformer模型,并且你的训练数据相对较少(例如,少于5000句),通常值得尝试。一个很好的经验法则是,预训练通常会给你带来与在模型中使用单词向量类似的准确性提高。如果单词向量让你的错误减少了10%,那么用spaCy进行预训练可能会让你再减少10%,总共减少20%的错误。
spacy pretrain命令将在您的一个组件中获取一个特定的子网络,并添加额外的层来为临时任务构建一个网络,该任务迫使模型学习一些关于句子结构和单词共现统计的信息。
预训练生成一个二进制权重文件,可以在训练开始时使用配置选项initialize.init _tok2vec重新加载。权重文件指定一组初始权重。然后训练照常进行。
一次只能从管道中预训练一个子网络,并且子网络必须类型为Model[List[Doc],List[Floats2d]](即它必须是“tok2vec”层)。最常见的工作流程是使用Tok2Vec组件为管道的几个组件创建一个共享的令牌到向量层,并对其整个模型应用预训练。
配置预训练
spacy pretraining命令是使用配置文件的[preptraining]部分配置的。组件和层设置告诉spaCy如何找到要预训练的子网络。图层设置应该是空字符串(使用整个模型)或节点引用。spaCy的大多数内置模型架构都有一个名为“tok2vec”的引用,它将引用正确的层。
# 1. Use the whole model of the "tok2vec" component [pretraining] component = "tok2vec" layer = "" # 2. Pretrain the "tok2vec" node of the "textcat" component [pretraining] component = "textcat" layer = "tok2vec"
将预培训与培训联系起来
为了从预训练中受益,您的训练步骤需要知道如何使用从预训练步骤中学习到的权重初始化其tok2vec分量。您可以通过将initialize.init_tok2vec设置为预训练中要使用的.bin文件的文件名来完成此操作。
一个运行了5个时期的预训练步骤,输出路径为pretrain/,例如,从pretrain/model0.bin到pretrain/mmodel4.bin。要使用最终输出,您可以在配置文件中填写此值:
CONFIG.CFG
[paths]
init_tok2vec = "pretrain/model4.bin"
[initialize]
init_tok2vec = ${paths.init_tok2vec}spacy预训练的输出与将进入initialize.vectors的预打包静态字向量的数据格式不同。预训练输出由tok2vec组件在现有管道中应该开始的权重组成,因此它进入initializ.init_tok2vec。
培训前目标
字符目标
[pretraining.objective]
@architectures = "spacy.PretrainCharacters.v1"
maxout_pieces = 3
hidden_size = 300
n_characters = 4
矢量目标
[pretraining.objective]
@architectures = "spacy.PretrainVectors.v1"
maxout_pieces = 3
hidden_size = 300
loss = "cosine"
有两个预训练目标可用,这两个目标都是完形填空任务Devlin等人(2018)为BERT引入的变体。可以通过[预训练.目标]配置块定义和配置目标。
PretrainCharacters:“characters”目标要求模型预测单词的前导和尾随UTF-8字节数。例如,设置n_characters=2,模型将尝试预测单词的前两个和最后两个字符。
预训练向量:“向量”目标要求模型从静态嵌入表中预测单词的向量。这需要对单词向量模型进行训练和加载。矢量目标可以优化余弦或L2损失。我们通常发现余弦损失表现更好。
这些预训练目标使用了一种技巧,我们称之为具有近似输出的语言建模(LMAO)。这个技巧的动机是预测一个确切的单词ID会带来很多偶然的复杂性。您需要一个大的输出层,即使这样,词汇表也太大,这会导致标记化方案与实际单词边界不一致。在训练结束时,输出层无论如何都会被丢弃:我们只想要一个任务,迫使网络对单词共现统计数据进行建模。预测前导字符和尾随字符可以充分做到这一点,因为如果准确地预测首字母和尾随字符,则可以高精度地恢复准确的单词序列。以向量为目标,预训练使用通过GloVe或Word2vec等算法学习的嵌入空间,使模型能够专注于我们实际关心的上下文建模。
- 248 次浏览
【NLP】前9个开源NLP项目
视频号
微信公众号
知识星球
ChatGPT
ChatGPT是一种人工智能技术,在科技界迅速流行起来。这项技术使用自然语言处理和深度学习算法来生成对用户查询的响应。ChatGPT代表基于聊天的生成预训练转换器。它是一个自然语言处理系统,提供与用户的自动对话。
ChatGPT彻底改变了人们与机器通信的方式。这项技术可以以多种方式使用,从提供客户服务到提供教育资源。它在客户服务中特别有用,因为它可以快速准确地响应用户的询问。它还可以用于提供教育资源,例如提供问题的答案或提供有关特定主题的信息。ChatGPT背后的技术相当复杂,但最终的结果是一个可以以自然和对话的方式对用户做出响应的系统。
这项技术基于预先训练的人工智能系统,该系统使用深度学习算法生成响应。该系统在大型对话数据集上进行训练,然后被赋予特定任务,例如响应用户查询。
以下是ChatGPT可以为您做的事情-https://medium.com/mlearning-ai/hatsay-goodbye-to-boring-chats-welcome-…
ChatGPT游乐场-https://chat.openai.com/
GPT-3(Generative Pre-trained Transformer 3)
GPT-3(Generative Pre-trained Transformer 3)是一个由OpenAI开发的语言生成模型。它是迄今为止最大、功能最强大的语言模型之一,具有1750亿个参数的容量。
GPT-3是在大量文本数据集上训练的,可以生成连贯一致的仿人文本。它被用于生成文章、故事、诗歌,甚至代码,并因其生成现实和令人信服的文本的能力而在媒体中受到了大量关注。
GPT-3基于Transformer架构,该架构使用自注意机制来处理输入序列并生成输出序列。它可以处理长程依赖关系,并在长序列上生成连贯的文本。GPT-3是一个开源库,预训练的模型可以针对各种自然语言处理任务进行微调。
GPT-3游乐场-https://gpt3demo.com/apps/openai-gpt-3-playground
BERT (Bidirectional Encoder Representations of Transformers)
BERT(Bidirectional Encoder Representations of Transformers)是谷歌开发的一种语言表示模型。它是在一个大型文本数据集上训练的,可以针对各种自然语言处理任务进行微调,如问答和语言翻译。
BERT基于Transformer架构,该架构使用自注意机制来处理输入序列并生成输出序列。BERT的一个关键特征是它能够考虑给定输入序列中每个单词左右两侧的上下文,这使它能够更好地理解单词相对于周围单词的含义。这使得它非常适合于需要上下文理解的任务,例如问答和填空。
BERT在许多NLP基准上取得了最先进的成果,并在NLP社区中被广泛采用。它作为一个开源库提供,并且可以针对各种NLP任务对预先训练的模型进行微调。
BERT论文:https://arxiv.org/abs/1810.04805
🤗拥抱脸BERT-https://huggingface.co/docs/transformers/model_doc/bert
Hugging Face
Hugging Face是一个开源的自然语言处理(NLP)库,为训练和部署NLP模型提供了工具。它有大量预先训练的模型,可以针对各种NLP任务进行微调,如语言翻译、问答和文本分类。
拥抱脸的设计是用户友好和易于使用,重点是可用性和灵活性。它提供了一系列工具和库,可以轻松地训练和部署NLP模型,以及用于数据预处理和可视化的工具。
拥抱脸还有一个庞大而活跃的开发者和用户社区,它不断更新新功能和改进。它是NLP研究人员和从业者的热门选择,他们正在寻找一个易于使用且功能强大的库来开发和部署NLP模型。
🤗拥抱的脸:https://huggingface.co/
AllenNLP
AllenNLP是一个开源的自然语言处理(NLP)研究库,由艾伦人工智能研究所开发。它包含用于开发和评估NLP模型的各种工具和资源,包括用于训练、评估和部署模型的库,以及用于数据预处理和可视化的工具。
AllenNLP的一个关键特性是其对可用性和灵活性的关注。它提供了一系列预构建的模型和模块,这些模型和模块可以很容易地组合和定制,用于各种NLP任务,还提供了一套用于构建和评估自定义模型的工具和库。
AllenNLP被NLP社区的研究人员和从业者用来开发和评估新的NLP模型和技术,它也被用于许多商业应用。它由艾伦人工智能研究所积极维护和开发,拥有一个庞大而活跃的用户和开发者社区。
AllenNLP:https://allenai.org/allennlp
spaCy
spaCy是一个开源的自然语言处理(NLP)库,用于Python中的高级NLP任务。它为标记化、词性标记、依赖解析和命名实体识别等任务提供了一系列工具和库。
spaCy的一个关键特性是它注重性能和效率。它的设计速度快、内存高效,并且可以快速处理大量文本。它还收集了大量预先训练的模型,可以针对各种NLP任务进行微调,并提供了一系列用于训练和评估自定义模型的工具。
spaCy在NLP社区中被广泛使用,是NLP任务(如信息提取和文本分类)的热门选择。它得到了积极的开发和维护,拥有一个庞大而活跃的用户和开发人员社区。
spaCy公司:https://spacy.io/
NLTK
自然语言工具包(NLTK)是Python中一个流行的用于自然语言处理(NLP)的开源库。它为标记化、词性标记、词干和情感分析等任务提供了广泛的工具和资源。
NLTK是作为一种教学和研究工具开发的,在学术界广泛用于NLP任务。它的设计易于使用,非常适合NLP任务,如语言建模、文本分类和信息提取。
NLTK是一个综合库,为NLP任务提供了广泛的工具和资源,包括大型数据集、预先训练的模型以及一系列用于文本预处理和可视化的实用程序。它得到了积极的开发和维护,拥有一个庞大而活跃的用户和开发人员社区。
NLTK公司:https://www.nltk.org/
斯坦福大学核心NLP
斯坦福核心NLP是斯坦福大学开发的一个开源自然语言处理(NLP)库。它为标记化、词性标记、依赖解析和命名实体识别等任务提供了一系列工具和资源。
斯坦福CoreNLP的一个关键特征是它能够处理多种语言。它支持开箱即用的多种语言,包括英语、西班牙语、中文和阿拉伯语,并且可以轻松扩展以支持其他语言。
斯坦福核心NLP在学术界和工业界得到了广泛的应用,是信息提取和文本分类等NLP任务的热门选择。它得到了积极的开发和维护,拥有一个庞大而活跃的用户和开发人员社区。
斯坦福德核心NLP:https://stanfordnlp.github.io/CoreNLP/
Flair
Flair是一个用于创建自然语言处理(NLP)模型的Python工具包。它为标记化、词性标记和命名实体识别等任务提供了各种工具和资源,还为各种NLP应用程序提供了许多预训练模型。
Flair的一个显著特点是它强调简单性和可用性。它还包括各种使训练和评估NLP模型变得简单的类。
Flair经常用于NLP任务的学术和商业应用,如文本分类和信息提取。它得到了积极的开发和维护,拥有庞大而活跃的用户和开发人员社区。
- 769 次浏览
【自然语言】NLP、NLU和NLG之间有什么区别?
视频号
微信公众号
知识星球
目录
- NLP、NLU和NLG简介
- 什么是自然语言处理?
- 什么是自然语言理解?
- 什么是自然语言生成?
- NLP、NLU和NLG之间的区别是什么?
- 自然语言的未来是什么?
- 结论
NLP、NLU和NLG简介
NLU和NLP的需求随着技术和研究的进步而增加,计算机可以分析和执行各种数据的任务。但当我们谈论人类语言时,它改变了整个场景,因为它是混乱和模糊的。处理人类语言而不是统计数据是很复杂的。系统必须理解内容、情感、目的,才能理解人类的语言。但了解人类语言对于了解客户成功经营的意图至关重要。自然语言理解和自然语言处理在理解人类语言中起着至关重要的作用。有时人们在处理自然语言时可以互换使用这些术语。他们的目标是处理人类语言,但他们不同。
到2025年,认知系统“接触”的分析数据量将增长100倍至1.4 ZB来源:NLP的演变及其对人工智能的影响
图灵测试:计算机和语言从1950年开始融合在一起。随着时间的推移,他们正在努力制造更智能的机器。它从简单的语言输入开始到训练模型,现在再到复杂的语言输入。语言和人工智能的一个著名例子是“图灵测试”。它是由艾伦·图灵于1950年开发的,用于检查机器是否足够智能。
什么是自然语言处理?
它是人工智能的一个子集。它处理大量的人类语言数据。这是系统和人类之间的一个端到端的过程。它包含了从理解信息到在交互时做出决策的整个系统。比如阅读信息,分解信息,理解信息,并做出回应的决定。从历史上看,自然语言理解最常见的任务是:
- 符号化
- 正在分析
- 信息提取
- 相似性
- 语音识别
- 语音生成和其他。
在现实生活中,NLP可用于:
- 聊天机器人
- 文本摘要
- 文本分类
- 词性标注
- 填鸭
- 文本挖掘
- 机器翻译
- 本体论群体
- 语言建模及其他
让我们举一个例子来理解它。在聊天机器人中,如果用户问:“我可以打排球吗?”。然后,NLP使用机器学习和人工智能算法来读取数据、找到关键词、做出决策和做出回应。它会根据各种特征做出决定,比如是否下雨?有没有操场?其他配件是否可用。然后它就播放与否向用户做出响应。它包含了从接受输入到提供输出的整个系统。
什么是自然语言理解?
它有助于机器理解数据。它用于解释数据,以理解要相应处理的数据的含义。它通过理解文本的上下文、语义、语法、意图和情感来解决这个问题。为此,使用了各种规则、技术和模型。它找到了该文本背后的目标。理解语言有三个语言层次。
- 语法:它理解句子和短语。它检查文本的语法和句法。
- 语义:它检查文本的含义。
- 语用学:它理解上下文以了解文本试图达到的目的。
它必须理解在结构化和正确的格式中存在缺陷的非结构化文本。它将文本转换为机器可读的格式。它用于语义短语、语义分析、对话代理等。为了更清楚起见,让我们举一个例子。如果你问:“今天怎么样?”。现在,如果系统回答“今天是2020年10月1日,星期四”,该怎么办?系统是否为您提供了正确的答案?不,因为在这里,用户想了解天气。因此,我们用它来学习文本中一些错误的正确含义。
它是人工智能的一个子集技术,用于缩小计算机和人类之间的通信差距。点击探索自然语言处理的演变和未来
什么是自然语言生成?
NLG是自然语言中产生有意义句子的过程。它以每秒数千页的高速,以人类易于理解的方式解释结构化数据。以下列出了一些NLG模型:
马尔可夫链
递归神经网络
长短期记忆
Transfomrer
NLP、NLU和NLG之间的区别是什么?
两者之间有一个细微的差别。这需要考虑:
| NLU | NLP | NLG |
| It is a narrow concept. | It is a wider concept. | It is a narrow concept. |
| If we only talk about an understanding text, then it is enough. | But if we want more than understanding, such as decision making, then it comes into play. | It generates a human-like manner text based on the structured data. |
| It is a subset of NLP. | It is a combination of it and NLG for conversational Artificial Intelligence problems. | It is a subset of NLP. |
| It is not necessarily that what is written or said is meant to be the same. There can be flaws and mistakes. It makes sure that it will infer correct intent and meaning even data is spoken and written with some errors. It is the ability to understand the text. | But, if we talk about NLP, it is about how the machine processes the given data. Such as make decisions, take actions, and respond to the system. It contains the whole End to End process. Every time it doesn't need to contain it. | It generates structured data, but it is not necessarily that the generated text is easy to understand for humans. Thus NLG makes sure that it will be human-understandable. |
| It reads data and converts it to structured data. | It converts unstructured data to structured data. | NLG writes structured data. |
NLP和NLU在一起
它是NLP的一个子集。它可以在NLP中使用它来实现对数据的类似人类的理解。它有助于更好地实现它。这是许多过程中的第一步。它共同努力,给人们一种类似人类的体验。处理和理解语言不仅仅是训练数据集。不止于此。它包含了数据科学、语言技术、计算机科学等多个领域。

在这里,我们将讨论日常的人工智能问题,以了解它们如何协同工作,并在与机器交互时改变人类的整个体验。如果用户想要一个简单的聊天机器人,他们可以使用它和机器学习技术创建它。但是,如果他们要开发一个智能的上下文助手,他们需要NLU。为了创建一个类似人类的聊天机器人或自然声音对话人工智能系统,他们将NLP和NLU结合使用。他们专注于能够通过图灵测试的系统。这个系统可以快速而轻松地与人互动。这个系统可以通过结合所有语言学和处理方面来实现。
NLP和NLU之间的相关性
有一个假设在推动它,它谈到了句法结构,并说明了语言分析的目的。据说,将语言中的语法句子与非语法句子分开,以检查序列的语法结构。句法分析可以用于各种过程。有多种方法可以对齐和分组单词以检查语法规则:
- 词缀化:它通过将单词组合成一个单一的形式来减少单词的屈折形式,并使分析变得容易。
- 填词:它通过将单词剪切成词根形式来减少屈折词。
- 词素分割:将单词分割成词素。
- 分词:它将连续的书面文本划分为不同的有意义的单元。
- 语法分析:通过基本语法分析单词或句子。
- 词性标注:分析并识别每个单词的词性。
- 断句:它检测并放置连续文本中的句子边界。
句法分析并不总是将句子或文本的验证联系起来。正确或不正确的语法是不够的。还需要考虑其他因素。另一件事是语义分析。它被用来解释单词的含义。我们有一些语义分析技术:
- 命名实体识别(NER):它识别文本并将其分类到预定义的组中。
- 词义消歧:它识别句子中使用的单词的意义。它根据上下文赋予单词意义。
- 自然语言生成:它将结构化数据转换为语言。
关于语义和句法分析,还有一件事是非常重要的。它被称为语用分析。它有助于理解目标或文本想要实现的目标。情绪分析有助于实现这一目标。
机器以书面或口头的方式理解和解释人类语言的能力。点击浏览,自然语言处理应用和技术
自然语言的未来是什么?
为了准备一个通过图灵测试的人类语言人工智能系统,开发人员专注于一些基本术语。如果我们用数学方法表示整个端到端过程,它包含以下术语:

NLU和NLG的结合给出了一个NLP系统。
- 自然语言处理:它理解文本的含义。
- NLU(自然语言理解):决策和行动等整个过程都是由它来完成的。
- NLG(自然语言生成):它从系统生成的结构化数据中生成人类语言文本以进行响应。
为了更好地理解它们的用途,举一个实际的例子,你有一个网站,你必须每天发布股票市场的报告。为了每天完成这项任务,你必须研究和收集文本,创建报告,并将其发布在网站上。这既无聊又耗时。但是,如果NLP、NLU和NLG在这里工作。它和NLP可以理解股票市场的文本并将其分解,然后NLG将生成一个故事发布在网站上。因此,它可以像人一样工作,并让用户处理其他任务。
结论
NLP和NLU是设计能够轻松理解人类语言的机器的重要术语,无论它是否包含一些常见的缺陷。这两个术语之间有一个很小的区别,这对开发人员来说非常重要,因为如果他们想创建一台可以通过给人类提供一个类似人类的环境来与人类交互的机器,因为在正确的地方使用正确的技术对于在为自然语言操作创建的系统中取得成功至关重要。
- 244 次浏览
【自然语言处理】10 个最好的 NLP 项目来提升你的投资组合

在这篇博客中,我们将讨论 10 个最佳 NLP 项目,您可以创建这些项目并使您的作品集在面试官眼中更具吸引力。
有没有想过 Alexa 如何理解你在说什么,或者它如何聪明地理解你的话?自然语言处理就是答案!!
自然语言处理 (NLP) 是指计算机科学的一个分支——更具体地说,是人工智能或 AI 的一个分支——它关注的是让计算机能够以与人类几乎相同的方式理解文本和口语单词的能力。
NLP 确实是一个令人兴奋的领域,因为它的广泛应用让我们的生活更轻松。有意或无意地,您每天都在与 NLP 应用程序进行交互。
您必须使用过 Google Assistant 或 Amazon Alexa。你是否?
是的,两者都是 NLP 应用程序。您可能在许多网站上遇到过聊天机器人,它们会根据您的问题自动回复您。此外,当您写电子邮件时,如果有语法错误,系统会自动纠正您的语法错误。
看起来很有趣,对吧?这就是自然语言处理为我们的生活带来的影响,让生活变得更轻松。
即使他/她不懂英语,也请与任何人分享此博客!是的,你没有看错。不懂英语的人可以阅读此博客。如何? NLP 再次来救援。语言翻译也是 NLP 的一个惊人应用。您也可以使用 NLP 创建这些令人惊叹的应用程序。开发现实世界的项目是磨练技能和获得实践经验的最佳方式。我敢打赌,你会非常喜欢从事这些项目。
你在等什么?让我们开始讨论您也可以构建的最佳 NLP 项目!
1.文本摘要

当您打开报纸时,您是否开始阅读每篇新文章?我猜不会。您首先阅读新闻文章的摘要以获得概述。但是,当今编写的大多数摘要都是手动编写的。
如果我告诉你,如果你只提供新闻文章,AI 可以为你写摘要怎么办?听起来是不是很迷人?是的,文本摘要是您可以在 NLP 中解决的最有趣的问题之一。当您有大量文本时,它特别有用。在这种情况下以有效的方式编写摘要非常耗时。
它在媒体、娱乐行业、学术等各个领域都有应用。你听说过 Inshorts 应用程序吗?该应用程序使用 NLP 来获取新闻文章的摘要,从而节省金钱和成本。所以,你可以看到 NLP 不仅是节省时间,而且是通过削减成本来增加公司的利润。
有各种库和算法可以创建文本摘要器。其中之一是 Gensim 库,它使用 Textrank 算法来创建摘要。 GPT 和 Transformers 等高级技术也非常擅长文本摘要任务。
您可以阅读以下研究论文,以更好地了解文本摘要。
在这里免费阅读
2.抄袭检查器
随着互联网的出现,每天都有大量的信息被共享。 由于每个人都可以轻松访问所有信息和内容,因此许多人利用这一点并简单地复制其他人的内容,从而导致剽窃增加。 这是一个关键问题,尤其是在学术研究领域。 许多人在没有得到应有的承认的情况下窃取他人的想法和工作。
由于内容庞大,实际上不可能手动检查抄袭。 这就是为什么我们需要一些可以检查内容是否抄袭的方法或技术。 NLP 在这项任务上非常出色。
潜在语义分析 (LSA) 是一种 NLP 技术,可以有效地检查抄袭。
3. 对话机器人
这可能是现实世界中应用最多的 NLP 应用程序。 你会发现聊天机器人现在在各个领域都在与人类互动。 您有时可能会向 Google 助理询问天气情况。 或者在 ed-tech 网站上查询过任何课程。 这些只不过是 NLP 的惊人应用而已。 聊天机器人可以根据用户提出的问题回复用户。
最好的部分是它们并不难创建。 有各种可用的框架可让您轻松构建智能聊天机器人。
其他一些可用的框架是:
- Google Dialogflow
- Amazon Lex
- Microsoft Luis
- IBM Watson
- RASA
https://www.letthedataconfess.com/blog/ts-events/chat-bot-development-f…
4. MCQ Generation
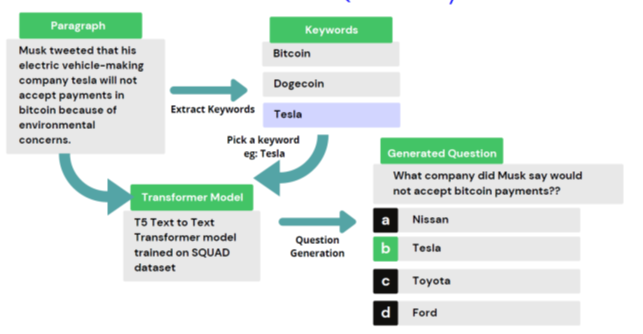
提供文本并获取一组 MCQ。 等等,什么! 可能吗? 是的,自然语言处理能够做到这一点。 如此诱人的应用程序!
想象一下一位想要参加 MCQ 考试的老师。 教师只需提供文本就可以轻松获得一组 MCQ。 这样可以节省大量时间和人工繁重的工作。
为了完成这个任务,我们可以使用 BERT 抽取式汇总器或 Transformer 模型。 可以使用 Python 关键字提取器库来提取关键字。
这是一本很好的读物,可以增强您对该项目的了解。
在这里免费阅读
5. 语法校正

想写一篇文章、一封信或任何其他文件,但不确定自己的语法技能?语法错误太多会在读者面前留下不好的印象。好吧,别担心。我敢打赌,您将能够在语法上没有错误地编写文档。感谢NLP领域的进步。
您在编写电子邮件时会注意到它会自动建议正确的语法并更正拼写。这使我们的工作变得如此方便,以至于我们不再需要担心语法错误。
Grammarly 就是这样一种应用程序,它可以自动更正拼写并建议我们使用适当的语法。它甚至可以作为 chrome 扩展程序下载。
您应该使用大量文本数据集来训练您的算法,这些文本数据集因使用正确的语法而广受赞誉。对于训练,您必须执行必要的 NLP 技术,例如词形还原、去除停用词/不相关词、去除标点符号等。
6. 语言翻译

语言翻译是 NLP 的一个惊人应用。 您可以将任何语言的任何文本翻译成您选择的语言,例如将法语翻译成英语。 我们不一定需要向精通您不懂的语言的人寻求帮助。 您只需输入文本,NLP 模型就会为您翻译。
它用于 Facebook 和 Instagram 等许多应用程序。 Facebook 和 Instagram 也会在语言翻译后显示文本。 解释用其他语言编写的文本非常方便。 最好的部分是这些模型的错误率非常低。
NLP 模型首先确定要转换的语言。 您只需要使用包含文本及其语言的庞大数据集来训练模型。 您也可以为此项目获取现成的数据集。
下载数据集
7.简历解析申请
NLP 几乎没有任何领域未触及。 它还扩大了在人力资源领域的影响力。 公司收到过多的简历以获取工作简介。 手动从每份简历中提取所需信息非常耗时,有时效率也很低。
简历解析器是一种 NLP 模型,可以立即提取技能、大学、学位、姓名、电话、职务、电子邮件、其他社交媒体链接、国籍等信息,而不管其结构如何。 现在网上有很多简历解析器。 好吧,您也可以创建自己的。
正则表达式(或正则表达式)可以帮助从简历中提取所需的部分。 然后可以使用 BERT 命名实体识别 (BERT NER) 来创建模型。
8. 图片说明生成器
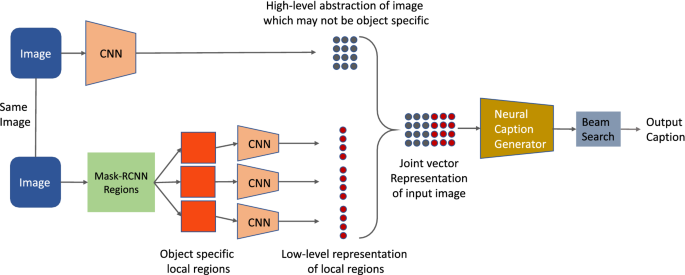
是人工智能领域的热门研究领域。 它为图像生成文本描述。 这也需要计算机视觉技术的帮助来理解图像。

您可以查看上图以了解模型生成字幕的准确程度。 这样可以节省大量时间,否则手动操作会给公司带来成本。
CNN 或 Inception、VGG16、ResNet50、GoogleNet 等迁移学习模型可用于对图像进行分类。 并以 RNN/LSTM 作为语言模型对文本序列进行编码。 编码器可以将图像的编码形式和文本标题的编码形式结合起来,并将其提供给解码器。
9. 有毒评论分类
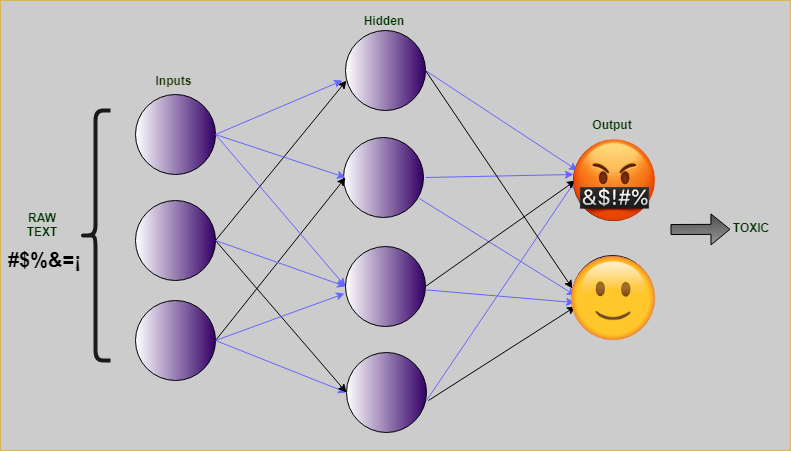
社交媒体时代的必备应用!
很多时候,您可能已经看到名人和板球运动员在社交媒体上遇到很多批评。 虽然建设性的批评是好的,但发布辱骂性的评论会降低一个人的士气,也会对幼儿产生负面影响,尤其是使用社交媒体。 这就是为什么解决这个问题至关重要。 NLP 模型可以检测有毒评论。 然后可以自动删除这些评论,以免被很多人看到。
这个项目的数据可以在这里找到。
数据集
10. 文本生成
您想自动生成文本吗?好吧,您可以创建自己的文本生成工具。
它可以使用 RNN/LSTM 技术自动生成文本并完成句子。
它的一个惊人应用是由 OpenAI 和 GitHub 共同开发的 GitHub Copilot。它接受了 GitHub 上数百万个公共存储库的代码训练。它非常强大,可以自动生成您想要的代码。 NLP 能够理解程序员想要什么,它会自动完成代码。例如,如果您希望代码生成用于检查数字是否为素数的代码,只需将其写在评论中,GitHub Copilot 就会为您提供代码。那不是很强大吗?
结论
因此,我们讨论了您可以创建以脱颖而出的前 10 个 NLP 项目。您将在这些项目上获得大量实践经验。你会对自己的 NLP 技能充满信心。这些项目也可以在现实生活中使用。
NLP 现在可能在每个行业都具有广泛的重要性。这项技术也节省了大量时间和金钱。有什么比使用技术节省公司成本和增加利润更好的了。
https://www.letthedataconfess.com/blog/ts-events/chat-bot-development-f…
原文:https://medium.com/@letthedataconfess/10-best-nlp-projects-to-boost-you…
- 141 次浏览
【自然语言处理】使用 OCR 和 NLP 提取文档信息
本文仅考虑我和我的团队解决业务问题的方法之一。 它不是一个非常技术性的帖子,所以我不会详细介绍具体的编码细节,但我会指出一些有用的参考资料和库。
在数据处理成为一个越来越庞大的主题的世界中,能够快速有效地提取信息可以成为一项重要的业务优势。 信息提取的最大挑战之一是来源和文档格式的多样性。
例如,在金融领域,有大量的扫描文件,如工资单、银行对账单、贷款协议等。 这些文档可以在没有一致结构的情况下呈现信息,因此提取重要信息可能很耗时。
出于这个原因,我们利用涉及计算机视觉和 NLP 技术的不同解决方案来开发一种能够识别问题:答案格式中的信息并自动提取它的方法。 例如,如果有一个员工姓名为“姓名:Juan”的文档字段,我们的模型需要能够将该信息提取为 {Question: “Name”, Answer: “Juan”}
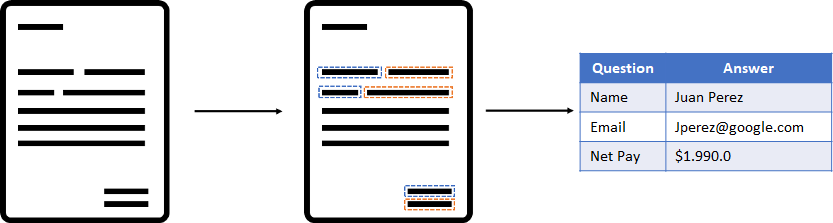
在本文中,我想展示我们为实现模型而执行的不同步骤:
- 构建数据集
- 微调预训练的文本和布局模型
- 定义问题:答案关系算法
构建数据集
为了测试我们的方法,我们编译了一组从互联网下载的 32 张工资单图像。 工资单是一份文件,其中包含有关工资的详细清单和特定工作的详细信息。 它们具有员工姓名、日期和支付金额等值。 该模型使用在互联网上找到的 32 种不同的工资单文件(jpg 格式)进行训练。
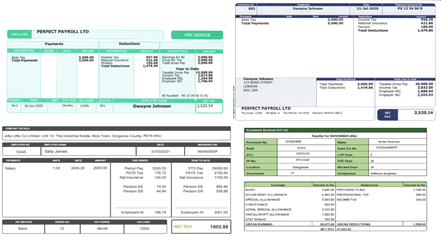
光学字符识别(OCR)
建立模型的第一步是能够以计算机可以理解的格式提取每张工资单的内容。 为此,我们使用 OCR(光学字符识别)。 OCR 软件允许将扫描文档或图片中的数据捕获为文本。 有许多 OCR 工具。 对于这个项目,我们使用了 Cloud Vision API。 此工具接收图像并返回文本元素列表及其与图像的相对坐标(通常称为“边界框”)。
标签工作室(Label-Studio)
提取所有字段和边界框后,需要对每个字段进行标注,为此我们使用了一个名为 Label-Studio 的注释工具,您可以在此处查看文档和网站,OCR 返回的每个框都被手动分类为 以下选项:标题、问题、答案。

微调布局LM(LayoutLM)模型
类 BERT 模型已被证明是各种 NLP 任务中最先进的技术,并且在尝试使用文档布局和视觉信息提取文本信息时它们并不落后。
LayoutLM 是一种简单但有效的文本和布局预训练方法,用于文档图像理解和信息提取任务。您可以在此处查看更多信息:
LayoutLM:用于文档图像理解的文本和布局的预训练https://arxiv.org/abs/1912.13318
近年来,预训练技术已在各种 NLP 任务中得到成功验证。尽管…
arxiv.org
我们的模型将是使用我们已经描述的数据集的该模型的微调版本,您可以在 hugginface.co 存储库中找到预训练的模型。
多模式 的文档 AI(文本+布局/格式+图像)预训练 Microsoft Document AI | GitHub LayoutLMv2 是一个…
https://huggingface.co/microsoft/layoutlmv2-base-uncased
模型的输入是:
- 标记 id:由 OCR 工具检测并由模型标记器嵌入的文本
- Box:包含文本项在框形上的相对坐标的列表(x0,y0,width,height)
- 标签:(“标题”,“问题”,“答案”)
结果
训练模型后,我们得到以下分数:
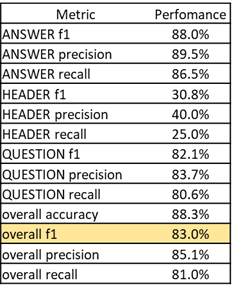
我们得到了 83% 的总体 f1 分数,这可能会更好,但考虑到我们训练数据集的大小,结果还不错,我们可以看到标题标签的性能较低,这可能是由于注释不佳或 只是缺少常规标题。
LayoutLM模型分类
定义问题:答案关系算法
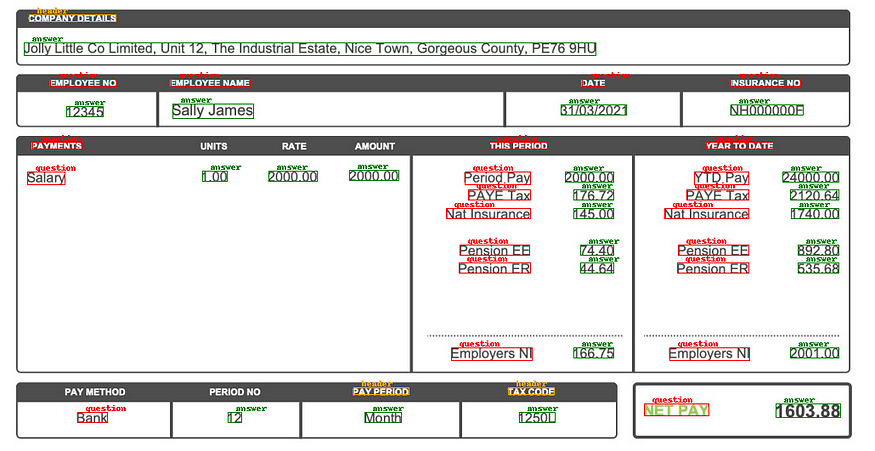
一旦定义了每个框的类别,下一个任务就是将每个问题与其各自的答案相关联,例如,在上图中,有一个问题:“员工编号”。 和答案:“12345”,但模型还没有连接这两个项目的东西。
为了连接这些项目,我们采用迭代方法,遍历答案,然后根据框之间的距离及其垂直/水平对齐的组合,我们对问题和答案之间的所有潜在关系进行排序。

运行算法找到键值项后,我们得到下表:

结论
我们能够使用 OCR 从扫描的文档中提取文本,然后使用 LayoutLM 模型对其进行标记,并将其转换为结构化格式。 总的来说,结果是可以接受的,如果我们使用更大的训练集,性能可能会更好,文档的质量和 OCR 工具的性能也会影响最终结果。
接下来要尝试什么
- 获取更大的数据集
- 尝试不同的 OCR 工具
- 改进键值算法
原文:https://medium.com/@simsagues/document-information-extraction-using-ocr…
- 318 次浏览
【自然语言处理】使用自然语言处理的智能文档分析
什么是智能文档分析?
智能文档分析(IDA)是指使用自然语言处理(NLP)和机器学习从非结构化数据(文本文档、社交媒体帖子、邮件、图像等)中获得洞察。由于80%的企业数据是非结构化的,因此IDA可以跨行业和业务功能提供切实的好处,例如改善遵从性和风险管理、提高内部运营效率和增强业务流程。
在本博客中,我将描述IDA中使用的主要NLP技术,并提供各种业务用例的示例。我还将讨论启动第一个IDA项目时的一些关键考虑事项。

智能文档分析技术
以下是7种常见的IDA技术。将提供示例用例来解释每种技术。
1. 命名实体识别
命名实体识别识别文本中提到的命名实体,并将它们分类到预定义的类别中,如人名、组织、位置、时间表达式、货币值等。有一系列的方法来执行命名实体识别:
- 开箱即用的实体识别——大多数NLP包或服务都包括用于识别实体的预先训练好的机器学习模型。这使得识别关键实体类型(如人名、组织和位置)变得非常容易,只需一个简单的API调用,而不需要训练机器学习模型。
- 机器学习的实体识别——开箱即用的实体很方便,但通常是通用的,在许多情况下,需要识别其他的实体类型。例如,在招聘环境中处理文档时,我们想要识别工作头衔和技能。在零售环境中,我们希望识别产品名称。
- 确定性实体识别——如果你想要识别的实体是有限的并且是预定义的,那么确定性方法将比训练一个机器学习模型更容易更准确。在这种方法中,提供了实体的字典;然后,实体识别器将在文本中识别字典条目的任何实例。例如,字典可以包含公司所有产品的列表。将字典方法与机器学习相结合也是可能的。字典用于为机器学习模型注释训练数据,然后机器学习模型学习识别不在字典中的实体实例。确定性实体识别通常不支持开箱即用的NLP包或服务。一些支持这种确定性方法的NLP包使用本体而不是字典。本体为实体定义关系和相关术语,这使实体识别器能够使用文档的上下文来消除模糊实体之间的歧义。
- 基于模式的实体识别——如果实体类型可以由正则表达式定义,那么可以使用正则表达式匹配来识别它们。例如,可以使用正则表达式标识产品代码或引用引用。英国国家保险号码的简化正则表达式为[A- z]{2}[0-9]{6}[A- z](2个大写字母,后面跟着6个数字,后面跟着1个大写字母)。
命名实体识别是本博客中讨论的许多其他rda技术的关键预处理技术。其他命名为实体识别用例的例子包括:
- 在财务说明书中指明公司和基金的名称。在这个例子中,公司名称可以使用开箱即用的模型来识别,而基金名称可以使用机器学习模型、确定性方法或两者的结合来识别。
- 标识语料库中文档之间的引用。在本例中,可以使用正则表达式(一种基于模式的实体识别方法)标识引用。
2. 情绪分析
情绪分析识别和分类文本中表达的意见,如新闻报道,社交媒体内容,评论等。在最简单的形式下,它可以将情绪分为积极和消极两类;但它也可以量化情绪(如-1到+1),或将其分类在一个更细粒度的水平(如非常负面、负面、中性、积极、非常积极)。
情感分析,像许多NLP技术一样,需要能够处理语言的复杂性。例如:
- 否定——像“不”和“决不”这样的词会改变所使用的词的感情。例如,“这部电影没有扣人心弦的情节,也没有可爱的角色。”
- 层次情感可以在不同程度上表达出来。例如,在“我喜欢它”、“我爱它”和“我绝对喜欢它”中,正能量在不断增加,但是“我真的很喜欢它”在这一进程中处于什么位置呢?
- 冲突-文本可能包括积极和消极的情绪。例如,“他们的第一张专辑很棒,但他们的第二张专辑是垃圾”应该被认为是积极的,消极的,或中性的?
- 含蓄——在句子“如果交货晚了,我会生气的”中,负面情绪是建立在一些没有发生,也可能不会发生的事情上的。在“They used to be good”这句话中,表达的是对过去的肯定情绪,但可能隐含的是对现在的否定情绪。
- 俚语——俚语的意思通常与传统意义相反。例如,“sick”这个词会有非常不同的含义,这取决于它使用的语境(“这家餐厅的食物让我恶心”vs.“那个新推出的视频游戏真恶心!”)或者作者的人口结构。
- 实体级——实体级情感分析通过在实体级而不是在文档或语句级考虑情感,提供了对情感更细粒度的理解。这将解决在“冲突”场景中看到的模糊性(“他们的第一张专辑很棒,但他们的第二张专辑是垃圾。”)。它通过给第一个专辑(第一个实体)分配积极的情绪,而给第二个专辑(第二个实体)分配消极的情绪来做到这一点。
情绪分析经常被用来分析与公司或其竞争对手有关的社交媒体帖子。它可以是一种强有力的工具:
- 跟踪一段时间内的情绪趋势
- 分析事件的影响(例如产品发布或重新设计)
- 识别关键影响者
- 提供危机的早期预警
3.文本相似度
文本相似性计算句子、段落和文档之间的相似性。
为了计算两个条目之间的相似度,必须首先将文本转换为表示文本的n维向量。这个向量可能包含文档中的关键字和实体,或者内容中表示的主题的表示。向量和文档之间的相似性可以通过余弦相似度等技术来测量。
文本相似性可用于检测文档或文档部分中的重复项和近似重复项。这里有两个例子:
- 通过比较论文内容的相似性来检查学术论文是否抄袭。
- 匹配求职者和工作,反之亦然。但在这种情况下,它关注的是关键特征(职位、技能等)之间的相似性,而不是严格的近似重复检测。对于这种类型的用例,语义相似性是有用的,因为考虑两种技能(如人工智能和机器学习)或职位(如数据科学家和数据架构师)可能是相关的,即使它们不完全相同,这是很重要的。
4. 文本分类
文本分类用于根据文本的内容将文本项分配给一个或多个类别。它有两个维度:
- 分类的数量——最简单的分类形式是二值分类,即只有两种可能的类别可以将一个项分类到其中。这方面的一个例子是垃圾邮件过滤,其中电子邮件分类为垃圾邮件或非垃圾邮件。多类或多项分类有两个以上的类,其中一个项可被分类到其中。
- 标签数量-单标签分类将一个项目精确地分类为一个类别,而多标签分类可以将一个项目分类为多个类别。将新闻文章分类到多个主题区域就是多标签分类的一个例子。
一般来说,类和标签的数量越少,预期的准确性就越高。
文本分类将使用文档中的单词、实体和短语来预测类。它还可以考虑其他特性,比如文档中包含的任何标题、元数据或图像。
文本分类的一个示例用例是文档(如邮件或电子邮件)的自动路由。文本分类用于确定文档应该发送到的队列,以便由适当的专家团队处理,从而节省时间和资源(例如,法律、市场营销、金融等)。
文本分类也可应用于文件的各部分(例如句子或段落),例如,用以确定信件的哪些部分提出了投诉,以及投诉的类型。
5. 信息提取
信息抽取从非结构化文本中提取结构化信息。
一个示例用例是标识信件的发送者。识别的主要手段是发送人的参考资料、身份证明或会员编号。如果没有找到,那么回退可能是发件人的姓名、邮政编码和出生日期。每一条信息都可以通过命名实体识别来识别,但是这本身是不够的,因为可能会找到多个实例。信息提取依赖于实体识别。对实体上下文的理解有助于确定哪个是正确的答案。例如,信件可能包含多个日期和邮政编码,因此有必要确定哪个是发件人的出生日期,哪个是发件人的邮政编码。
6. 关系抽取
关系提取提取两个或多个实体之间的语义关系。与信息抽取类似,关系抽取依赖于命名实体识别,但区别在于它特别关注实体之间的关系类型。关系提取可用于执行信息提取。
一些NLP包和服务提供了开箱即用的模型来提取关系,比如“雇员的”、“结婚的”和“出生的地点”。与命名实体识别一样,自定义关系类型可以通过训练特定的机器学习模型来提取。
关系提取可用于处理非结构化文档,以确定具体的关系,然后将这些关系用于填充知识图。
例如,该技术可以通过处理非结构化医学文档来提取疾病、症状、药物等之间的关系。
7. 综述
摘要缩短了文本,以创建一个连贯的主要观点的摘要。文本摘要有两种不同的方法:
- 基于提取的摘要在不修改原文的情况下提取句子或短语。这种方法生成由文档中最重要的N个句子组成的摘要。
- 基于摘要的摘要使用自然语言生成来改写和压缩文档。与基于提取的方法相比,这种方法更加复杂和实验性。
文本摘要可用于使人们能够快速地消化大量文档的内容,而不需要完全阅读它们。这方面的一个例子是新闻feed或科学出版物,它们经常生成大量的文档。
智能文档分析任务的复杂性
机器学习在非结构化文本上要比在结构化数据上复杂得多,因此在分析文本文档方面要达到或超过人类水平的性能要困难得多。
1. 语言的复杂性
由于语言所包含的变化、歧义、语境和关系,人类要花很多年才能理解语言。我们可以通过许多方法来表达相同的思想。我们根据作者和读者的不同使用不同的风格,并选择使用同义词来增加兴趣和避免重复。rda技术必须能够理解不同的样式、歧义和单词关系,从而获得准确的洞察。
IDA需要理解通用语言和特定领域的术语。处理特定领域术语的一种方法是使用自定义字典或构建用于实体提取、关系提取等的自定义机器学习模型。
解决将通用语言和特定领域术语结合在一起的问题的另一种方法是迁移学习。这需要一个已经训练了大量通用文本的现有神经网络,然后添加额外的层,并使用针对特定问题的少量内容来训练组合的模型。现有的神经网络类似于人类在学校发展的年代。额外的层次类似于当一个人离开学校并开始工作时发生的领域或特定任务学习。
2. 精度
rda技术的准确性取决于所使用的语言的多样性、风格和复杂性。它还可以取决于:
- 训练数据——机器学习模型的质量取决于训练数据的数量和质量。
- 类的数量——诸如文本分类、情感分析、实体提取和关系提取等技术的准确性将取决于类的数量和实体/关系的类型以及它们之间的重叠。
- 文档大小——对于某些技术,比如文本分类和相似性,大型文档很有帮助,因为它们提供了更多的上下文。情绪分析和总结等其他技术对大型文档的处理难度更大。
NLP-progress是一个网站,它追踪最常见的NLP任务上最先进的模型的准确性。这为可能达到的精确度水平提供了有用的指导。不过,要判断IDA是否会产生准确的结果,最好的指南是问问自己“人类做这件事有多容易?”“如果一个人可以在不经过多年培训的情况下学会准确地完成这项任务,那么IDA就有可能通过加快过程、保持一致性或减少体力劳动来带来好处。”
如何处理智能文档分析项目?
IDA项目可以通过以下两种方式之一集成到企业中:
- 自动化——rda用于自动化现有或新流程,无需任何人工干预
- 人在回路中——IDA用于在人做决策时提供支持,但人负有最终的责任。
所使用的方法应该取决于IDA所达到的准确性和做出错误决策的成本。如果错误决策的成本很高,那么考虑从人工循环开始,直到准确度足够高为止。
IDA项目最好以迭代的方式处理——从概念验证开始,以确定该方法是否可行,如果可行,所达到的精度是否表明使用了自动化或人在循环。然后迭代地增加复杂性,直到估计的工作量不能证明预期的收益。
对于您的第一个IDA项目,请考虑以下步骤:
- 选择一个不正确决策的低成本的用例,或者由人做出最终决策的用例;
- 从概念证明开始,确定方法是否可行;和
- 迭代地增加复杂性以提高应用程序的准确性。
此过程将使您熟悉这些技术,并使您的业务发起人在处理具有更高收益的更复杂的用例之前获得对它们的信心。
通过周密的计划和实施策略,您的组织可以利用上面讨论的NLP和机器学习技术来构建能够改善业务结果的IDA应用程序。
本文:http://jiagoushi.pro/node/1159
讨论:请加入知识星球【首席架构师智库】或者小号【jiagoushi_pro】
- 209 次浏览
【自然语言处理】您需要了解的 5 个 NLP 模型
语言,它是我们生活中最复杂的方面之一。 我们用它来相互交流,与世界交流,与我们的过去和未来交流。 但语言不仅仅是一种交流方式; 这是我们了解发生在我们时代之前的故事并使我们的故事能够传达给后继者的唯一途径。
因为语言几乎是我们的生活所围绕的,我们一直渴望计算机能够理解我们的语言并以我们完全理解的形式与我们交流。 这种愿望与计算机本身的倒置一样古老。
这就是为什么研究人员不知疲倦地工作来驱动算法、构建模型和开发软件,以使计算机更容易理解我们并与我们交流。 然而,在过去的几十年里,技术爆炸式增长,使得新算法比以往任何时候都更复杂、更准确、更简单、更好、更快。
作为一名数据科学家,工作的一个重要部分是跟上技术的最新进展,我们可以使用这些技术更好、更有效地完成工作。 我们需要收集、分析和处理的数据量越来越大,但我们需要更快更好地完成所有这些工作。
实现这一目标的唯一方法是改变我们做事的方式; 我们需要找到更好的方法、更复杂的方法和更高级的方法。 那是研究人员的工作; 作为数据科学家,我们的工作理念是了解最新进展并了解使用它们的最佳方式。
本文将向您展示 5 种自然语言处理模型,如果您想了解该领域的最新情况并希望您的模型更准确地执行,您需要熟悉这些模型。
№1:BERT
BERT 代表来自 Transformers 的双向编码器表示。 BERT 是一种预训练模型,旨在从单词的左右两侧驱动单词的上下文。 BERT 代表了 NLP 的新时代,因为虽然非常准确,但它基本上基于两个简单的想法。
BERT 的核心是两个主要步骤,预训练和微调。在模型的第一步中,BERT 通过各种训练任务针对未标记的数据进行训练。这是通过执行两个无监督任务来完成的:
- Masked ML:在这里,通过覆盖(屏蔽)一些输入标记来随机训练深度双向模型,以避免被分析的单词可以看到自己的循环。
- 下一句预测:在这个任务中,每个预训练设置每个 50% 的时间。如果句子 S1 后跟 S2,则 S2 将被标记为 IsNext。但是如果 S2 是一个随机句子,那么它就会被标记为 NotNext。
完成后,就是微调的时候了。在这个阶段,模型的所有参数都使用标记数据变得更好。这个标记数据是从“下游任务”中获得的。每个下游任务都是具有微调参数的不同模型。
BERT 可以用在很多应用中,例如命名实体识别和问答。如果你想使用 BERT 模型,你可以使用 TensorFlow 或 PyTorch。
№2:XLNet
XLNet 是由来自谷歌和卡内基梅隆大学的一组研究人员开发的。它被开发用于处理常见的自然语言处理应用程序,例如情感分析和文本分类。
XLNet 是一种经过预训练的广义自回归模型,以充分利用 Transformer-XL 和 BERT 的优势。 XLNet 利用 Transformer-XL 的自回归语言模型和自动编码或 BERT。 XLNet 的主要优势在于它的设计具有 Transformer-XL 和 BERT 的优势,而没有它们的局限性。
XLNet 包含与 BERT 相同的基本思想,即双向上下文分析。这意味着它会同时查看被分析令牌之前和之后的单词,以预测它可能是什么。 XLNet 超越了这一点,并计算了一系列单词关于其可能排列的对数似然。
XLNet 避免了 BERT 的限制。它不依赖于数据损坏,因为它是一个自回归模型。实验证明,XLNet 的表现优于 BERT 和 Transformer-XL。
如果你想在你的下一个项目中使用 XLNet,开发它的研究人员在 Tensorflow 中发布了 XLNet 的官方实现。此外,XLNet 的实现可用于翼 PyTorch。
№3:罗伯塔 (RoBERTa)
RoBERTa 是一种自然语言处理模型,它建立在 BERT 之上,专门用于克服其一些弱点并提高其性能。 RoBERTa 是 Facebook AI 和华盛顿大学的研究人员进行的研究的结果。
该研究小组致力于分析双向上下文分析的性能,并确定了一些可以通过使用更大的新数据集来训练模型并删除下一句预测来提高 BERT 性能的更改。
这些修改的结果是 RoBERTa,它代表 Robustly Optimized BERT Approach。 BERT 和 RoBERTa 的区别包括:
- 更大的训练数据集,大小为 160GB。
- 更大的数据集和迭代次数增加到 500K 导致训练时间更长。
- 删除模型的下一句预测部分。
- 更改应用于训练数据的掩蔽 LM 算法。
RoBERTa 的实现作为 PyTorch 包的一部分在 Github 上作为开源提供。
№4:阿尔伯特(ALBERT)
ALBERT 是另一个 BERT 修改模型。在使用 BERT 时,谷歌的研究人员注意到预训练数据集的大小不断增加,这影响了运行模型所需的内存和时间。
为了克服这些缺点,谷歌的研究人员推出了一个更轻的 BERT 版本,或者他们将其命名为 ALBERT。 ALBERT 包括两种方法来克服 BERT 的内存和时间问题。这是通过分解嵌入的参数化并以跨层方式共享参数来完成的。
此外,ALBERT 包括一个自我监督的损失来执行下一句预测,而不是在预训练阶段建立。 这一步是为了克服 BERT 在句子间连贯性方面的局限性。
如果您想体验 ALBERT,可以在 Github 上的 Google 研究存储库中找到由 Google 开发的原始代码库。 您还可以通过 TensorFlow 和 PyTorch 使用实现 ALBERT。
№5:StructBERT
也许到目前为止最新的扩展或 BERT 是 StructBERT。 StructBERT是阿里巴巴研究团队开发构建的BERT全新增强模型。到目前为止,BERT 只考虑了文本的句子级排序,而 ALBERT 则通过使用单词级和句子级排序来克服这一点。
这些技术包括在我们执行预训练过程时捕获句子的语言结构。他们对BERT的主要扩展可以概括为两个主要部分:词结构和句子结构目标。
ALBERT 通过在掩码 LM 阶段混合特定数量的标记来提高 BERT 预测正确句子和单词结构的能力。
使用 ALBERT 进行的实验表明,它在不同的自然语言处理任务(例如为 BERT 开发的原始任务(包括问答和情感分析))中的表现要好于 BERT。
BERT 的源代码尚未作为开源提供,研究团队未来将其放在 Github 上的意图尚不清楚。
关键点
总的来说,数据科学领域,特别是自然语言处理,发展非常迅速。有时,对于在该领域工作了一段时间的经验丰富的数据科学家和旨在从事数据科学职业的初学者来说,这种快速的步伐可能会让人不知所措。
老实说,阅读研究论文从来都不是一项有趣的任务。它们很长,故意以复杂的格式编写,而且通常不容易浏览。这就是为什么我总是欣赏一篇总结算法主要思想以及何时可以使用它们的直截了当的文章。
在本文中,我介绍了 5 种自然语言处理模型,这些模型比之前的模型更先进、更复杂、更准确,并且很快就会向更好的模型迈进。
我希望这篇文章能让您了解外面有什么,不同模型是如何工作的,也许,只是也许,激发了一个新的项目想法,您可以在阅读完本文后立即开始。
原文:https://towardsdatascience.com/5-nlp-models-that-you-need-to-know-about…
本文:
- 151 次浏览
【认知计算】认知风险管理
NLP技术的商业应用

介绍
机器学习 (ML) 应用程序已经无处不在。每天都有关于自动驾驶汽车人工智能、在线客户支持、虚拟个人助理等的新闻。然而,如何将现有的商业实践与所有这些惊人的创新联系起来可能并不明显。一个经常被忽视的领域是应用自然语言处理 (NLP) 和深度学习来帮助快速有效地处理大量业务文档,从而在大海捞针。
允许机器学习有机应用的领域之一是金融机构和保险公司的风险管理。组织在如何应用机器学习来改善风险管理方面面临许多问题。这里只是其中的几个:
- · 如何识别可以从使用人工智能中受益的有影响力的用例?
- · 如何弥合主题专家的直觉期望和技术能力之间的差距?
- · 如何将 ML 集成到现有的企业信息系统中?
- · 如何在生产环境中控制机器学习模型的行为?
本文旨在分享 IBM Data Science and AI Elite (DSE) 和 IBM Expert Labs 团队的经验,基于风险控制领域的多个客户参与。 IBM DSE 构建了各种加速器,可以帮助组织快速开始采用 ML。在这里,我们将介绍风险管理领域的用例,介绍认知风险控制加速器,并讨论机器学习如何改变该领域的企业业务实践。
风险管理草图
2020年,多家金融机构被罚款超过数亿美元/个。罚款的原因是风险控制状态不充分。
这引发了对金融公司的呼吁,以确保他们必须使用的大量风险控制的高质量。这包括明确识别风险、实施风险控制以防止风险发展,以及最终建立测试程序。
对于非专业人士来说,风险控制有点令人困惑。这是关于什么的?一个简单的定义是实施风险控制以监控公司业务运营的风险。例如,安全风险可能是入侵者猜测密码并因此访问某人的帐户。可能的风险控制可以设计为建立一个策略,该策略需要通过组织的系统强制执行长且重要的密码。作为萨班斯-奥克斯利法案 (SOX) 的结果,上市公司需要有效管理此类风险的方法,并作为建立风险控制和评估这些控制质量的努力的一部分。
风险管理人员的一个重要因素是控制是否定义良好。对此的评估可以通过回答诸如谁监控风险、应该做什么来识别或预防风险、在组织的生命周期中应该多久执行一次控制程序等问题来完成。所有这些问题都应该得到回答。现在我们需要意识到,企业中此类控件的数量从数千到数十万不等,人工对控件语料库进行评估是非常困难的。这就是当代人工智能技术能够提供帮助的地方。
当然,这种类型的挑战只是一个例子,试图在一篇文章中涵盖广泛的风险管理领域是不切实际的,因此我们专注于从业者在日常实践中面临的一些具体挑战和已经使用认知风险控制加速器实施。
可用的公共风险控制数据库并不多,因此加速器中的解决方案基于 NIST 特别出版物 800-53 的安全控制,可在 https://nvd.nist.gov/800-53 获得。这个安全控制数据库很小,但它允许我们展示可以扩展到大量和不同风险控制领域的方法。
使用文本分析和深度学习进行风险控制
关键用例类别之一是使现有风险控制合理化:挑战在于现有风险控制的开发方式可能存在许多历史方面。例如,一些风险控制可以通过复制其他现有控制并进行最少的修改来构建。再比如,一些风险控制可以通过将多种风险控制合二为一来形成。这种方法的常见后果是重复的控制以及与业务不再相关的控制的存在。最困难的挑战之一是评估现有风险控制的总体质量状态。因此,从业务角度来看,第一个目标是建立质量评估:自动评估控制描述的质量,通过只关注那些真正需要审查和改进的内容,从而节省大量的日常阅读描述时间。一个很好的问题是人工智能是如何出现在这里的。基于 NLP 的 ML 模型在常见的语言相关任务中变得非常有效,特别是在回答问题等挑战中。此处可以引用的一种模型是基于 Transformer 架构的(更多详细信息,请参阅 https://medium.com/inside-machine-learning/what-is-a-transformer- 上有关 Transformer 架构的文章d07dd1fbec04)。
在风险管理草图中,回答有关风险控制描述的问题的能力是评估控制描述质量的关键。 从鸟瞰的角度来看,未回答问题的数量是控制描述质量的一个很好的指标。 最好的消息是,借助 Transformers 等当代 AI 模型的功能以及附加的实用规则,这种提出正确问题的技术成为一种有效机制,可以在 AI 的帮助下由一个小团队控制大量控制描述。
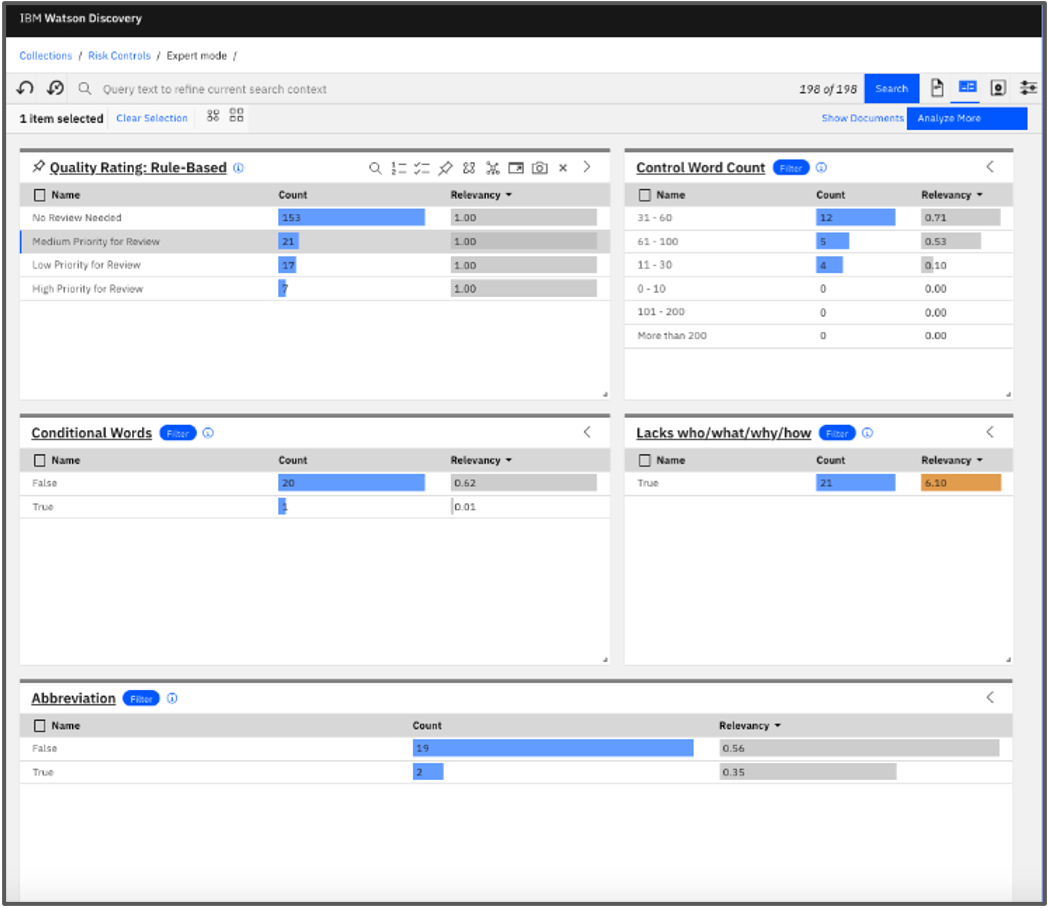
- Controls Quality Assessment (image by authors)
通常,在文档中查找重复项被认为是一项简单的任务,Levenshtein Distance 可以帮助查找用相似措辞表达的项目。 但是,如果我们想找到语义相似的描述,这将成为一项更具挑战性的任务。 这是当代人工智能可以提供帮助的另一个领域——使用大型神经网络(例如自动编码器、语言模型等)构建的嵌入可以捕获语义相似性。 从实际结果的角度来看,我们的经验是重复和重叠的识别可能导致控制量减少多达 30%。
- Analysis of Overlaps (image by authors)
此外,通过聚类等机器学习技术分析信息的内部结构已成为一种常见的做法。 这使业务从业者能够更好地理解更大规模的控制内容,并查看现有的风险和控制分类是否与内容保持一致,或者两者中可能缺少什么。
- Clustering Example (image by authors)
以前的用例主要集中在现有控件的分析上。另一个用例侧重于帮助风险经理创建新的风险控制。使用语义相似性为给定风险推荐控制可以显着减少人工工作并为构建控制提供灵活的模板。机器学习可以帮助分析风险描述并找出正确的控制集来解决每个风险。
在大型组织中,团队通常致力于其他团队可能使用的解决方案和最佳实践。在整个组织中采用最佳实践需要广泛的培训。机器学习在这种情况下非常有用。一个例子可能是将控制分类为预防性或检测性。在这个用例中,我们使用监督机器学习通过使用来自特定团队的现有标记集将控件分类扩展到整个控件集,即使用机器学习完成知识转移,而不是耗时的人员培训。
IBM DSE 风险控制加速器中的认知技术使我们能够构建风险控制、推荐以自然语言表述的风险控制、识别控制中的重叠以及分析控制的质量。
该加速器提供了一个认知控制分析应用程序,该应用程序集成了已开发的模型并将其应用于非结构化风险控制内容。
使用 IBM Cloud Pak for Data 实施认知风险控制
从逻辑上讲,认知风险控制加速器包含几个组件:
- 第一个是所谓的认知助手——它是一个应用 ML 模型来促进内容处理的应用程序,例如,通过识别风险控制优先级、类别和评估控制描述的质量。作为产品化的一部分,认知助理成为企业信息系统的一部分。

- 第二个组件是内容分析:当通过机器学习模型丰富数据时,Watson Discovery 内容挖掘可用于在丰富的内容中找到洞察力
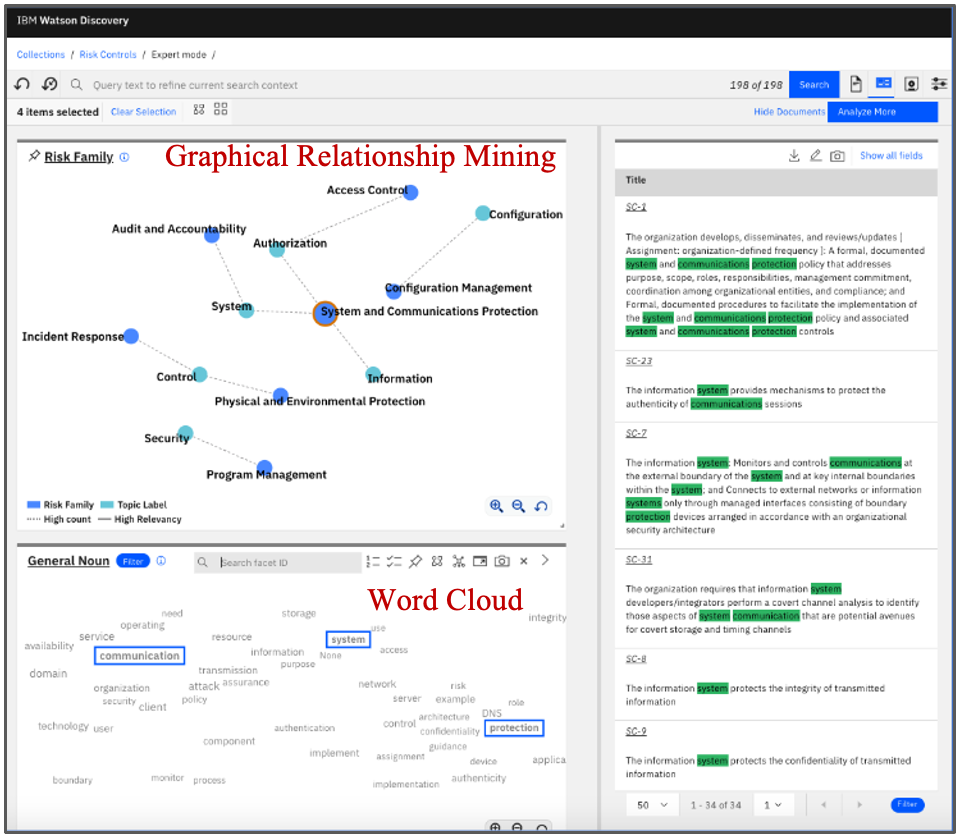
Content Analysis with Watson Discovery (image by authors)
- 另一个组件是一组支持数据科学模型的 Jupyter 笔记本
- Jupyter Notebook in Watson Studio (image by authors)
让我们看看使用 IBM Cloud Pak for Data 的基于加速器的实现的底层。
在我们这样做之前,让我们简要回顾一下 IBM 平台和方法。 IBM 有一种用于 AI 之旅的规范方法,称为 AI 阶梯。在他的“AI 阶梯:揭开 AI 挑战的神秘面纱”中,Rob Thomas(IBM 云和认知软件高级副总裁)证实,要将您的数据转化为洞察力,您的组织应遵循以下列出的阶段:
- 收集 — 轻松访问数据的能力,包括数据虚拟化
- 组织 — 对数据进行编目、构建数据字典以及确保访问数据的规则和政策的方法
- 分析——这包括交付机器学习模型,使用数据科学来识别使用认知工具和人工智能技术的洞察力。这自然需要构建、部署和管理您的机器学习模型
- 注入——从很多角度来看,这是一个关键阶段。这是指以允许业务信任结果的方式操作 AI 模型的能力,即在生产模式下在企业系统中使用您的机器学习模型,同时能够确保这些模型的持续性能及其可解释性.
Cloud Pak for Data 是 IBM 的多云数据和 AI 平台,提供信息架构并提供所有概述的功能。下图捕获了在 AI Ladder 上下文中开发实现的详细信息。
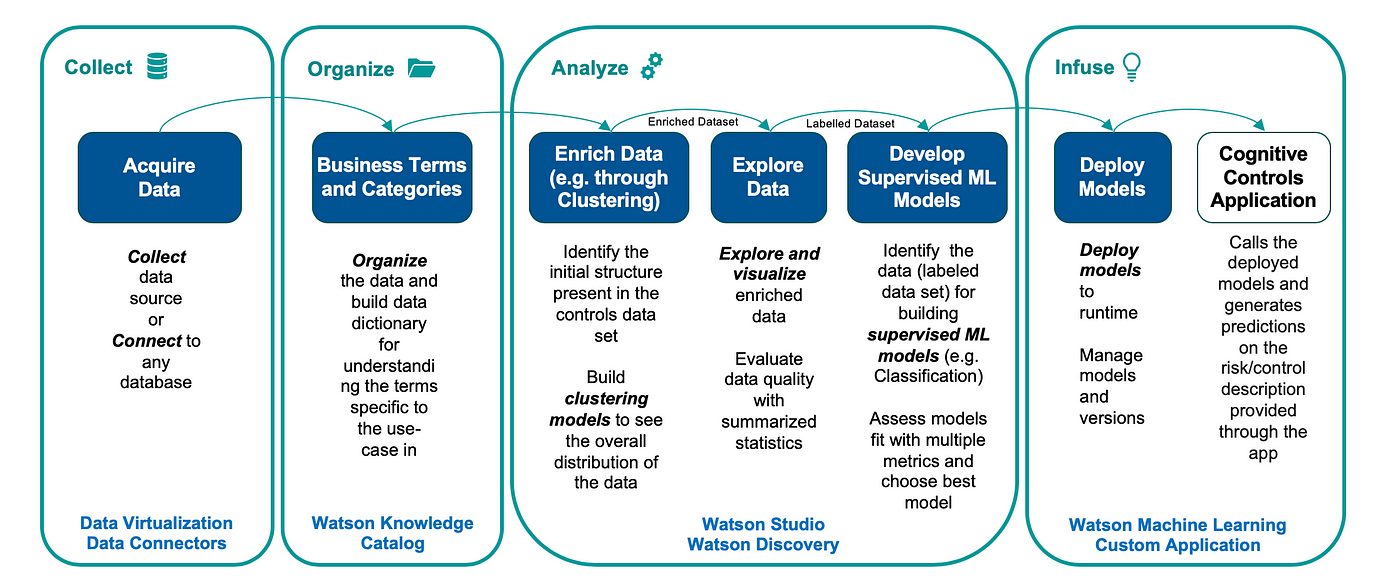
- Phases (image by authors)
它捕获了基于 DSE 加速器实施认知风险控制项目的各个阶段:
- 实施风险控制项目的前两个阶段是获取和编目数据集——例如,在加速器中,我们使用 NIST 控制数据集。此处的控件表示为自由文本描述。
- 下一阶段是在 Watson Studio 中丰富获取的非结构化数据:聚类被用作理解内容内部结构的一种方式。风险控制叙述可能很长,可能会讨论多个主题,因此可能需要一些机制来跟踪随着描述的进展而变化的主题。在我们的聚类实践中,我们在嵌入和潜在狄利克雷分配 (LDA) 之上使用了 K-means。它确实需要数据科学家和主题专家的仔细协调,因为数学可能与中小企业的期望不符。这里也可以进行更广泛的丰富——一个很好的例子是对描述的质量进行分类。
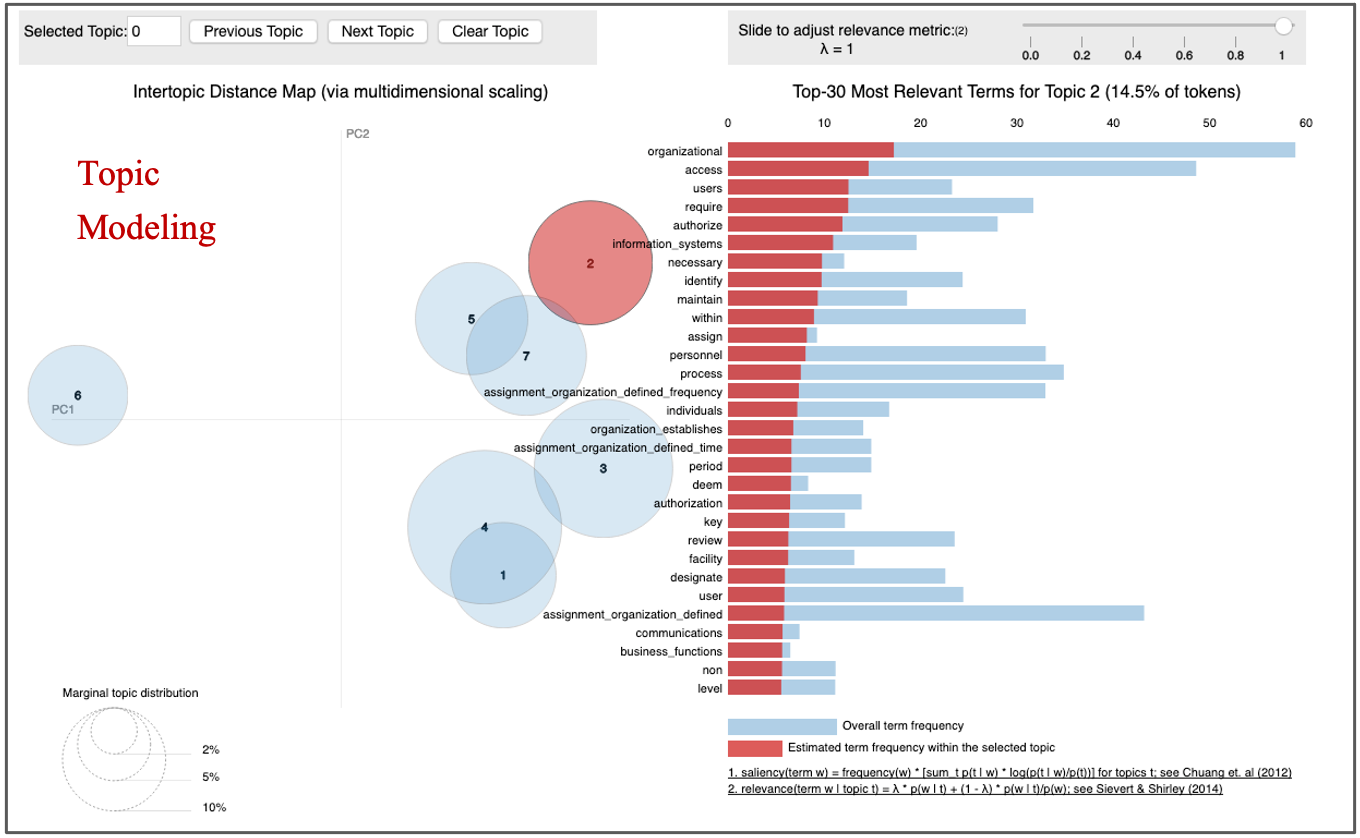
Topic Modeling (image by authors)
- 扩充完成后,我们需要了解生成的数据集。这导致我们进入探索阶段。在实践中,挑战在于数量。内容审查是最耗时的过程之一,因为它需要仔细阅读大量文本。我们如何探索海量的非结构化信息? Watson Discovery 内容挖掘是使这成为可能并大大减少工作量的工具。
- 内容经过中小企业审查后,构成了构建监督机器学习模型的基础。 IBM 平台提供了部署模型、监控偏差以及获得复杂模型决策的可解释性的方法。所有这些都包含在机器学习的操作化中,并由 IBM Cloud Pak For Data 提供支持。
结论
本文介绍了机器学习在当代商业中不断增长的应用领域之一——认知风险控制。访问我们的加速器目录,了解有关认知控制加速器的更多信息。如果您有兴趣了解有关认知风险控制和 AI 技术的更多信息,请随时与 IBM Data Science and AI Elite Team 联系。此外,如果您发现您的用例与所提供的用例相似,或者如果您的业务和技术挑战可以通过上述方法或工具解决,请联系 IBM。
致谢
作者(IBM DSE 和专家实验室)感谢他们的同事在认知控制业务和技术方法方面的持续合作和开发:Stephen Mills(IBM Promontory 董事总经理)、Miles Ravitz(IBM Promontory 高级负责人)、 Rodney Rideout(IBM 全球企业咨询服务部交付主管)、Vinay Rao Dandin(数据科学家)、Aishwarya Srinivasan(数据科学家,IBM DSE)和 Rakshith Dasenahalli Lingaraju(数据科学家,IBM DSE)。
原文:https://towardsdatascience.com/cognitive-risk-management-7c7bcfe84219
- 77 次浏览
【语言模型】2022年NLP的10个主要语言模型
视频号
微信公众号
知识星球
更新:考虑到大型语言模型的最新研究进展,我们已经发布了本文的更新版本。看看2023年改变人工智能的前六大NLP语言模型。
迁移学习和预训练语言模型在自然语言处理(NLP)中的引入推动了语言理解和生成的极限。迁移学习和将变压器应用于不同的下游NLP任务已成为最新研究进展的主要趋势。
与此同时,NLP界对占据排行榜的巨大预训练语言模型的研究价值存在争议。尽管许多人工智能专家同意安娜·罗杰斯的说法,即仅仅通过使用更多的数据和计算能力来获得最先进的结果不是研究新闻,但其他NLP意见领袖指出了当前趋势中的一些积极时刻,例如,看到当前范式的根本局限性的可能性。
无论如何,NLP语言模型的最新改进似乎不仅是由于计算能力的巨大提升,而且还因为发现了在保持高性能的同时减轻模型重量的巧妙方法。
为了帮助您了解语言建模方面的最新突破,我们总结了过去几年中引入的关键语言模型的研究论文。
订阅本文底部的人工智能研究邮件列表,以便在我们发布新摘要时得到提醒。
如果你想跳过,以下是我们的专题报道:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- GPT2: Language Models Are Unsupervised Multitask Learners
- XLNet: Generalized Autoregressive Pretraining for Language Understanding
- RoBERTa: A Robustly Optimized BERT Pretraining Approach
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- GPT3: Language Models Are Few-Shot Learners
- ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
- DeBERTa: Decoding-enhanced BERT with Disentangled Attention
- PaLM: Scaling Language Modeling with Pathways
重要的预训练语言模型
1.《BERT:语言理解深度双向转换的预训练》
,Jacob Devlin、Ming Wei Chang、Kenton Lee和Kristina Toutanova著
原始摘要
我们介绍了一种新的语言表示模型,称为BERT,它代表来自Transformers的双向编码器表示。与最近的语言表示模型不同,BERT被设计为通过在所有层中联合调节左右上下文来预训练深度双向表示。因此,只需一个额外的输出层,就可以对预先训练的BERT表示进行微调,为广泛的任务(如问答和语言推理)创建最先进的模型,而无需对特定任务的架构进行实质性修改。
BERT概念简单,经验丰富。它在11项自然语言处理任务上获得了最先进的结果,包括将GLUE基准提高到80.4%(7.6%的绝对改进),将MultiNLI准确率提高到86.7(5.6%的绝对改善),以及将SQuAD v1.1问答测试F1提高到93.2(1.5%的绝对提高),比人类表现高2.0%。
我们的总结
谷歌人工智能团队为自然语言处理(NLP)提出了一个新的尖端模型——BERT,即来自Transformers的双向编码器表示。它的设计允许模型从每个单词的左侧和右侧考虑上下文。虽然概念上很简单,但BERT在11项NLP任务上获得了最先进的结果,包括问答、命名实体识别和其他与一般语言理解相关的任务。
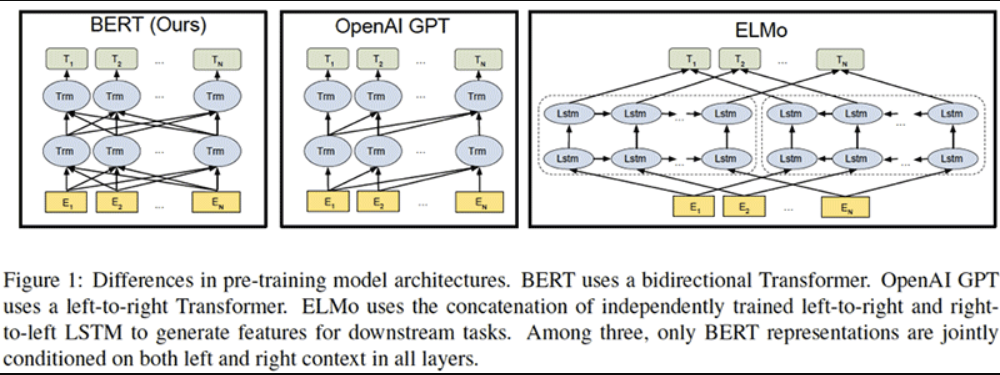
这篇论文的核心思想是什么?
- 通过随机屏蔽一定比例的输入令牌来训练深度双向模型,从而避免单词可以间接“看到自己”的循环。
- 此外,通过构建一个简单的二元分类任务来预测句子B是否紧跟在句子a之后,从而使BERT能够更好地理解句子之间的关系,从而预训练句子关系模型。
- 用大量数据(33亿个单词语料库)训练一个非常大的模型(24个Transformer块,1024个隐藏,340M个参数)。
关键成就是什么?
- 推进11项NLP任务的最先进技术,包括:
- GLUE得分为80.4%,比之前的最佳成绩提高了7.6%;
- 在SQuAD 1.1上实现了93.2%的准确率,并比人类性能高出2%。
- 提出了一个预先训练的模型,该模型不需要任何实质性的架构修改即可应用于特定的NLP任务。
人工智能界是怎么想的?
- BERT模型标志着NLP进入了一个新的时代。
- 简而言之,两个无监督任务(“填空”和“句子B在句子a之后吗?”)一起为许多NLP任务提供了很好的结果。
- 语言模型的预训练成为一种新的标准。
未来的研究领域是什么?
- 在更广泛的任务中测试该方法。
- 研究BERT可能捕捉到或不捕捉到的语言现象。
什么是可能的业务应用程序?
- BERT可以帮助企业解决一系列NLP问题,包括:
- 聊天机器人提供更好的客户体验;
- 分析客户评价;
- 搜索相关信息等。
从哪里可以获得实现代码?
- Google Research has released an official Github repository with Tensorflow code and pre-trained models for BERT.
- PyTorch implementation of BERT is also available on GitHub.
2.语言模型是无监督的多任务学习者,
作者:Alec Radford,Jeffrey Wu,Rewon Child,David Luan,Dario Amodei,Ilya Sutskever
原始摘要
自然语言处理任务,如问答、机器翻译、阅读理解和摘要,通常在特定任务数据集上进行监督学习。我们证明,当在一个名为WebText的数百万网页的新数据集上进行训练时,语言模型在没有任何明确监督的情况下开始学习这些任务。当以文档加问题为条件时,语言模型生成的答案在CoQA数据集上达到55 F1——在不使用127000+训练示例的情况下,匹配或超过了四分之三的基线系统的性能。语言模型的能力对于零样本任务转移的成功至关重要,增加它可以以对数方式跨任务提高性能。我们最大的模型GPT-2是一个1.5B参数的Transformer,它在8个测试语言建模数据集中有7个在零样本设置下获得了最先进的结果,但仍低于WebText。模型中的样本反映了这些改进,并包含连贯的文本段落。这些发现为构建语言处理系统提供了一条很有前途的途径,该系统从自然发生的演示中学习执行任务。
我们的总结
在本文中,OpenAI团队证明了预训练的语言模型可以用于解决下游任务,而无需任何参数或架构修改。他们在一个庞大而多样的数据集上训练了一个非常大的模型,一个1.5B参数的Transformer,该数据集包含从4500万个网页中抓取的文本。该模型生成连贯的文本段落,并在各种任务上取得有希望、有竞争力或最先进的结果。
这篇论文的核心思想是什么?
- 在庞大多样的数据集上训练语言模型:
- 选择由人类策划/过滤的网页;
- 清理和消除文本的重复,并删除所有维基百科文档,以最大限度地减少训练集和测试集的重叠;
- 使用最终的WebText数据集,该数据集具有略多于800万个文档,总共40GB的文本。
- 使用字节级版本的字节对编码(BPE)进行输入表示。
- 构建一个非常大的基于Transformer的模型GPT-2:
- 最大的模型包括1542M个参数和48层;
- 该模型主要遵循OpenAI GPT模型,很少进行修改(即扩展词汇表和上下文大小、修改初始化等)。
关键成就是什么?
- 在8个测试语言建模数据集中的7个上获得最先进的结果。
- 在常识推理、问答、阅读理解和翻译方面显示出相当有希望的结果。
- 生成连贯的文本,例如,一篇关于发现会说话的独角兽的新闻文章。
人工智能界是怎么想的?
“研究人员建立了一个有趣的数据集,应用了现在的标准工具,并产生了一个令人印象深刻的模型。”——卡内基梅隆大学助理教授Zachary C.Lipton。
未来的研究领域是什么?
研究对decaNLP和GLUE等基准的微调,以了解GPT-2的巨大数据集和容量是否可以克服BERT单向表示的低效性。
什么是可能的业务应用程序?
就实际应用而言,GPT-2模型在没有任何微调的情况下的性能远远不能使用,但它显示了一个非常有前途的研究方向。
从哪里可以获得实现代码?
- 最初,OpenAI决定只发布一个较小版本的GPT-2,参数为117M。决定不发布更大的模型是“因为担心大型语言模型被用来大规模生成欺骗性、偏见或滥用语言”。
- 11月,OpenAI终于发布了其最大的1.5B参数模型。此处提供代码。
- 拥抱脸引入了最初发布的GPT-2模型的PyTorch实现。
3、 XLNet: Generalized Autoregressive Pretraining for Language Understanding
by Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le
原始摘要
由于具有对双向上下文建模的能力,与基于自回归语言建模的预训练方法相比,像BERT这样的基于去噪自动编码的预训练获得了更好的性能。然而,依赖于用掩码破坏输入,BERT忽略了掩码位置之间的依赖性,并受到预训练微调差异的影响。鉴于这些优点和缺点,我们提出了XLNet,这是一种广义自回归预训练方法,它(1)通过最大化因子分解阶的所有排列上的期望似然来实现双向上下文的学习,(2)由于其自回归公式克服了BERT的局限性。此外,XLNet将最先进的自回归模型Transformer XL的思想集成到预训练中。从经验上看,XLNet在20项任务上的表现优于BERT,通常相差很大,并在18项任务上取得了最先进的结果,包括问答、自然语言推理、情感分析和文档排名。
我们的总结
卡内基梅隆大学和谷歌的研究人员开发了一种新的模型XLNet,用于自然语言处理(NLP)任务,如阅读理解、文本分类、情绪分析等。XLNet是一种广义的自回归预训练方法,它利用了自回归语言建模(例如Transformer XL)和自动编码(例如BERT)的优点,同时避免了它们的局限性。实验表明,新模型的性能优于BERT和Transformer XL,并在18个NLP任务上实现了最先进的性能。
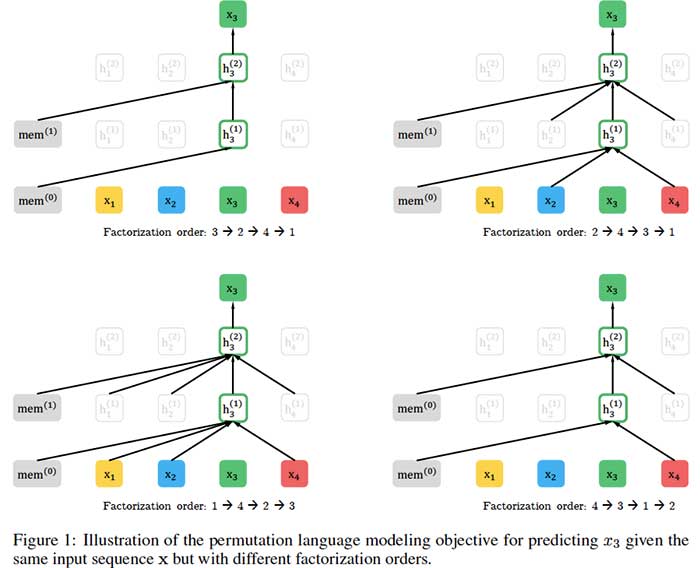
这篇论文的核心思想是什么?
- XLNet将BERT的双向能力与Transformer XL的自回归技术相结合:
- 与BERT一样,XLNet使用双向上下文,这意味着它查看给定令牌之前和之后的单词,以预测它应该是什么。为此,XLNet最大化了序列相对于因子分解顺序的所有可能排列的预期对数似然性。
- 作为一种自回归语言模型,XLNet不依赖于数据损坏,因此避免了BERT因掩蔽而受到的限制——即预训练微调差异和未掩蔽令牌相互独立的假设。
- 为了进一步改进预训练的架构设计,XLNet集成了Transformer XL的分段递归机制和相关编码方案。
关键成就是什么?
- XLnet在20项任务上优于BERT,通常有很大的优势。
- 新模型在18项NLP任务上实现了最先进的性能,包括问答、自然语言推理、情感分析和文档排序。
人工智能界是怎么想的?
- 这篇论文被人工智能领域的领先会议NeurIPS 2019接受口头演讲。
- “国王死了。国王万岁。BERT的统治可能即将结束。CMU和谷歌的新模型XLNet在20项任务上优于BERT。”——Deepmind的研究科学家Sebastian Ruder。
- “XLNet可能会在一段时间内成为任何NLP从业者的重要工具……[它]是NLP中最新的尖端技术。”——卡耐基梅隆大学的Keita Kurita。
未来的研究领域是什么?
- 将XLNet扩展到新的领域,例如计算机视觉和强化学习。
什么是可能的业务应用程序?
- XLNet可以帮助企业解决各种NLP问题,包括:
- 用于一线客户支持或回答产品咨询的聊天机器人;
- 情绪分析,用于基于客户评论和社交媒体来衡量品牌知名度和感知;
- 在文档库或网上搜索相关信息等。
从哪里可以获得实现代码?
- 作者已经发布了XLNet的官方Tensorflow实现。
- 该模型的PyTorch实现也可在GitHub上获得。
4.《RoBERTa:一种稳健优化的BERT预训练方法》,
作者:Yinhan Liu、Myle Ott、Naman Goyal、Du Jingfei、Mandar Joshi、Danqi Chen、Omer Levy、Mike Lewis、Luke Zettlemoyer、Veselin Stoyanov
原始摘要
语言模型预训练带来了显著的性能提升,但不同方法之间的仔细比较具有挑战性。训练在计算上是昂贵的,通常在不同大小的私人数据集上进行,正如我们将要展示的,超参数选择对最终结果有重大影响。我们提出了一项BERT预训练的复制研究(Devlin et al.,2019),该研究仔细测量了许多关键超参数和训练数据大小的影响。我们发现BERT的训练严重不足,可以达到或超过之后发布的每个模型的性能。我们最好的模型在GLUE、RACE和SQuAD方面取得了最先进的结果。这些结果突出了以前被忽视的设计选择的重要性,并对最近报告的改进来源提出了疑问。我们发布了我们的模型和代码。
我们的总结
由于预训练方法的引入,自然语言处理模型取得了重大进展,但训练的计算费用使复制和微调参数变得困难。在这项研究中,脸书人工智能和华盛顿大学的研究人员分析了谷歌双向编码器表示从变压器(BERT)模型的训练,并确定了训练程序的几个变化,以提高其性能。具体来说,研究人员使用了一个新的、更大的数据集进行训练,在更多的迭代中训练模型,并删除了下一个序列预测训练目标。由此产生的优化模型RoBERTa(鲁棒优化BERT方法)与最近引入的XLNet模型在GLUE基准上的得分相匹配。
这篇论文的核心思想是什么?
- 脸书人工智能研究团队发现,BERT训练严重不足,并提出了一个改进的训练配方,名为RoBERTa:
- 更多数据:160GB的文本,而不是最初用于训练BERT的16GB数据集。
- 更长的训练:将迭代次数从100K增加到300K,然后进一步增加到500K。
- 较大的批次:8K,而不是原来BERT基本型号中的256。
- 具有50K子字单元的较大字节级BPE词汇表,而不是大小为30K的字符级BPE词汇量。
- 从训练过程中删除下一个序列预测目标。
- 动态更改应用于训练数据的掩蔽模式。
关键成就是什么?
- 在通用语言理解评估(GLUE)基准测试中,RoBERTa在所有单项任务中都优于BERT。
- 新模型与最近在GLUE基准上引入的XLNet模型相匹配,并在九个单独任务中的四个任务中设定了新的技术水平。
未来的研究领域是什么?
- 包含更复杂的多任务微调程序。
什么是可能的业务应用程序?
- 像RoBERTa这样经过预训练的大型语言框架可以在业务环境中用于广泛的下游任务,包括对话系统、问答、文档分类等。
从哪里可以获得实现代码?
本研究中使用的模型和代码可在GitHub上获得。
5. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations,
by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut
原始摘要
在预训练自然语言表示时增加模型大小通常会提高下游任务的性能。然而,在某些时候,由于GPU/TPU内存限制、较长的训练时间和意外的模型退化,进一步的模型增加变得更加困难。为了解决这些问题,我们提出了两种参数约简技术来降低BERT的内存消耗和提高训练速度。综合的经验证据表明,与最初的BERT相比,我们提出的方法产生了规模更好的模型。我们还使用了一种自我监督损失,该损失侧重于对句子间连贯性进行建模,并表明它始终有助于多句子输入的下游任务。因此,我们的最佳模型在GLUE、RACE和SQuAD基准上建立了新的最先进的结果,同时与BERT-large相比,参数更少。
我们的总结
谷歌研究团队解决了预先训练的语言模型不断增长的问题,这会导致内存限制、训练时间延长,有时还会意外地降低性能。具体而言,他们引入了一种精简的BERT(ALBERT)架构,该架构包含两种参数约简技术:因子化嵌入参数化和跨层参数共享。此外,所提出的方法包括句子顺序预测的自监督损失,以提高句间连贯性。实验表明,ALBERT的最佳版本在GLUE、RACE和SQuAD基准上设定了新的最先进的结果,同时具有比BERT-large更少的参数。
这篇论文的核心思想是什么?
- 由于可用硬件的内存限制、较长的训练时间以及随着参数数量的增加模型性能的意外下降,通过使语言模型更大来进一步改进语言模型是不合理的。
- 为了解决这个问题,研究人员引入了ALBERT架构,该架构包含两种参数缩减技术:
- 因子化嵌入参数化,其中通过将大的词汇嵌入矩阵分解为两个小矩阵,将隐藏层的大小与词汇嵌入的大小分离;
- 跨层参数共享,以防止参数的数量随着网络的深度而增长。
- 通过引入句子顺序预测的自监督损失来解决BERT在句间连贯方面的局限性,进一步提高了ALBERT的性能。
关键成就是什么?
- 通过引入参数约简技术,与原始BERT大模型相比,参数减少了18倍、训练速度加快了1.7倍的ALBERT配置仅实现了略差的性能。
- 比BERT大得多的ALBERT配置仍然具有更少的参数,其性能优于当前所有最先进的语言模式,如下所示:
- 在RACE基准上的准确率为89.4%;
- GLUE基准得分89.4分;和
- 在SQuAD 2.0基准上,F1成绩为92.2。
人工智能界是怎么想的?
- 该论文已提交给ICLR 2020,可在OpenReview论坛上查看,您可以在论坛上查看NLP专家的评论和意见。评审人员主要对所提交的论文非常赞赏。
未来的研究领域是什么?
- 通过稀疏注意力和块注意力等方法加快训练和推理。
- 通过硬示例挖掘、更高效的模型训练和其他方法进一步提高模型性能。
什么是可能的业务应用程序?
- ALBERT语言模型可以在商业环境中使用,以提高一系列下游任务的性能,包括聊天机器人性能、情感分析、文档挖掘和文本分类。
从哪里可以获得实现代码?
- ALBERT的原始实现可在GitHub上获得。
- 这里还提供了ALBERT的TensorFlow实现。
- ALBERT的PyTorch实现可以在这里和这里找到。
6.Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu
原始摘要
迁移学习是自然语言处理(NLP)中一种强大的技术,它首先在数据丰富的任务上对模型进行预训练,然后在下游任务上进行微调。迁移学习的有效性导致了方法、方法和实践的多样性。在本文中,我们通过引入一个统一的框架来探索NLP的迁移学习技术的前景,该框架将每个语言问题转换为文本到文本的格式。我们的系统研究比较了数十项语言理解任务的预训练目标、架构、未标记数据集、迁移方法和其他因素。通过将我们的探索见解与规模和我们新的“Colossal Clean Crawled Corpus”相结合,我们在许多基准测试上取得了最先进的成果,包括摘要、问答、文本分类等。为了促进NLP迁移学习的未来工作,我们发布了我们的数据集、预先训练的模型和代码。
我们的总结
谷歌研究团队提出了一种在NLP中进行迁移学习的统一方法,目的是在该领域开创一个新的技术状态。为此,他们建议将每个NLP问题视为“文本到文本”的问题。这样的框架允许对不同的任务使用相同的模型、目标、训练过程和解码过程,包括摘要、情绪分析、问答和机器翻译。研究人员将他们的模型称为文本到文本转换转换器(T5),并在大量网络抓取数据的语料库上对其进行训练,以在许多NLP任务中获得最先进的结果。
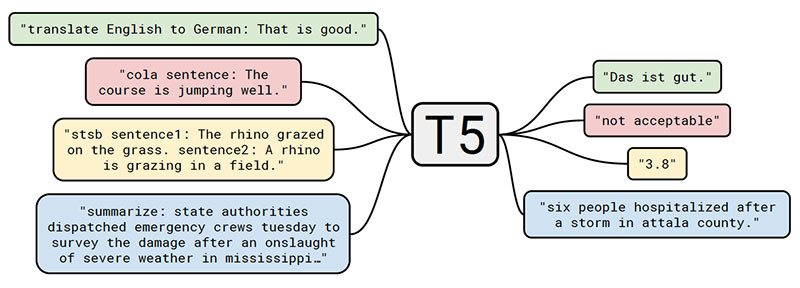
这篇论文的核心思想是什么?
- 该文件有几个重要贡献:
- 通过探索和比较现有技术,提供一个关于NLP领域现状的全面视角。
- 通过建议将每一个NLP问题都视为一个文本到文本的任务,介绍了一种在NLP中进行迁移学习的新方法:
- 由于在原始输入句子中添加了特定于任务的前缀(例如,“将英语翻译成德语:”、“总结:”),该模型可以理解应该执行哪些任务。
- 展示并发布了一个新的数据集,该数据集由数百千兆字节的干净的网络抓取英语文本组成,即Colossal clean Crawled Corpus(C4)。
- 在C4数据集上训练一个称为文本到文本转换转换器(T5)的大型(高达11B参数)模型。
关键成就是什么?
- 拥有110亿个参数的T5模型在考虑的24项任务中的17项任务中实现了最先进的性能,包括:
- GLUE得分为89.7,在CoLA、RTE和WNLI任务上的表现显著改善;
- 在SQuAD数据集上的精确匹配得分为90.06;
- SuperGLUE得分为88.9,这比之前最先进的结果(84.6)有了非常显著的改进,非常接近人类的表现(89.8);
- 在CNN/每日邮报抽象摘要任务中,ROUGE-2F得分为21.55。
未来的研究领域是什么?
- 研究用更便宜的型号实现更强性能的方法。
- 探索更有效的知识提取技术。
- 进一步研究语言不可知论模型。
什么是可能的业务应用程序?
- 尽管引入的模型有数十亿个参数,并且可能太重而无法应用于商业环境,但所提出的思想可以用于提高不同NLP任务的性能,包括摘要、问题回答和情绪分析。
从哪里可以获得实现代码?
- 经过预训练的模型以及数据集和代码在GitHub上发布。
7.Language Models are Few-Shot Learners
by Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei
原始摘要
最近的工作表明,通过对大量文本进行预训练,然后对特定任务进行微调,在许多NLP任务和基准测试方面取得了实质性的进展。虽然在架构上通常与任务无关,但这种方法仍然需要数千或数万个实例的特定任务微调数据集。相比之下,人类通常只能通过几个例子或简单的指令来执行一项新的语言任务,而当前的NLP系统在很大程度上仍然难以做到这一点。在这里,我们表明,扩大语言模型的规模大大提高了任务不可知的、少镜头的性能,有时甚至与之前最先进的微调方法相比具有竞争力。具体来说,我们训练GPT-3,这是一个具有1750亿个参数的自回归语言模型,比以前的任何非稀疏语言模型都多10倍,并测试其在少数镜头设置中的性能。对于所有任务,GPT-3在没有任何梯度更新或微调的情况下应用,任务和少量镜头演示完全通过与模型的文本交互指定。GPT-3在许多NLP数据集上实现了强大的性能,包括翻译、问答和完形填空任务,以及一些需要即时推理或领域自适应的任务,如解读单词、在句子中使用新词或执行三位数算术。同时,我们还确定了GPT-3的少量镜头学习仍然很困难的一些数据集,以及GPT-3面临与在大型网络语料库上训练相关的方法论问题的一些数据集中。最后,我们发现GPT-3可以生成新闻文章的样本,而人类评估者很难将其与人类撰写的文章区分开来。我们讨论了这一发现和GPT-3的更广泛的社会影响。
我们的总结
OpenAI研究团队提请注意这样一个事实,即每一项新的语言任务都需要一个标记的数据集,这限制了语言模型的适用性。考虑到可能的任务范围很广,而且通常很难收集到一个大的标记训练数据集,研究人员提出了一种替代解决方案,即扩大语言模型的规模,以提高与任务无关的少镜头性能。他们通过训练一个175B参数的自回归语言模型GPT-3来测试他们的解决方案,并评估其在二十多个NLP任务中的性能。在少拍学习、一拍学习和零样本学习下的评估表明,GPT-3取得了很好的效果
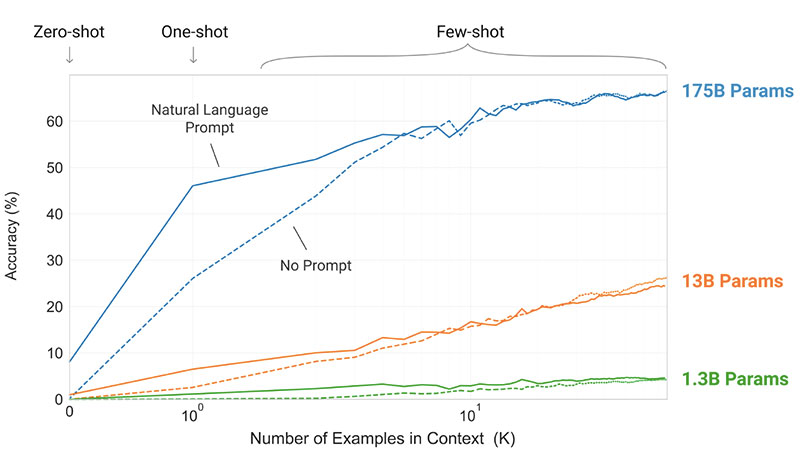
这篇论文的核心思想是什么?
- GPT-3模型使用与GPT-2相同的模型和架构,包括修改的初始化、预规范化和可逆标记化。
- 然而,与GPT-2相比,它在变换器的层中使用交替的密集和局部带状稀疏注意力模式,如稀疏变换器中一样。
- 该模型在三种不同的设置中进行评估:
- 很少的镜头学习,当在推理时给模型一些任务演示(通常是10到100),但不允许权重更新时。
- 一次性学习,只允许进行一次演示,同时提供任务的自然语言描述。
- 当不允许演示且模型只能访问任务的自然语言描述时,进行零样本学习。
关键成就是什么?
- 没有微调的GPT-3模型在许多NLP任务上取得了有希望的结果,甚至偶尔会超过为该特定任务微调的最先进模型:
- 在CoQA基准测试中,与微调SOTA获得的90.7 F1分数相比,零样本设置中的F1分数为81.5,单射设置中的F184.0,少射设置中为85.0。
- 在TriviaQA基准测试中,零样本设置的准确率为64.3%,一射设置的准确度为68.0%,少射设置的精确度为71.2%,超过了最新技术(68%)3.2%。
- 在LAMBADA数据集上,零样本设置的准确率为76.2%,一次性设置为72.5%,少量快照设置为86.4%,超过当前技术水平(68%)18%。
- 根据人类的评估,175B参数GPT-3模型生成的新闻文章很难与真实的区分开来(准确率略高于约52%的概率水平)。
未来的研究领域是什么?
- 提高训练前样本的效率。
- 探索少镜头学习是如何运作的。
- 将大型模型精简到可管理的大小,以用于实际应用。
人工智能界是怎么想的?
- “GPT-3的炒作太过了。它给人留下了深刻的印象(感谢你的赞美!)但它仍然有严重的弱点,有时还会犯非常愚蠢的错误。人工智能将改变世界,但GPT-3只是一个很早的一瞥。我们还有很多事情要弄清楚。”——OpenAI首席执行官兼联合创始人Sam Altman。
- Gradio首席执行官兼创始人Abubakar Abid表示:“我很震惊,从GPT-3中生成与暴力……或被杀无关的关于穆斯林的文本是多么困难。”。
- “不。GPT-3从根本上不了解它所谈论的世界。进一步增加语料库将使它能够产生更可信的模仿,但不能解决其对世界根本缺乏理解的问题。GPT-4的演示仍然需要人类挑选樱桃。”——Robust.ai首席执行官兼创始人Gary Marcus。
- “将GPT3的惊人性能外推到未来,表明生命、宇宙和一切的答案只有4.398万亿个参数。”——图灵奖得主杰弗里·辛顿。
什么是可能的业务应用程序?
- 由于其不切实际的资源需求,具有175B参数的模型很难应用于实际的业务问题,但如果研究人员设法将该模型提取到可行的大小,它可以应用于广泛的语言任务,包括问答和广告副本生成。
从哪里可以获得实现代码?
- 代码本身不可用,但GitHub上发布了一些数据集统计数据以及GPT-3中无条件、未经过滤的2048个令牌样本。
8. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators,
by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning
原始摘要
掩码语言建模(MLM)预训练方法(如BERT)通过用[MASK]替换一些令牌来破坏输入,然后训练模型来重建原始令牌。虽然它们在转移到下游NLP任务时产生了良好的结果,但它们通常需要大量的计算才能有效。作为一种替代方案,我们提出了一种更具样本效率的预训练任务,称为替换令牌检测。我们的方法不是屏蔽输入,而是通过用从小型生成器网络中采样的看似合理的替代品替换一些令牌来破坏输入。然后,我们不是训练一个预测损坏令牌的原始身份的模型,而是训练一个判别模型,该判别模型预测损坏输入中的每个令牌是否被生成器样本替换。彻底的实验表明,这种新的预训练任务比MLM更有效,因为该任务是在所有输入令牌上定义的,而不仅仅是被屏蔽的子集。因此,在给定相同的模型大小、数据和计算的情况下,我们的方法所学习的上下文表示大大优于BERT所学习的。小型车型的收益尤其强劲;例如,我们在一个GPU上训练一个模型4天,该模型在GLUE自然语言理解基准上优于GPT(使用30倍以上的计算训练)。我们的方法在规模上也能很好地工作,在使用不到其计算量1/4的情况下,其性能与RoBERTa和XLNet相当,在使用相同计算量的情况下优于它们。
我们的总结
BERT和XLNet等流行语言模型的预训练任务包括掩蔽未标记输入的一小部分,然后训练网络以恢复该原始输入。尽管它工作得很好,但这种方法并不是特别高效,因为它只从一小部分代币(通常约15%)中学习。作为一种替代方案,斯坦福大学和谷歌大脑的研究人员提出了一种新的预训练任务,称为替代令牌检测。他们建议用一个小语言模型生成的看似合理的替代品来代替屏蔽,而不是屏蔽。然后,使用预先训练的鉴别器来预测每个令牌是原始的还是替换的。因此,该模型从所有输入令牌中学习,而不是从小的掩码部分中学习,从而提高了计算效率。实验证实,所引入的方法在下游NLP任务上带来了显著更快的训练和更高的准确性。
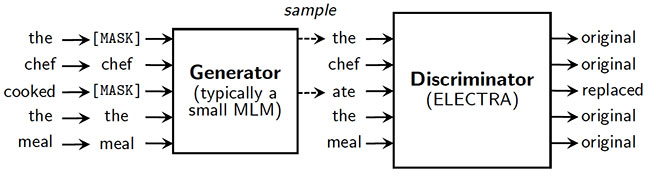
这篇论文的核心思想是什么?
- 基于掩蔽语言建模的预训练方法在计算上效率低下,因为它们只使用一小部分令牌进行学习。
- 研究人员提出了一种新的预训练任务,称为替换令牌检测,其中:
- 一些令牌被来自小型生成器网络的样本所取代;
- 将模型预先训练为鉴别器,以区分原始令牌和替换令牌。
- 引入的方法被称为ELECTRA(高效学习准确分类令牌替换的编码器):
- 使模型能够从所有输入令牌而不是小的屏蔽子集中学习;
- 尽管与GAN相似,但不是对抗性的,因为生成用于替换的令牌的生成器是以最大可能性训练的。
关键成就是什么?
- 证明区分真实数据和具有挑战性的负样本的判别任务比现有的语言表征学习生成方法更有效。
- 引入一种大大优于最先进方法的模型,同时需要更少的预训练计算:
- ELECTRA Small的GLUE得分为79.9,优于得分为75.1的相对较小的BERT模型和得分为78.8的大得多的GPT模型。
- 与XLNet和RoBERTa性能相当的ELECTRA模型只使用了其训练前计算的25%。
- ELECTRA Large在GLUE和SQuAD基准测试上的性能超过了其他最先进的模型,同时仍然需要更少的预训练计算。
人工智能界是怎么想的?
- 该论文被选中在ICLR 2020上发表,ICLR 2020是深度学习领域的领先会议。
什么是可能的业务应用程序?
- 由于其计算效率,ELECTRA方法可以使业务从业者更容易地使用预先训练的文本编码器。
从哪里可以获得实现代码?
- 最初的TensorFlow实现和预先训练的权重在GitHub上发布。
9、 DeBERTa: Decoding-enhanced BERT with Disentangled Attention,
by Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen
原始摘要
预训练神经语言模型的最新进展显著提高了许多自然语言处理(NLP)任务的性能。在本文中,我们提出了一种新的模型架构DeBERTa(具有解纠缠注意力的解码增强型BERT),该架构使用两种新技术改进了BERT和RoBERTa模型。第一种是解纠缠注意力机制,其中每个单词使用分别编码其内容和位置的两个向量来表示,并且单词之间的注意力权重分别使用关于其内容和相对位置的解纠缠矩阵来计算。其次,使用增强的掩码解码器在解码层中结合绝对位置,以预测模型预训练中的掩码令牌。此外,还采用了一种新的虚拟对抗性训练方法进行微调,以提高模型的泛化能力。我们表明,这些技术显著提高了模型预训练的效率,以及自然语言理解(NLU)和自然语言生成(NLG)下游任务的性能。与RoBERTa Large相比,在一半训练数据上训练的DeBERTa模型在广泛的NLP任务上始终表现更好,在MNLI上实现了+0.9%(90.2%对91.1%)的改进,在SQuAD v2.0上实现了+2.3%(88.4%对90.7%)的改进和在RACE上实现了+3.6%(83.2%对86.8%)的改进。值得注意的是,我们通过训练由48个具有15亿个参数的变换层组成的更大版本来放大DeBERTa。这一显著的性能提升使单个DeBERTa模型在宏观平均得分方面首次超过了人类在SuperGLUE基准上的表现(Wang et al.,2019a)(89.9对89.8),而截至2021年1月6日,整体DeBERTa模型位居SuperGLUE排行榜首位,以相当大的优势超过了人类基准(90.3对89.8。
我们的总结
微软研究公司的作者提出了DeBERTa,它比BERT有两个主要的改进,即消除纠缠的注意力和增强的掩码解码器。DeBERTa具有两个向量,分别通过对内容和相对位置进行编码来表示令牌/单词。DeBERTa中的自我注意机制处理内容对内容、内容对位置以及位置对内容的自我注意,而BERT中的自我关注相当于只有前两个组成部分。作者假设,位置到内容的自我关注也需要对令牌序列中的相对位置进行全面建模。此外,DeBERTa配备了增强型掩码解码器,其中令牌/字的绝对位置也与相对信息一起提供给解码器。DeBERTa的单一放大变体首次超过了SuperGLUE基准上的人类基线。在本出版物出版时,合奏DeBERTa是SuperGLUE上表现最好的方法。
这篇论文的核心思想是什么?
- 纠缠注意力:在原始BERT中,在自注意力之前添加了内容嵌入和位置嵌入,而自注意力仅应用于内容和位置向量的输出。作者假设,这只考虑了内容到内容的自我关注和内容到位置的自我关注,我们需要位置到内容的自关注以及对位置信息的完整建模。DeBERTa有两个表示内容和位置的独立向量,并且在所有可能的对之间计算自我关注,即内容到内容、内容到位置、位置到内容和位置到位置。位置到位置的自我注意一直是琐碎的1,并且没有信息,所以它没有被计算出来。
- 增强的掩码解码器:作者假设模型需要绝对的位置信息来理解句法上的细微差别,如主-客体特征。因此,DeBERTa被提供有绝对位置信息以及相对位置信息。绝对位置嵌入被提供给softmax层之前的最后一个解码器层,其给出输出。
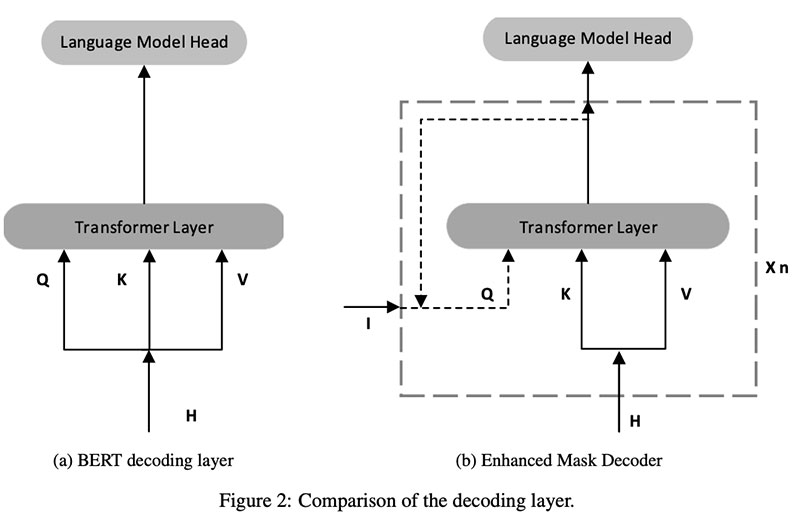
- 尺度不变微调:一种称为尺度不变微调的虚拟对抗性训练算法被用作正则化方法,以提高泛化能力。单词嵌入被扰动到很小的程度,并被训练以产生与在非扰动单词嵌入上相同的输出。单词嵌入向量被归一化为随机向量(其中向量中的元素之和为1),以对模型中的参数数量不变。
关键成就是什么?
- 与目前最先进的方法RoBERTa Large相比,在一半训练数据上训练的DeBERTA模型实现了:
- MNLI的准确性提高了+0.9%(91.1%对90.2%),
- 与SQuAD v2.0相比,准确率提高了+2.3%(90.7%对88.4%),
- RACE的准确率提高了+3.6%(86.8%对83.2%)
- DeBERTa的单个放大变体首次超过了SuperGLUE基准上的人类基线(89.9对89.8)。在本出版物发表时,DeBERTa是SuperGLUE上表现最好的方法,以相当大的优势超过了人类基线(90.3对89.8。
人工智能界是怎么想的?
- 该论文已被ICLR 2021接受,ICLR 2021是深度学习的关键会议之一。
未来的研究领域是什么?
- 使用增强掩码解码器(EMD)框架,通过引入除位置之外的其他有用信息来改进预训练。
- 对尺度不变微调(SiFT)进行了更全面的研究。
什么是可能的业务应用程序?
- 预训练语言建模的上下文表示可用于搜索、问答、摘要、虚拟助理和聊天机器人等任务。
从哪里可以获得实现代码?
- DeBERTa的实现可在GitHub上获得。
10. PaLM: Scaling Language Modeling with Pathways,
by Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, Noah Fiedel
原始摘要
大型语言模型已被证明使用少镜头学习在各种自然语言任务中实现了显著的性能,这大大减少了使模型适应特定应用所需的特定任务训练示例的数量。为了进一步理解规模对少镜头学习的影响,我们训练了一个5400亿参数、密集激活的Transformer语言模型,我们称之为Pathways语言模型PaLM。我们使用Pathways在6144 TPU v4芯片上训练了PaLM,Pathways是一种新的ML系统,可以在多个TPU吊舱上进行高效训练。我们通过在数百个语言理解和生成基准上实现最先进的少量学习结果,展示了扩展的持续优势。在许多这样的任务上,PaLM 540B实现了突破性的性能,在一套多步骤推理任务上优于微调后的最先进技术,在最近发布的BIG基准测试上优于平均人类性能。大量的BIG工作台任务显示出与模型规模相比的不连续改进,这意味着随着我们扩展到最大的模型,性能急剧提高。PaLM在多语言任务和源代码生成方面也具有强大的能力,我们在一系列基准测试中对此进行了演示。此外,我们还提供了关于偏倚和毒性的全面分析,并研究了训练数据记忆相对于模型规模的程度。最后,我们讨论了与大型语言模型相关的伦理考虑,并讨论了潜在的缓解策略。
我们的总结
谷歌研究团队在BERT、ALBERT和T5模型的预训练语言模型领域做出了很大贡献。他们的最新贡献之一是Pathways语言模型(PaLM),这是一个使用Pathways系统训练的5400亿参数、仅密集解码器的Transformer模型。Pathways系统的目标是协调加速器的分布式计算。在它的帮助下,该团队能够在多个TPU v4吊舱上高效地训练单个模型。hundre的实验
这篇论文的核心思想是什么?
- 本文的主要思想是利用Pathways系统对5400亿参数语言模型进行规模化训练:
- 该团队在两个Cloud TPU v4 Pod之间使用Pod级别的数据并行性,同时在每个Pod中使用标准数据和模型并行性。
- 他们能够将训练扩展到6144个TPU v4芯片,这是迄今为止用于训练的最大的基于TPU的系统配置。
- 该模型实现了57.8%的硬件FLOP利用率的训练效率,正如作者所声称的,这是该规模的大型语言模型迄今为止实现的最高训练效率。
- PaLM模型的训练数据包括英语和多语言数据集的组合,其中包含高质量的网络文档、书籍、维基百科、对话和GitHub代码。
关键成就是什么?
- 大量实验表明,随着团队规模扩大到他们最大的模型,模型性能急剧提高。
- PaLM 540B在多项非常困难的任务上取得了突破性的性能:
- 语言理解和生成。所引入的模型在29项任务中的28项上超过了先前大型模型的少镜头表现,这些任务包括问答任务、完形填空和句子完成任务、上下文阅读理解任务、常识推理任务、SuperGLUE任务等。PaLM在BIG工作台任务中的表现表明,它可以区分因果关系,并在适当的上下文中理解概念组合。
- 推理。在8次提示下,PaLM解决了GSM8K中58%的问题,GSM8K是数千道具有挑战性的小学级数学问题的基准,优于之前通过微调GPT-3 175B模型获得的55%的高分。PaLM还展示了在需要多步骤逻辑推理、世界知识和深入语言理解的复杂组合的情况下生成明确解释的能力。
- 代码生成。PaLM的性能与经过微调的Codex 12B不相上下,同时使用更少50倍的Python代码进行训练,这证实了大型语言模型更有效地转移了对其他编程语言和自然语言数据的学习。
未来的研究领域是什么?
- 将Pathways系统的扩展能力与新颖的架构选择和培训方案相结合。
什么是可能的业务应用程序?
- 与最近引入的其他预训练语言模型类似,PaLM可以应用于广泛的下游任务,包括会话人工智能、问答、机器翻译、文档分类、广告副本生成、代码错误修复等。
从哪里可以获得实现代码?
- 到目前为止,PaLM还没有正式的代码实现版本,但它实际上使用了标准的Transformer模型体系结构,并进行了一些定制。
- 可以在GitHub上访问PaLM中特定Transformer架构的Pytorch实现。
- 如果你喜欢这些研究摘要,你可能还会对以下文章感兴趣:
- 2020年度人工智能与机器学习研究论文
- GPT-3及以后:你应该阅读的10篇NLP研究论文
- 会话人工智能代理的最新突破
- 每一位NLP工程师都需要了解的关于预训练语言模型的知识
- 529 次浏览