技术选型
- 418 次浏览
【大数据架构】Apache Flink和Apache Spark—比较指南
1. 目标
在本教程中,我们将讨论Apache Spark和Apache Flink之间的比较。Apache spark和Apache Flink都是用于大规模批处理和流处理的开源平台,为分布式计算提供容错和数据分布。本指南提供了Apache Flink和Apache Spark这两种蓬勃发展的大数据技术在特性方面的明智比较。

2. Apache Flink vs Apache Spark
| Features | Apache Flink | Apache Spark |
|---|---|---|
| Computation Model | Flink基于基于操作器的计算模型。 | Spark是基于微批处理模式的。 |
| Streaming engine | Apache Flink为所有工作负载使用流:流、SQL、微批处理和批处理。批处理是流数据的有限集。 | Apache Spark对所有工作负载使用微批。但对于需要处理大量实时数据流并实时提供结果的用例来说,这是不够的。 |
| Iterative processing | Flink API提供了两个专用的迭代操作Iterate和Delta Iterate。 | Spark基于非本地迭代,在系统外部实现为规则的for - loop。 |
| Optimization | Apache Flink附带了一个独立于实际编程接口的优化器。 | 在Apache中,Spark作业必须手动优化。 |
| Latency | 通过最小的配置努力,Apache Flink的数据流运行时实现了低延迟和高吞吐量。 | 与Apache Flink相比,Apache Spark具有较高的延迟。 |
| Performance | 与其他数据处理系统相比,Apache Flink的总体性能非常出色。Apache Flink使用本地闭环迭代操作符,这使得机器学习和图形处理更快。 | 尽管Apache Spark拥有优秀的社区背景,现在它被认为是最成熟的社区。但是它的流处理效率并不比Apache Flink高,因为它使用微批处理。 |
| Fault tolerance | Apache Flink遵循的容错机制是基于Chandy-Lamport分布式快照的。该机制是轻量级的,从而在保持高吞吐率的同时提供了强大的一致性保证。 | Spark 流恢复丢失的工作,并提供精确的一次性语义开箱即用,没有额外的代码或配置。(请参阅火花容错特征指南) |
| Duplicate elimination | Apache Flink一次处理每条记录,因此消除了重复。 | Spark还精确地处理每条记录一次,因此消除了重复。 |
| Window Criteria | Flink具有基于记录或任何自定义用户定义的窗口条件。 | Spark有一个基于时间的窗口条件 |
| Memory -Management | Flink提供自动内存管理。 | Spark提供可配置的内存管理。Spark 1.6, Spark也已经转向自动化内存管理。 |
| Speed | Flink以闪电般的速度处理数据 | Spark的处理模型比Flink慢 |
3.结论
Apache Spark和Flink都是吸引业界关注的下一代大数据工具。两者都提供与Hadoop和NoSQL数据库的本地连接,并且可以处理HDFS数据。两者都是几个大数据问题的好解决方案。但由于其底层架构,Flink比Spark更快。Apache Spark是Apache存储库中最活跃的组件。Spark拥有非常强大的社区支持和大量的贡献者。Spark已经部署在生产环境中。但就流功能而言,Flink要比Spark好得多(因为Spark以微批的形式处理流),并且对流有本地支持。Spark被认为是大数据的3G,而Flink被认为是大数据的4G。
原文:https://data-flair.training/blogs/comparison-apache-flink-vs-apache-spark/
本文:http://jiagoushi.pro/node/1121
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 465 次浏览
【技术选型】AMQP vs MQTT
视频号

微信公众号

知识星球


AMQP和MQTT之间的差异
在过去的几十年中,用于消息异步排队的开源协议是AMQP与MQTT。最近,它已经适应了新的更新。AMQP打算成为国际标准组织或国际电化学委员会的一部分,并由OASIS选择,MQTT已采用Eclipse。AMQP使用wire执行其消息队列。因此,它是有线协议,在网络上被转换成大量的字节值。MQTT是为带宽最小的有限设备开发的。它是一个轻量级的广播系统,用户可以像客户端一样传输和接收消息。
AMQP和MQTT之间的正面比较
以下是AMQP与MQTT之间的14个最大差异:

AMQP和MQTT之间的关键区别
AMQP和MQTT都用于物联网。但是,让我们讨论一下主要的区别:
- MQTT具有客户机/代理体系结构,而AMQP具有客户机或代理以及客户机或服务器体系结构。
- MQTT遵循发布和订阅的抽象,而AMQP遵循响应或请求以及发布或订阅方法。
- AMQP的头大小为8bytes,MQTT的头大小为2bytes。MQTT的消息大小很小且已定义,而AMQP具有可协商的和未定义的。
- MQTT的方法是connected、publish、close、subscribe和disconnect。AMQP遵循Consume, deliver, publish, get, select, acknowledge, delete, recover, reject, open, and close.
- MQTT部分支持缓存和代理,而AMQP则提供完全支持。
- AMQP和MQTT都遵循TCP协议、二进制标准和开源队列系统。
- AMQP提供的安全性是IPSec、SASL、TLS或SSL,而MQTT只提供TLS或SSL安全标准。AMQP和TCP一起使用SCTP进行传输。OASIS同时支持AMQP和MQTT。
-
MQTT提供的服务质量是fire和forget,如果QoS为0。如果QoS为1,则至少有一个,如果QoS为2,则正好有一个。AMQP提供的服务质量是与MQTT类似的结算和取消结算格式。
AMPQ与MQTT比较表
以下是AMQP与MQTT之间的比较:
| 比较的基础 | AMQP | MQTT |
| 定义 | AMQP被扩展为高级消息队列协议。AMQP提供了更丰富的消息传递环境。 | MQTT定义为消息队列遥测传输。它提供了一种简单的消息队列服务方式,主要在嵌入式系统中实现. |
| 背景
|
AMQP是由金融集团开发的一个开源的、客户驱动的队列。在没有任何定制的情况下,它在市场上一天天地在进步。 | MQTT主要由供应商驱动并由IBM开发,实现成本很高。 |
| 设计协议
|
AMQP使用TCP进行消息的异步传输,而不管选择什么操作系统、硬件或编程语言。它提供了具有完全生命力的消息传递服务。AMQP在网络用户和基础设施资源的不同控制下运行。 | 与AMQP类似,MQTT在异步方法中使用TCP共享消息,而不依赖于任何属性。它是专门为在网络的最小带宽上运行的小型设备设计的。MQTT将复杂的各方视为由附近的私有基础设施管理的。 |
| 框架的优化
|
它在数据帧的连线上进行了高级优化,有一种提高服务器性能的缓冲方法。 | 它还基于线(Wire)框架,它使用类似流的方法来执行帧的最小内存设备。它不允许批量传输消息。 |
| 消息服务 | AMQP应用于5个不同的属性中,比如不影响生存期的发布者-订阅者,只要它需要,它就保持在队列中,如果没有人使用队列,它就保持不变。它支持各种消息传递循环、经典或传统消息队列、组合以及保存和转发。它执行元数据消息来帮助幂等消息和消息分组。 | 基于内容的发布和订阅消息传递,并且是高度瞬变的。它主要用于主动路由因此链接的订阅者和发布者。它在传统的延长生命周期消息队列中应用有限。 |
| 消息的事务 | 它支持不同的确认、事务、用例以及整个消息队列。它支持分解各种事务代码,并且在有延迟时确认过期以调整性能。 | MQTT不支持任何类型的事务。它只支持一般承认。 |
| 连接的安全 | AMQP与TLS和SASL是统一的,并且使用特殊的特性来使用连接。它能够消除SASL和TLS策略,并通过不断的更新来提高性能。 | MQTT不会处理任何连接中的安全问题。 |
| 用户的安全 | AMQP利用SASL方法来选择安全性,而不需要改变协议。它为相同网络中的组件提供不同的名称。因此,这个特性使我们能够使用嵌套的防火墙和看门人。在广播任何消息之前,它将与用户进行身份验证。 | MQTT需要较小的用户名和最低密码,并且在这个趋势期间不设置任何预防措施。 |
| Last value queues | 它不支持队列中的最后一个值。 | 它提供Retain命令并支持队列中的最后一个值。 |
| 消息可靠性 | 它只启用触发和遗忘策略。一旦接收到,就无法检索。 | 它类似于AMQP,数据传递太可靠了。 |
|
消息的 命名空间 |
它允许以多种方式查找节点和队列等消息。 | 它在消息的分层传输中使用“名称空间”。 |
| 附加的属性 | AMQP支持对等连接,并允许整个网络的负载平衡,它是多路复用的。它可以使用容器,主题是双对称的。 | MQTT为DNS服务器提供了基本要求。MQTT是不对称的,不支持任何高级特性。 |
| 实现 | AMQP是在小于64kb RAM的组件中实现的。 | 它是开源库中的一个较小的协议,在RAM小于64kb的设备中实现 |
| 可扩展性 | 它的结构点允许在特定的供应商中进行扩展,并同意即将采用的不兼容扩展的方式。它允许通过隔离在层中进行更改。 | MQTT需要一个完整的协议草案。 |
结论
虽然AMQP和MQTT在体系结构和协议上有很多不同,但它们在物联网等各种应用中得到了广泛的应用。作为开源协议,AMQP和MQTT都可以根据客户机需求和可用带宽应用于所有应用程序。
本文:http://jiagoushi.pro/node/1126
讨论:请加入知识星球【首席架构师圈】或者小号【ca_cea】
- 3051 次浏览
【技术选型】AWS 和 AZURE的全面比较
视频号
微信公众号
知识星球

AWS和AZURE之间的区别
亚马逊网络服务(AWS)是亚马逊的一个云服务平台,提供不同领域的服务,如计算、存储、交付和其他功能,帮助业务规模和增长。我们可以以服务的形式利用这些域,这些服务可用于在云平台中创建和部署不同类型的应用程序。微软Azure是微软的一个云服务平台,它在不同的领域提供服务,如计算、存储、数据库、网络、开发工具和其他功能,帮助组织扩大和增长他们的业务。Azure服务被广泛地分为平台即服务(PaaS)、软件即服务(SaaS)和基础设施即服务(IaaS),这些服务可被开发人员和软件员工通过云来创建、部署和管理服务和应用程序。
AWS是什么?
AWS服务被设计成可以相互协作并产生可伸缩且高效的结果的方式。AWS提供的服务分为三类,如基础设施即服务(IaaS)、软件即服务(SaaS)和平台即服务(PaaS)。AWS于2006年推出,成为目前可用的云平台中最好的云平台。云平台提供了各种优势,比如降低管理开销、最小化成本等等。
AZURE是什么?
微软Azure于2010年推出,成为最大的商业云服务提供商之一。它提供了广泛的集成云服务和功能,如分析、计算、网络、数据库、存储、移动和web应用程序,它们与您的环境无缝集成,以实现效率和可伸缩性。
AWS和AZURE的正面比较(信息图)
下面是AWS和AZURE之间的6大比较
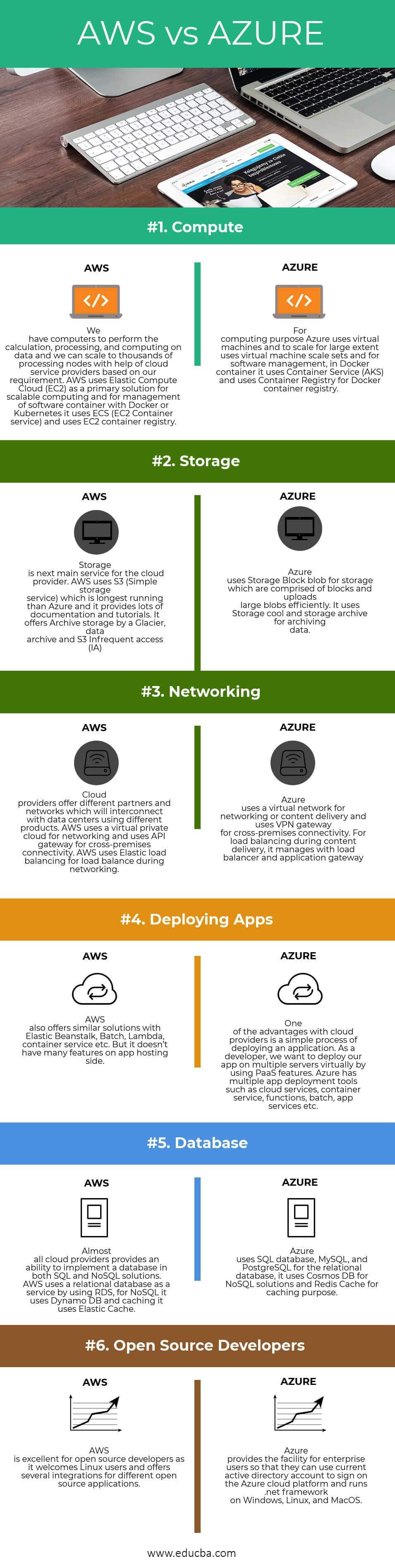
AWS和Azure的主要区别
两者都是市场上的热门选择;让我们来讨论一下主要的区别:
- AWS EC2用户可以配置他们自己的虚拟机或预配置的映像,而Azure用户需要选择虚拟硬盘来创建由第三方预配置的虚拟机,并需要指定所需的核数和内存。
- AWS提供在实例启动时分配的临时存储,在实例终止时分配的临时存储,S3提供对象存储。而Azure通过页blob为VM提供块存储,通过块存储为对象存储提供临时存储。
- AWS提供虚拟私有云,这样用户就可以在云中创建隔离的网络,而Azure提供虚拟网络,通过它我们可以创建隔离的网络、子网、路由表、私有IP地址范围,就像AWS一样。
- Azure对混合云系统开放,而AWS对私有或第三方云提供商不那么开放。
- AWS是按小时计费的,而Azure是按分钟计费的,它提供了比AWS更精确的定价模式。
- AWS有更多的特性和配置,它提供了大量的灵活性、功能和定制,并支持许多第三方工具的集成。然而,如果我们熟悉windows, Azure会很容易使用,因为它是一个windows平台,很容易集成本地windows服务器和云实例来创建一个混合环境。
AWS vs AZURE对照表
以下是要点列表,描述比较:
| 比较点 | AWS | AZURE |
| 计算 | 我们有计算机来进行数据的计算、处理和计算,我们可以根据我们的需求在云服务提供商的帮助下扩展到数千个处理节点。AWS使用弹性计算云(EC2)作为可伸缩计算和管理Docker或Kubernetes软件容器的主要解决方案,它使用ECS (EC2容器服务)和EC2容器注册。 | Azure在计算方面使用虚拟机,在很大程度上使用虚拟机规模集,在软件管理方面,在Docker container中使用container Service (AKS),在Docker container Registry中使用container Registry。 |
| 存储 | 存储位于云提供商的主要服务旁边。AWS使用S3(简单存储服务),它比Azure运行时间长,并且提供了大量的文档和教程。它提供冰川存档存储、数据存档和S3不频繁访问(IA)。 | Azure使用存储块blob进行存储,存储由块组成,可以高效地上传大的blob。它使用存储冷却和存储归档来归档数据。 |
| 网络 | 云提供商提供不同的合作伙伴和网络,这些合作伙伴和网络将与使用不同产品的数据中心相互连接。AWS使用虚拟私有云进行网络连接,并使用API网关进行跨场所连接。AWS使用弹性负载平衡来实现联网期间的负载平衡。 | Azure使用虚拟网络进行联网或内容交付,并使用VPN网关进行跨场所连接。为了实现内容传递过程中的负载均衡,它使用负载均衡器和应用程序网关进行管理 |
| 部署应用 | AWS也提供了类似的解决方案,包括弹性的Beanstalk、批处理、Lambda、容器服务等。但它在应用托管端没有很多功能。 | 云提供商的优势之一是部署应用程序的过程很简单。作为一名开发人员,我们希望通过使用PaaS特性虚拟地将我们的应用程序部署到多个服务器上。Azure拥有云服务、容器服务、功能、批处理、app服务等多种应用部署工具。 |
| 数据库 | 几乎所有的云提供商都提供了在SQL和NoSQL解决方案中实现数据库的能力。AWS通过使用RDS使用关系数据库作为服务,对于NoSQL,它使用Dynamo DB,缓存使用弹性缓存。 | Azure使用SQL数据库,MySQL和PostgreSQL作为关系数据库,使用Cosmos DB作为NoSQL解决方案,使用Redis Cache作为缓存目的。 |
| 开源开发 | AWS非常适合开放源码开发人员,因为它欢迎Linux用户,并为不同的开放源码应用程序提供了几种集成。 | Azure为企业用户提供了这个工具,这样他们就可以使用当前的active directory帐户在Azure云平台上签名,并在Windows、Linux和MacOS上运行。net框架。 |
结论
最后,概述AWS和AZURE云提供商之间的差异。我希望您能更好地了解AWS和AZURE提供商提供的服务,并根据您的需求选择云提供商。如果您正在寻找作为服务的基础设施或广泛的服务和工具,那么您可以选择AWS。如果您正在寻找windows集成或良好的平台服务(PaaS)云提供商,那么您可以选择Azure。
本文:https://jiagoushi.pro/node/1133
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 2400 次浏览
【技术选型】Cloudflare vs CloudFront
Cloudflare和CloudFront的区别
作为世界上最大的网络之一,Cloudflare提供的服务增加了网站和应用程序的安全和性能问题。在早期,当使用Internet并试图访问网站或web信息时,最初需要从系统向服务器发送请求,这将根据需要反映所需的输出。但有时会出现系统崩溃的情况,或者当大量请求同时到达承载数据的服务器时,系统变得无响应。为了克服这些困难,使他们的网站和应用程序安全可靠,他们使用了Cloudflare服务。Cloudflare通过保护互联网属性不受恶意攻击、恶意程序等的攻击来提供安全保障。
然而,云前端是一个内容分发网络(CDN),它提供了一个全球分布的代理服务器网络,这些代理服务器缓存内容,从而提高了下载内容的速度性能。Cloud Front的工作模式是“按使用付费”。
Cloudflare与CloudFront的正面比较(信息图表)
以下是Cloudflare和CloudFront之间的十大区别:
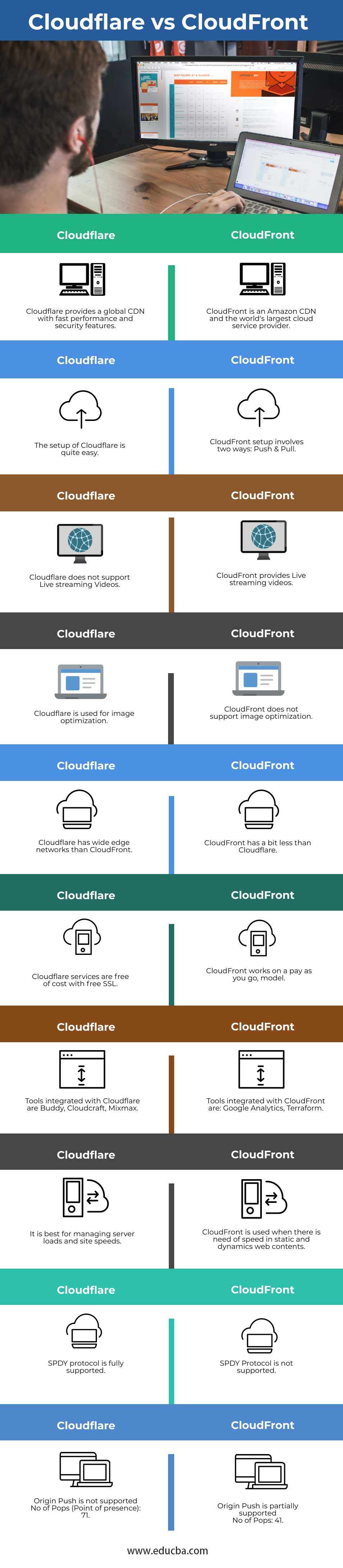
Cloudflare与CloudFront的主要区别
以下是Cloudflare与CloudFront的主要区别:
Cloudflare
Cloudflare采用反向代理的方式工作,我们用Cloudflare建立了一个站点;它把名字服务器给了Cloudflare。这使得Cloudflare能够控制您的站点,并将所有流量驱动到您的站点。Cloudflare也提供了许多CDN之外的其他功能。
当任何人访问您的网站时,Cloudflare将获取静态内容并将数据存储在世界各地的各种Cloudflare网络上,以便从他们需要的位置访问。
Cloudflare的设置包括以下步骤:
- 注册Cloudflare账户。
- 启动“添加站点”向导。
- 更改您的域名服务器(由于反向代理方法
- 一旦完成,我们就可以从仪表板上访问和管理Cloudflare设置。
Cloudflare提供的其他服务包括:
- 免费SSL证书(但它的共享版本)
- DDoS保护
- Web应用程序防火墙
- 图像优化
- 移动优化
CloudFront
CloudFront是一种CDN,它通过一个称为边缘位置的网络来传递数据,从而在用户提前请求数据时能够快速访问数据、低延迟、低网络流量。
在这里,我们不需要更改Cloudflare这样的名称服务器。云锋采用推拉方式。CloudFront自动从原始位置提取您的数据,并将其放到全球各个服务器网络上。Cloudflare与CloudFront的主要区别如下:
就像Cloudflare控制名称服务器一样,CloudFront没有这样做,因为它不能自动为任何站点提供来自任何边缘位置的内容。这就需要一个单独的URL来发挥作用,即cdn.yoursite.com(最近的CloudFront Edge服务器),在这里,yoursite.com被Cloudflare称为。
对CloudFront和Cloudflare的偏好
- Cloudflare的设置过程比CloudFront简单。
- Cloudflare的边缘网络略大于CloudFront。
- WordPress火箭提供了一个专门的Cloudflare集成。
CloudFront提供了一些WordPress不太需要的特性,比如:
- 它提供了对HTTP报头和缓存无效的控制。
- CloudFront使用实时流媒体。
Cloudflare与CloudFront的对比表
让我们来讨论一下Cloudflare和CloudFront之间的顶级比较:
|
Cloudflare |
CloudFront |
| Cloudflare提供了一个具有快速性能和安全特性的全球CDN。 | CloudFront是亚马逊的CDN,也是世界上最大的云服务提供商。 |
| Cloudflare的设置非常简单 | CloudFront的设置包括两种方式:推和拉 |
| Cloudflare不支持流媒体视频直播 | CloudFront提供实时流媒体视频 |
| Cloudflare用于图像优化 | CloudFront不支持图像优化。 |
| Cloudflare拥有比CloudFront更广泛的边缘网络。 | CloudFront的数据略低于Cloudflare。 |
| Cloudflare提供免费的SSL服务 | CloudFront的付费模式是按需付费 |
| 与Cloudflare集成的工具有Buddy、Cloudcraft、Mixmax。 | 与CloudFront集成的工具有:谷歌Analytics、Terraform |
| 它最适合管理服务器负载和站点速度。 | 当静态和动态web内容需要速度时,就会使用CloudFront |
| 完全支持SPDY协议 | 不支持SPDY协议 |
|
不支持原始推送
No of Pops (入网点): 71 |
原始推送被部分支持
No of Pops: 41 |
除了以上这些比较之外,Cloudflare的界面要比CloudFront好得多。Cloudflare提供24/7的电话和电子邮件支持,而CloudFront也提供同样的支持,但包含了额外的费用。Cloudflare并不是一个真正的CDN,而是一个接收总体流量的反向代理,CloudFront是一种既适合静态内容又适合动态内容的高级CDN。Cloudflare主要由FounderLY、Stack Overflow和Code Guard使用。CloudFront没有公布网络容量,因为它的规模很大,而Cloudflare的网络容量为15Tbps。
结论
Cloudflare和CloudFront提供CDN服务,可以加速您的网站页面的性能,降低服务器的负载。大多数WordPress用户都使用Cloudflare简单的设置过程,而CloudFront则不使用。与两者相比,Cloudflare在提供服务和安全方面提供了比CloudFront更好的选择。
CloudFront作为一种更快的内容交付服务,为最终用户提供了内容的可靠性和可用性,而Cloudflare在其发布的高峰期提供了不安全的互联网协议的安全版本,并通过安全HTTPS服务(通用SSL)免费提供这些协议。因此,Cloudflare为所有终端用户提供了一个可靠、快速和安全的互联网。因此CloudFront和Cloudflare都适合用户,并根据用户的需要和要求进行应用。因此,Cloudflare比CloudFront更加灵活可靠。
原文:https://www.educba.com/cloudflare-vs-cloudfront
本文:http://jiagoushi.pro/node/1132
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 2091 次浏览
【技术选型】Elasticsearch vs. Solr -选择开源搜索引擎
我们为什么在这里?我存在的目的是什么?我应该锻炼还是休息以节省精力?早起上班还是开始工作到很晚?我吃薯条要加蕃茄酱还是蛋黄酱?
这些都是古老的问题,可能有也可能没有答案。其中一些非常难,或者非常主观。但我还是要花点时间来回答其中一个问题:我应该用Elasticsearch还是Solr?
这是一个场景。您的组织希望实现您的第一个搜索引擎,切换到另一个搜索引擎-呼叫所有谷歌搜索设备(GSA)用户寻找替代品!——或者尝试通过开源来节省资金。您,作为一个熟练和有能力的开发人员,被要求解决一个难题。您的问题有许多业务需求,但其核心是一个“大数据和搜索”问题。
您需要从多个数据源提取大量内容,并从这些数据中获得洞察力,以帮助您的公司增长并实现今年的目标。
管中窥豹
这里有很多利害关系。你不会错过的,你只有一次机会。您需要合适的搜索引擎,您考虑的是开源,您有两个流行的选择:Elasticsearch或Solr,根据db - engine的说法,这两个搜索引擎在开源和商业搜索引擎中稳居前两名。

你会选择哪个开源搜索引擎?
这不是掷硬币或简单的选择。这两个搜索引擎都很棒,但没有一个“正确”的选择。这完全取决于你的需求。
因此,第一步是理解必须构建的应用程序。然后,下一步是看看每个搜索引擎都能提供什么。顺便说一句,如果你还处在开源和商业解决方案的交叉点,请阅读我们的免费电子书,深入了解在选择搜索引擎时要考虑的10个关键标准。
功能纲要
几年前,我们写了一个关于Elasticsearch与Solr的高级概览博客,其中讨论了总体趋势和非技术见解。现在,随着Elasticsearch和已发展成为开源搜索引擎市场的主导玩家,让我们重新审视一下它们,看看它将带给我们什么。
年龄和成熟
在这种情况下,我们可以说Solr有更长的历史,因为它是由CNET Networks的Yonik Seely在2004年创建的,然后在2006年将其贡献给Apache。2007年,它最终成为一个顶级项目。另一方面,我们有Elasticsearch,它是在2010年正式创建的,虽然它实际上是在2001年由其创始人Shay Bannon以Compass的名义创建的。从那时起,Kibana、Logstash和Beats的创建者加入了Elasticsearch,创建了Elastic Stack产品家族,成为搜索和日志分析领域的强大玩家。也就是说,Solr的优势在于能够更早地出现在市场中。
社区和开源
两者都有非常活跃的社区。如果你查看Github,你会发现它们是非常流行的开源项目,发布了很多版本。

一个非常重要的细节是,虽然两者都是在Apache许可下发布的,而且都是开源的,但它们的工作方式略有不同。Solr确实是开源的——任何人都可以提供帮助和贡献。有了Elasticsearch,虽然人们仍然可以提供他们的贡献,但只有Elastic的员工(创建Elasticsearch和Elastic Stack的公司)可以接受这些贡献。
这是好事还是坏事?这取决于你怎么看它。这意味着,如果您需要一种特性并将其贡献给社区,并且具有足够的质量,那么Solr可以接受它。在Elasticsearch中,由Elastic决定某个贡献是否被接受。所以Solr上可能有更多的特性选项。另一方面,对于Elasticsearch的贡献,通过更多级别的质量检查,可以提供更高的一致性和质量。
文档
Elasticsearch和Solr都有非常完善的参考指南。Elasticsearch运行在Github之上,Solr使用Atlassian Confluence。你可以通过下面的链接找到它们。
核心技术
让我们更专业一点。Elasticsearch和Solr是两种不同的搜索引擎。但在底层,它们都使用Lucene,这意味着它们都构建在“巨人的肩膀上”。
对于那些想知道为什么我认为Lucene是一个“巨人”的人,它实际上是许多搜索引擎背后的信息检索软件库。它非常快,稳定,可能没有比这更好的了。Lucene是由Hadoop的创始人之一Doug Cutting在1999年创建的。所以,Lucene是用于搜索引擎核心的完美选择。
Java API和REST
Elasticsearch有一个更“Web 2.0”的REST API,但是Solr有一个更好的Java API,使用SolrJ——或者使用Microsoft技术的SolrNet。Elasticsearch有Nest和Elasticsearch.Net。Solr的REST API可能感觉不太灵活,但它对于您所需要的:索引和查询非常有效。Elasticsearch使用的是JSON,所以如果您使用JSON,那么它是一个很好的选择。Solr也支持JSON,但它是在后期添加的,最初是为XML设计的。
内容处理
因为它们都公开API,所以很容易从自定义应用程序或现有的可配置应用程序索引内容。例如,我们的Aspire内容处理框架能够连接到多个数据源并post到Elasticsearch或Solr。
Solr还有一个特性,可以使用Apache Tika从二进制文件中提取文本。因此,您可以通过ExtractRequestHandler上传PDF文件,Solr将知道如何处理它。
另一方面,Elasticsearch与Logstash合作得很好,它可以处理来自任何来源的数据并为其建立索引。
可伸缩性
伸缩性是一个关键的考虑因素。在这种情况下,当Solr仍然被限制为主从关系时,Elasticsearch将赢得比赛。然而,SolrCloud最近加入了这个游戏。在Zookeeper的帮助下,现在可以以更简单、更快的方式扩展Solr集群—这是对旧版本的Solr的增强,它具有主从功能。它仍然需要大量的改进,但是从Solr中可摄取和搜索的数据集的大小来看,它的前景是光明的。
供应商支持
有几家公司已经到了必须决定哪种产品最适合自己的地步。例如,Cloudera选择Solr作为他们的搜索引擎,将其集成到开源的CDH(包括Hadoop的Cloudera发行版)中。另一方面,也有其他厂商选择Elasticsearch作为其解决方案的搜索引擎。我们在搜索技术帮助咨询,部署和支持这两个搜索引擎。
远景与生态系统
Solr更倾向于文本搜索。Elasticsearch迅速开拓了自己的小众市场,通过创建Elastic堆栈(以前称为ELK堆栈)来实现日志分析,Elastic Stack代表Elasticsearch、Logstash、Kibana和Beats。双方都有清晰的愿景,正在朝着各自的方向大步前进。
值得重申的一点是,这两个搜索引擎如何被用作许多领先的搜索和大数据平台的基础。例如,Elasticsearch是微软Azure搜索的一部分,而Solr已经集成到Cloudera搜索中。
性能
说到性能,根据我从许多开发人员那里听到的经验,我们可以说这两个引擎的性能都很好。因此,对于大多数用例,无论是内部的还是外部的搜索应用程序,如果开发人员正确地设计和配置它们,性能将不是什么大问题。
网络管理
Solr捆绑了web管理,而Elasticsearch有多个用于安全性、警报和监视的高级插件。这个列表展示了Elastic的整个产品系列。
可视化
在Elasticsearch和Solr中有许多可视化数据的方法——您可以构建自定义可视化仪表板,或者使用搜索引擎的标准可视化特性,可能需要做一些调整。但有一个区别值得一提。
Solr主要关注文本搜索。它在这方面做得很好,成为了搜索应用程序的标准。但是Elasticsearch已经向不同的方向发展,它已经超越了搜索,使用Elastic堆栈处理日志分析和可视化。下面是一些你可以用Kibana 5实现的可视化。

这并不意味着一个比另一个好。它只是表明,每个搜索引擎在不同的用例和需求中都有自己的优势,而您的选择将在很大程度上取决于您的组织想要实现什么。
长话短说,Elasticsearch和Solr都是优秀的开源选择,它们将帮助您从数据中获得更多信息。这完全取决于您的需求、预算、时间安排和项目的复杂性。
原文:https://www.searchtechnologies.com/blog/solr-vs-elasticsearch-top-open-source-search
本文:http://jiagoushi.pro/node/1152
讨论:请加入知识星球【首席架构师圈】或者微信【jiagoushi_pro】
- 70 次浏览
【技术选型】Keras、TensorFlow和PyTorch的区别
视频号
微信公众号
知识星球
数据科学家在深度学习中选择的最顶尖的三个开源库框架是PyTorch、TensorFlow和Keras。Keras是一个用python脚本编写的神经网络库,可以在TensorFlow的顶层执行。它是专门为深度神经网络的鲁棒执行而设计的。TensorFlow是一种在数据流编程和机器学习应用中用于执行多个任务的工具。PyTorch是一个用于自然语言处理的机器学习库。
Keras、TensorFlow和PyTorch的头对头比较(Infographics)
以下是Keras与TensorFlow和Pytorch之间的十大区别:

Keras与TensorFlow与PyTorch的关键区别
下面列出了Keras、TensorFlow和PyTorch的体系结构、函数、编程和各种属性等主要区别。
- API级别:Keras是一种高级的API,可以运行在Theano、CNTK和TensorFlow的顶层,后者因其快速开发和语法简单而受到关注。TensorFlow可以在API的低级别和高级别上工作,而PyTorch只能在API的低级别上工作。
- 框架的架构和性能:Keras的架构简单、简洁、易读,性能低下。TensorFlow是刚性使用,但支持Keras更好的表现。与Keras相比,PyTorch的架构复杂且难以解释。但TensorFlow 和PyTorch 的性能是健壮的,这提供了最大的性能,也提供了在更大的数据集高效率。由于Keras的性能较低,它只适用于较小的数据集。
- 调试过程:一个简单网络的调试是由Keras提供的,这是经常需要的。但是在TensorFlow中,调试是一个非常复杂的过程,而与Keras和TensorFlow相比,PyTorch提供了灵活的调试功能。PyTorch在神经网络中的操作描述了PyCharm、ipdb、PDB等调试工具的有效计算时间。但是当涉及到TensorFlow时,有一个叫做tfdbg的高级选项,它可以通过浏览所有的张量在特定的运行时在会话范围内操作。由于它是用python代码内建的,所以不需要单独使用PDB。TensorFlow在模式上比PyTorch先进,具有比PyTorch和Keras更广泛的群体。
- 框架的适用性。: Keras在小数据集中是首选,它提供了快速原型和扩展的大量后端支持,而TensorFlow在对象检测方面提供了高性能和功能,可以在大数据集中实现。PyTorch具有较强的灵活性和调试能力,可以在最短的数据集训练时间内适应。
- 神经网络框架的性能:PyTorch具有开发递归网络的多层和细胞级类。层的对象管理输入数据和一个单位单元中的一个时间步长,也表示具有双向属性的RNN。因此,由于没有进一步优化的必要,网络的众多层为单元提供了一个合适的包装。TensorFlow由dropout包装器、多个RNN单元和单元级类组成,用于实现深度神经网络。Keras由全连接层、GRU和用于创建递归神经网络的LSTM组成。
Keras与TensorFlow与PyTorch的对比表
以下是TensorFlow和Spark之间的十大区别:
| 行为参数 | Keras | TensorFlow | PyTorch |
| 定义 | 神经网络库是开源的。 | TensorFlow是一个开源和免费的软件库 | 这是一个开放源码的机器学习库。 |
| 编程语言 | 它可以作为编码来使用。所有代码都脚本化在一行中。 | 这个库与C、c++、Java和其他编码语言很紧凑。用小的代码对其进行编程,可以提高其准确性。 | 它仅使用python编写脚本。PyTorch的密码有更大的脚本。 |
| 应用 | 它被设计用于在神经网络中进行鲁棒性实验。 | 它被用来教机器多种计算技术 | 它被用于构建自然语言处理和神经网络。 |
| API的层级 | 它可以在Theano和CNTK上执行,因为它有高级API | 它包括低级和高级API | PyTorch只关注数组表达式,因为它的API很低。 |
| 架构 | 它有一个可理解的语法,可以很容易地解释。 | 它以其在各种平台上的快速计算能力而不具有难以解释的复杂体系结构而受到广泛欢迎 | 初学者觉得PyTorch的架构很复杂,但他们对它的深度学习应用程序很感兴趣,也用于各种学术目的。 |
| 速度 | 它仅以最低速度运行 | 它工作在最大速度,轮流提供高性能 | PyTorch的性能和速度与TensorFlow相似。 |
| 数据集 | 由于执行速度较慢,因此在较小的数据集中可以有效地运行。 | 它具有管理大型数据集的高度能力,因为它具有最大的执行速度 | 它可以在更高维度数据集中管理高性能任务。 |
| 调试 | 管理员不需要任何频繁的调试过程 | 执行调试是一项挑战。 | 它的调试能力比Keras和TensorFlow要好 |
| 流行度 | 它广泛应用于神经网络中,支持卷积层和效用层。 | 它以其自动图像捕捉软件和内部使用的谷歌而闻名。 | 它在深度学习网络上的自动分化,支持高功率GPU应用,包括神经网络模块、优化模块和autograd模块。 |
| 判决 | 它提供了多种后端支持和健壮的原型。 | 在大数据集上的高性能和功能的目标检测。 | 灵活性。培训的时间很短。具有多种调试功能。 |
结论
PyTorch简单且用户友好,而TensorFlow由于API不全面而被采用。Keras和TensorFlow有一个坚固的砖墙,但剩下的小孔用于通信,而PyTorch与Python紧密绑定,适用于许多应用程序。
推荐的文章
这是Keras vs TensorFlow vs PyTorch的指南。本文讨论了Keras、TensorFlow和PyTorch之间的区别,以及与信息图和比较表的头对头比较。你也可以通过我们的其他相关文章了解更多-
- Python与Groovy
- TensorFlow vs Spark
- Kafka和 Spark
- Apache Kafka vs Flume
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 4343 次浏览
【技术选型】OLTP vs OLAP
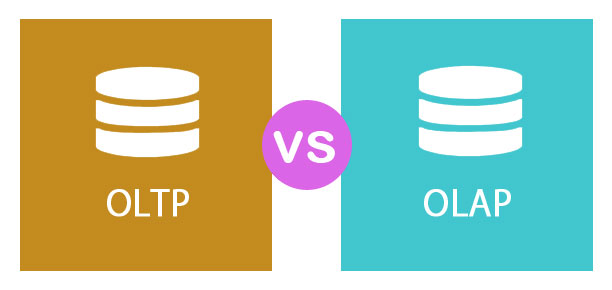
OLTP和OLAP的区别
OLTP被扩展为在线事务处理,OLAP被扩展为在线分析处理。顾名思义,OLTP是管理和更新数据库中的事务的过程,而OLAP是从数据库中检索所需数据以便将其用于分析操作的过程。OLTP通常很简单,在系统中可以轻松查询,而OLAP是一个复杂的系统,具有更大的数据量,因此需要复杂的查询。
联机事务处理(OLTP)
为了让大型/中型公司执行他们的行政/业务或销售任务,必须有OLTP系统,以处理每天发生的大量交易。
例子
OLTP系统的一个例子是大型杂货店。例如,一个人买了15件商品,到柜台结账。现在是OLTP系统来处理将要发生的事务。让我们计算一下可能发生的事务的数量。
- 第一个应该是将要生成并存储在DB中的账单的发票
- 第二个事务可能是针对发票在数据库中插入产品信息。
- 如果客户有任何会员卡,如果他使用它,交易将发生从他的卡扣除积分,并将更新他的卡的新积分。
- 另一种交易是根据客户购买的产品数量来减少产品的总数。例如,如果超市有3489包凝乳包,而客户购买了其中的2包,将发生一个交易,该交易将把总数更新为3489减2,即3487。类似的交易也会发生在其他产品上。
OLTP系统的几个例子是:
- 自动取款机
- 银行
- 购物中心
- 在线预订火车和航班
- 电子商务
联机分析处理(OLAP)
在OLAP级别上发生的事务非常少,它们有助于企业做出更好的决策。OLAP系统允许用户分析来自多个数据库的数据,ETL被强制作为来自不同数据库的数据的原因是不同的格式。因此,在将它们存储到数据仓库之前,需要使用ETL。
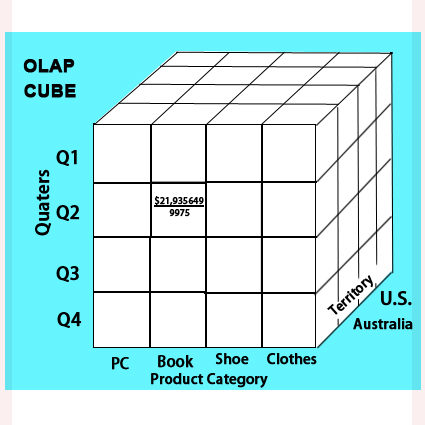
例子
电子商务公司想要比较2月和3月的销售数据,也想看到销售区域明智,然后是州明智,时间明智,最后是国家明智。
为了实现这一点,应该有一个系统可以将来自不同OLTP数据库的数据插入数据仓库并应用ETL过程。然后OLAP开发人员将从OLAP系统中获取数据,并根据业务需求创建不同类型的报告和图表。OLAP软件的例子有:SAP BI/BO/BOBJ,微软的Power BI, Tableau, Spotify, SAS, Python和R, Excel, Apache Spark, Splunk,谷歌Analytics。
OLTP和OLAP(信息图)的比较
下面是OLTP和OLAP的前12个比较:

OLTP和OLAP的优缺点:
以下是OLTP和OLAP的优缺点:
OLTP
以下是OLTP的优缺点
优势
- 通过提供健壮的机制来处理和存储事务性数据,它极大地简化了组织的事务性事件。
- OLTP系统非常快速和即时。
- 它们通过简化单个流程来增加组织的客户数量
缺点
- 对数据分析几乎没有洞察力。
- 在服务器失败的情况下,事务可能会导致延迟,在某些情况下可能会导致数据丢失。
- 更容易被黑客攻击。
OLAP
以下是OLAP的优缺点
优势
- 对来自不同来源的数据进行分析的单一平台。
- 来自不同来源的数据存储在一个集中的位置,因此能够更容易地访问大型信息。
- 精确和快速的计算。
- 高级安全。
缺点
- 由于软件的许可和价格较高,实现OLAP的成本很高。
- OLAP系统的全端到端监控、实现和升级依赖于该领域的IT专家。
- 由于从OLTP到OLAP系统的数据插入可能涉及多个数据库,因此要与所有的DB团队保持一致可能会带来挑战。
OLTP和OLAP系统的比较表
| Basis of Comparison | OLTP (联机事务处理系统) | OLAP (在线交易分析系统) |
| Process | 它用于管理每天发生的事务和更新数据库。 | 它用于从OLTP系统检索数据并对数据进行分析。 |
| Data Source | 在这里,OLTP系统本身就是数据源。 | OLAP的数据来自不同的OLTP数据库。 |
| Need | 无缝地运营业务。 | 对业务进行分析和预测,找出业务中存在的不足和发展的领域,并采取相应的行动。 |
| Insert and Update | 快速和短的插入和更新用户数据。 | 通常,长时间运行的批处理作业负责数据插入。 |
| Queries | 负责数据处理的小而简单的查询 | 相对较大和复杂的查询 |
| Method | 它利用了传统的DBMS系统 | 它利用了数据仓库 |
| Response Time | OLTP系统的响应时间以毫秒为单位。 | OLAP系统的响应时间更大,可能在秒、分钟甚至小时之间变化。 |
| Database Table Normalization | OLTP表是高度规范化的 | OLAP系统通常是反规范化的 |
| Access | 允许读和写两种访问 | 大多数情况下允许读访问,很少允许写访问。 |
| Integrity | OLTP系统需要维护数据完整性。 | 由于OLAP系统不会经常修改,因此数据完整性不是强制性的 |
| Backup and Recovery | 由于数据可用性在OLTP系统中非常关键,所以需要对所有数据库进行完整的备份 | OLAP系统的备份是及时的,而不是定期的。 |
| Target audience | 主要是为了市场洞察力。 | 这是为了客户洞察。 |
结论
在本文中,我们通过实际示例了解了OLTP和OLAP系统的定义,了解了这两个系统之间的区别以及它们在何处被使用和实现。现在您就可以区分OLTP和OLAP软件及其功能了。
推荐的文章
这是OLTP与OLAP之间最大区别的指南。这里我们还讨论了OLTP和OLAP与信息图和对照表的关键区别。你也可以看看下面的文章来学习更多-
- 数据仓库vs数据集市
- OLAP是什么?
- OLTP是什么?
- OLAP的类型
- 什么是数据集市?|类型,数据集市的特性
原文:https://www.educba.com/oltp-vs-olap
本文:http://jiagoushi.pro/node/1127
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 679 次浏览
【技术选型】Power BI vs Tableau vs Qlik的区别

Power BI vs Tableau vs Qlik的区别
Power Bi是一个商业智能工具,我们可以在整个公司上传和发布数据。业务智能响应任何查询并改进决策制定。为业务添加强大的功能,以实现良好的数据可视化。Power BI的另一个特性是Quick Insights,我们可以在数据集中搜索有趣的模式,并提供一个图表列表来更好地理解数据。利用人工智能和数据挖掘技术对数据进行分析。Qlik也是一个商业智能和数据可视化工具。
这是一个端到端ETL解决方案产生良好的客户服务。使用qlik,我们可以创建一个灵活的终端用户界面,根据数据进行良好的演示,创建动态图形图表和表格,执行统计分析,构建自己的专家系统。Qlik可以与虚拟数据库一起使用。它是一个基于窗口的工具,需要以下组件:Qlik服务器,Qlik发布器。
它们是最普遍使用的商业智能工具,用于在任何时候为用户创建、显示和共享交互式报告。它们是独立于平台的,需要较少数量的技术专家一起工作。它们采用客户机-服务器架构,以实现快速部署。它们非常适合需要优秀BI的高层管理人员。Tableau具有访问速度快、交互式可视化、性价比高、维护良好的安全性等优点。
Power BI的特点
- 从复杂的BI数据中获得丰富的图形可视化。
- 专门报告
- 好的导航窗格
- 包括具有可自定义仪表板的数据集。
Qlik的特点
- 通过使用混合方法,用户可以将存储在内存数据集中的Qlik视图中的大数据源中的数据关联起来。
- 在直接发现的帮助下,它们允许用户执行业务发现和可视化分析。
- 可移动就绪、角色和权限
- 与动态应用程序,仪表板交互。
Tableau 特性表
- 他们有一个很好的拖放。
- 为了数据共享,他们使用Tableau Public。
- 它们在web上实现交互式数据可视化。
- 它们的性能强大、可靠,运行于巨大的数据之上。
- 它们对移动设备友好,并支持完整的在线版本。
Power BI与Tableau与Qlik(Infographics)的正面比较
以下是Power BI、Tableau和Qlik之间的9大差异
Power BI和Tableau以及Qlik的主要区别
这些都是市场上的热门选择;让我们来讨论一下主要的区别:
- Qlik可以被多个用户立即访问。Qlik比Tableau快。Power bI连接到任何不需要ETL的数据源。
- 文件存储。我们可以通过Qlik Views专有通信协议访问这些文档并存储在Windows OS中,所有的事件都在Qlik服务器中获取,他们负责客户端-服务器.Power BI有三种类型的文件excel(.xls), Power BI desktop(.pbix), (.csv)。Tableau解压文件可以有(.tde)文件扩展名。
- Qlik支持用于外部数据源的OLEDB接口。Power BI从OLEDB加载数据并在BI服务器中发布。目前它们只支持实时连接。
- Qlik结构管理不善,而Tableau结构管理良好的用户指南。
- Qlik是一种独立的技术。将数据发布到外部世界是由QlikView发布者管理的。Power BI只在SAAS模型上可用,而Tableau有云和本地选项。Power BI桌面版是免费的。
- 使用PowerBI可以增加数据建模功能。在Qlik中,数据洞察力是快速产生的。
- Tableau和Power BI是用户友好的。Qlik有很高的可定制模式。
- Qlik 和tableau 支持统计分析。Power BI没有这个功能。
Power BI vs Tableau vs Qlik对照表
下面是9个最重要的比较
| 比较点 | Power BI | Tableau | Qlik |
| 性能 | 它在数据可视化方面落后。 | 他们是更友好的,因为非技术用户可以使用这个工具。他们使用立方技术 | Qlik需要一个开发人员来处理报告和指示板。他们使用所有类型的数据集。 它们有很好的可视化效果。 |
| UI | 当具有良好的用户界面来发布报表时,仪表板是PowerBI的关键特性。 | 用户界面更好 | 与Tableau相比,用户界面是相当差。 |
| 轻松学习 | 用户友好-有Excel的知识就足够了 | 它们不需要任何技术或编程技能。 | 有数据科学背景易于学习 |
| 支持的需求 | Power BI有Power BI桌面、网关 | 他们使用前端工具,如R。 | Qlik包括前端(Qlik开发人员)和后端(Qlik发布人员) |
| 版本 | 桌面版是免费的,Power BI Pro是按月付费的。 | Tableau Reader是一个免费版本。Tableau服务器是一个许可服务器。 | Qlik个人版是Qlik的免费版本,运行时无需许可证密钥。 |
|
成本-效果 |
更便宜。 | 它节省了金钱、时间和精力。加载数据仓库时非常昂贵。 | Qlik网站有两个版本。个人版免费,企业版可与团队联系使用。 |
| 在线分析 | 它们通过SQL服务器连接到OLAP多维数据集进行多维分析。 | Tableau可以连接到OLAP,在最深层取出立方体的措施。 | 对OLAP的访问提供了封装的数据视图。 |
| 速度 | 他们有聪明的恢复 | 速度取决于RAM和数据集。 | 它们有更好的速度,因为它们将数据存储在服务器RAM(内存存储)中。 |
| 优势 | Power BI成本低廉,并且对于大型项目具有可伸缩性。 | 他们在智能可视化方面排名第一。 | 他们提供广泛的深度分析,他们有良好的客户满意度评级。 |
结论
决定哪一个是最好的需求分析。拖放功能以及安全的数据连接使tableau成为市场的领跑者。Qlik的优势包括可视化模式的内存引擎功能。通过Power BI创建的报告可以在团队之间共享,并且可以在任何设备上访问。总体来说,Power BI是三种工具中竞争对手的工具。它是高级的Microsoft应用程序和平台,并对云平台提供了高级支持。Tableau是目前市场上商业分析的首选。
推荐的文章
这是Power BI、Tableau和Qlik之间最大的区别。这里我们还讨论了与信息图和对照表的关键区别。你也可以看看下面的文章来了解更多。
- Power BI vs SSRS - 差异
- Looker和Tableau之间的有用比较
- QlikView和QlikSense——哪个更好
- 如何在Power BI桌面中使用图标?
- 如何在Power BI中使用日历DAX功能?
- 谷歌Data Studio与Tableau 的差异
原文:https://www.educba.com/power-bi-vs-tableau-vs-qlik
本文:http://jiagoushi.pro/node/1131
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 557 次浏览
【技术选型】Solr vs Elasticsearch:选择开源搜索引擎
云、分析和认知搜索时代的开源搜索引擎
Solr与Elasticsearch在我们的客户项目和企业搜索社区中经常讨论。但是随着传统的企业搜索已经发展成为Gartner所说的“洞察引擎”,我们重新讨论了这个主题,提供了结合云、分析和认知搜索能力的最新观察结果,以帮助您评估Solr和Elasticsearch。
Solr是什么?
Solr是Apache软件基金会Lucene项目的一个领先的开源搜索引擎。由于其灵活性、可伸缩性和成本效益,Solr被大型和小型企业广泛使用。
Elasticsearch是什么?
同样基于Lucene的Elasticsearch是另一个领先的开源搜索引擎,支持强大的企业应用程序。Elastic是一家开发Elasticsearch和Elastic Stack的公司,它为搜索、日志分析和其他高级分析用例提供企业解决方案。
选择您的开源搜索引擎
通常,当我们帮助客户执行有关在其企业解决方案中使用开源搜索引擎的评估时,会有人问:“Solr和Elasticsearch哪个更好?”虽然可能会有一种先入为主的观念,认为一个人天生就比另一个人好,但如果用“哪个对我更好?”这样的说法来表述,这个问题就更相关了。
有各种搜索引擎技术可用,但最流行的开源变体是那些依赖于Apache Lucene底层核心功能的技术,从本质上说,这是使搜索引擎工作的部分。Solr和Elasticsearch是搜索库之上的组件,它们为一个完整的搜索产品提供自己的实现和特性。Lucene的核心功能为Solr和Elasticsearch的基本搜索功能提供了相同的体验,但它们围绕Lucene的实现方法创造了不同之处。
搜索引擎的作用已经不仅仅是有效地查找信息,而是在内容分析、预测建模以及与认知/智能搜索功能(如自然语言处理(NLP)、机器学习(ML)和相关性评分)的集成方面发挥关键作用。我们已经在我们的客户工作中探索并实现了这些智能功能——在这里了解更多信息。
Solr和Elasticsearch:哪个对我的组织更好?
这得视情况而定。
围绕一种技术而不是另一种技术的采用有许多用例。但是当被问到这个问题时,我通常会从操作管理的角度用一个类比来回答:“Solr就像Linux。Elasticsearch就像窗户。您可以对Solr进行大量的定制和定制,以满足您的需求,但是与Elasticsearch相比,管理和部署更加复杂,也更加耗费资源。Elasticsearch非常容易部署、管理和监控(使用X-Pack),具有设计良好的用户界面(Kibana),允许数据探索和创建分析可视化,但定制其功能有限,使用插件框架更加困难。
Elasticsearch可以为你,如果你想:
- 运行迅速与很少开销得得到你的搜索引擎,
- 尽快开始探索你的数据;和
- 将分析和可视化作为用例的核心组件。
Solr可能适合你,如果你:
- 需要对大量数据进行索引和再处理;
- 有可用的资源来投资管理Solr和用于交互的工具;和
- 拥有一个与Solr一起工作的现有企业框架(像其他Apache产品,如Hadoop,或企业框架,如构建在Hadoop上的Cloudera、Hortonworks或HDInsights)。
这并不是说一个Hadoop平台不能使用Elasticsearch(我们客户提出了这种情况),但一些平台,Cloudera尤其是Hortonworks,提供额外的工具和方法和管理中的Solr索引数据的生态系统(这是一个特殊的例子Cloudera即将发布的CDH 6支持Solr 7)。
Solr与Elasticsearch:特性比较
从经验来看,评估可以为客户定义战略和实施路线图提供巨大的价值。在我们的评估过程中,我们执行一个搜索引擎比较矩阵,它根据特定客户的需求和用例评估搜索引擎的适用性,并使用基于某些特性的优先级的加权评分机制。基于此分析,在对搜索引擎进行总体推荐时,有一些公共特性和用例可以作为感兴趣的点。
下面的图表展示了一些关于Solr和Elasticsearch的观察结果:
| SOLR | ELASTICSEARCH | |
|---|---|---|
| 用例 |
|
|
|
可视化 工具 |
|
|
|
云和 大数据 |
|
|
|
认知 搜索 能力和 整合 |
|
|
|
管理和 运营 |
|
|
|
开发 架构 |
|
|
|
集群 状态 管理 |
|
|
| 安全 |
|
|
|
批量 索引 工具 |
|
|
|
近实时(NRT) 索引 |
|
|
| 分析 |
|
|
|
嵌套的 数据 结构 |
|
|
|
查询 操作 |
|
|
| API 交互 |
|
|
选择Solr和Elasticsearch?考虑这些
决定哪个搜索引擎最适合您的特定用例和需求,不应该是基于“非此即彼”的假设做出的决定。Solr中某个特定功能的总体重要性可能超过Elasticsearch的操作优势,例如:
在一个客户端案例中,与Solr部署相关的开销和不得不使用过时的SolrNET客户端(当时)被Solr的可插拔特性所抵消。需要定制加密更新和请求处理程序来使用旋转数据加密键对索引内容应用加密,因此必须使用Solr而不是Elasticsearch。索引加密过程所需要的功能并不能在Elasticsearch中有效地实现。
相反,在不考虑大数据或分析的情况下,为通用搜索用例评估搜索引擎选项时,Elasticsearch成为了一个更受欢迎的选择,因为它减少了维护和部署开销,以及完全托管和管理环境的选项。
在一些基于什么对客户最重要的情况下,它不是立即清楚哪个搜索引擎(包括商业引擎)将最好地满足客户的需求,尽管应用了评分规则。在这种情况下,可以使用示例数据集执行“烘烤”,面向客户评估每个引擎对于特定用例集的执行情况。
归根结底,Solr和Elasticsearch都是功能强大、灵活、可扩展且极其强大的开源搜索引擎。总体用例和业务需求,以及您所需的特性、操作考虑,以及与新的认知搜索和分析功能的集成,将最终驱动您决定是选择Solr还是Elasticsearch。
本文:http://jiagoushi.pro/node/1145
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 110 次浏览
【技术选型】Solr与Elasticsearch:谁是领先的开源搜索引擎?
搜索是任何应用程序的组成部分。当速度、性能和高可用性是核心需求时,对tb和pb级的数据执行搜索可能具有挑战性。这篇博客文章将讨论Solr和Elasticsearch这两个最受欢迎的开源搜索引擎,它们在过去几年的发展方向不同。
它们都构建在Apache Lucene之上,所以它们支持的特性非常相似。但是,它们在部署、可伸缩性、查询语言和许多其他功能方面存在显著差异。
关于Apache Solr
Apache Solr是构建在Lucene之上的开源搜索服务器,它通过HTTP请求提供Lucene的所有搜索功能。它已经存在了将近15年,是一个拥有广泛用户社区的成熟产品。
Solr提供强大的特性,如分布式全文搜索、面、近实时索引、高可用性、NoSQL特性、与Hadoop等大数据工具的集成,以及处理Word和PDF等富文本文档的能力。
关于Elasticsearch
Elasticsearch也是建立在Apache Lucene之上的开源搜索引擎,ELK的其余部分,也叫Elastic,包括Logstash和Kibana。它使用RESTful api扩展了Lucene强大的索引和搜索功能,并使用索引和碎片概念将分布的数据归档到多个服务器上。Elasticsearch完全基于JSON,适用于时间序列和NoSQL数据。
这个工具比Solr年轻得多,但由于其功能丰富的用例而获得了广泛的欢迎。它的一些主要特性包括分布式全文分布式搜索、高可用性、强大的查询DSL、多租户、Geo搜索和水平伸缩。
相对受欢迎程度
db - engine根据数据库管理系统和搜索引擎的受欢迎程度对它们进行排名,根据db - engine, Elasticsearch排名第一,Solr排名第三。
Solr在其诞生的前10年就已经很受欢迎,但Elasticsearch自2016年以来一直是最受欢迎的搜索引擎。
图1:db - engine排序elasticsearch与Solr流行度(来源:db - engine)
安装和配置
Java是安装这两个引擎的主要先决条件,但是默认的Elasticsearch配置需要1GB的堆内存。这可以在jvm中更改。配置目录中的选项文件。
默认情况下,Solr至少需要512MB堆内存来分配给实例。该设置可以在solr脚本文件或solr.in中更改。cmd文件。这两个文件都位于Solr安装的bin目录中。
Elasticsearch易于安装和配置,但它比Solr要重一些。Elasticsearch的最新版本(7.7.1版本,于2020年6月发布)的压缩大小为314.5MB,而Solr(8.5.2版本,于2020年5月发布)的压缩大小为191.7MB。
在Elasticsearch中的配置文件以YML格式编写。Solr支持基于xml的配置文件。
索引和搜索
Solr和Elasticsearch都在Lucene写索引。但是,由于分片和复制(以及其他特性)存在差异,因此它们的文件和架构也存在差异。此外,Elasticsearch具有原生DSL支持,而Solr具有与Lucene语法一致的健壮标准查询解析器。
数据源
这两种工具都支持广泛的数据源。
Solr使用请求处理程序从XML文件、CSV文件、数据库、Microsoft Word文档和pdf中摄取数据。通过对Apache Tika库的本机支持,它支持从一千多种文件类型中提取和索引。Solr附带一个简单的命令行post。例如,要在名为testcollection的集合中摄取基于csv的数据,您只需使用以下命令:
bin/post -c testcollection *.csv
另一方面,Elasticsearch完全是基于jsf的。它支持使用Beats系列(弹性堆栈中可用的轻量级数据传输程序)和Logstash从多个源摄取数据。
用例
虽然这两个产品都是面向文档的搜索引擎,但Solr一直更侧重于使用高级信息检索(IR)进行面向企业的文本搜索。因此,它更适合使用大量静态数据的搜索应用程序。Solr更适合已经实现大数据生态系统工具(如Hadoop和Spark)的企业应用程序。此外,Solr在处理富文本格式(RTF)文档方面非常出色。为了与Elasticsearch竞争,最近的Solr版本提供了一些新特性,比如并行SQL接口和流表达式。
Elasticsearch更侧重于缩放、数据分析和处理时间序列数据,以获得有意义的见解和模式。它的大规模日志分析性能使它非常受欢迎。Elasticsearch更适合以JSON格式输入和输出数据的现代web应用程序。Elasticsearch也投入了大量的开发工作,使其工具更具弹性。这将它转换为主数据存储。
搜索
Solr和Elasticsearch都支持NRT(接近实时)搜索,并充分利用了Lucene的所有搜索功能。由于它们都支持基于json的查询DSL,因此它们都具有附加的与搜索相关的特性集,如下所述。
早期的Solr版本必须依赖于它的标准查询解析器,但是Solr现在还支持基于jsf的查询DSL。虽然Solr的标准查询解析器允许用户创建各种结构化查询,但在编写这些查询时出现语法错误的几率要高得多。然而,您可以在Solr中编写在Elasticsearch中不可用的非常复杂的搜索查询。Solr包括一个名为Velocity search的示例搜索UI,它提供了强大的特性,如搜索、显示、突出显示、自动完成和地理搜索。
Elasticsearch的DSL是原生的。Elasticsearch中的聚合框架功能强大,api中的聚合查询具有更好的缓存。该工具的最新版本提供了更好的内存占用管理。
索引
因为Elasticsearch是无模式的,所以很容易索引非结构化数据和动态字段,而无需预先定义索引的模式。早期的Solr版本在索引数据之前需要一个已定义的模式。但是,Solr现在支持无模式模式。
这两个搜索引擎都支持自定义分析程序、基于同义词的索引、词根分析和各种记号化选项。
可伸缩性和分布式
搜索引擎必须快速处理大量的数据和对数以亿计的记录集的复杂查询。有时候,这些查询可能非常耗费资源,以至于可能会导致整个系统崩溃——尤其是在您没有提前计划负载并且无法快速伸缩的情况下。因此,搜索引擎本质上必须具有可伸缩性和容错能力。
集群、分片和再平衡
Elasticsearch和SolrCloud都提供对分片的支持。但是,由于Elasticsearch的设计考虑了水平伸缩,因此它对伸缩和集群管理提供了更好的支持。它的缺点是,尽管您可以使用收缩API来减少索引的切分,但切分一旦创建,就不能增加。SolrCloud支持进一步拆分现有的切分,但不支持收缩切分。
Elasticsearch内置的zen discovery模块处理集群协调。SolrCloud需要Apache Zookeeper,这是一个额外的服务。
在出现切分或节点故障时,Elasticsearch会自行进行集群再平衡,很少需要手动干预。在SolrCloud中,再平衡是复杂而难以管理的。
社区
Solr拥有一个广泛的开源社区。任何人都可以为Solr做出贡献,新的Solr开发人员或代码提交者是根据能力选出的。Elasticsearch技术上是开源的,但并不完全开放。所有贡献者都可以访问源代码,用户可以进行更改并贡献它们。但最终的变更会得到Elastic(运行Elasticsearch和其他软件的公司)员工的确认。因此,Elasticsearch更多的是由单个公司驱动,而不是整个社区。这还不包括Elasticsearch提供的非开放的高级特性(以及Elastic/ELK栈))。
回到2010年代中期,Solr贡献者和提交者跨越多个组织,而Elasticsearch提交者仅来自弹性组织。Solr强大的社区拥有健康的项目管道和许多知名公司的参与。这些成员还在整个开发和工程过程中对平台进行投资。
在过去的五年里,这种情况发生了巨大的变化。Elasticsearch的贡献者社区和用户基础得到了极大的发展。到目前为止,它是本世纪20年代初DevOps中最流行的开源时间序列数据库和搜索引擎。
从历史上看,两者都拥有强大的用户基础和丰富的开发人员社区,但Elasticsearch已经超过了Solr。Solr已经存在了很长一段时间,但是它的生态系统已经停滞不前,即使在拥有了良好的开发和更大的用户基础之后。
文档
在这一点上,Elasticsearch文档胜出。Elasticsearch的官方网站不仅提供了条理清晰、高质量的文档和清晰的示例,而且由于该工具的普及,互联网上充斥着书籍和指南。在过去的四年里,Elasticsearch加强了文档的编制,使其超越了组织。此外,它还提供了很好的示例和清晰的配置说明。
相比之下,Solr文档是缺乏的。Solr api的总体覆盖范围很小,很难找到好的技术示例和教程。以前是相反的:Solr是一个文档非常完善的产品,具有清晰的API用例示例和上下文。然而,它的文档维护已经落后,许多用户注意到差距。
概要:Solr vs Elasticsearch
要在这两种技术中选择一个明显的赢家,需要完全理解它们所支持的用例、它们的特性集、它们提供的伸缩选项以及它们的易于维护。
下面是每个工具属性的总结:
| Solr | Elasticsearch | |
| 安装和配置 | 易于启动和运行和非常支持的文档 | 易于启动和运行与非常支持的文档。有几个包可用于各种平台。 |
| 搜索和索引 | 适合文本搜索和接近大数据生态系统的企业应用 | 作为文本搜索和分析引擎都很有用,因为它有强大的聚合模块 |
| 可伸缩性和集群 | 支持从Solr云和Apache Zookeeper依赖集群协调 | 更好的固有的可伸缩性;为云部署设计最佳方案 |
| 社区 | 历史上的大生态系统 | 一个蓬勃发展的自由/开源软件版本Elasticsearch和ELK堆栈的生态系统 |
| 文档 | 不完整的,过时的 | Well-documented |
这两种技术都很容易开始使用。Solr在信息检索领域提供了很好的功能,但是Elasticsearch更容易投入生产和扩展。在选择工具时,请确保查看您的需求,并为您的特定用例做出最佳选择。
原文:https://logz.io/blog/solr-vs-elasticsearch/
本文:http://jiagoushi.pro/node/1151
讨论:请加入知识星球【首席架构师圈】或者小号【jiaoushi_pro】
- 183 次浏览
【技术选型】Spark SQL vs Presto
Spark SQL与Presto之间的区别
简单来说 Presto 就是“SQL查询引擎”,最初是为Apache Hadoop开发的。它是一个开源的分布式SQL查询引擎,用于对各种大小的数据集运行交互式分析查询。
Spark SQL是一个分布式内存中计算引擎,在结构化和半结构化数据集之上有一个SQL层。由于它是在内存中处理的,所以在Spark SQL中处理速度会很快。
Spark SQL和Presto (Infographics)的头对头比较
下面是Spark SQL和Presto之间的前7个比较:

Spark SQL和Presto之间的关键区别
下面是关于Presto和Spark SQL之间的关键区别的列表:
- Apache Spark引入了一个用于处理结构化数据的编程模块,称为Spark SQL。Spark SQL包含一个称为数据帧的编码抽象,它可以作为分布式SQL查询引擎。
- Presto创立的初衷是为了实现交互式分析和商业数据仓库的速度,使组织规模能够与Facebook相匹配。
- Spark SQL是Spark Core上的一个组件,它引入了名为SchemaRDD(弹性分布式数据集)的新数据抽象,它提供了对结构化/半结构化数据的支持。
- Presto被设计为使用MapReduce作业(如Hive或Pig)查询HDFS数据的工具的替代品,但Presto并不仅限于HDFS。
- Spark SQL遵循内存中处理,这提高了处理速度。Spark被设计用于处理广泛的工作负载,如批处理查询、迭代算法、交互式查询、流媒体等。
- Presto能够执行联邦查询。下面是快速联邦查询的示例
让我们假设任何RDMS 表sample1与HIVE表sample2 ,
' Testdb '是hive和MYSQL中的数据库。使用Presto,我们可以评估数据使用在一个单一的查询一旦他们的连接器配置正确,如下所示-
presto> <Function (select/Group by ..etc)> hive.Testdb.sample2
- Spark SQL架构由Spark SQL, Schema RDD, and Data Frame组成
- 数据帧是数据的集合;数据被组织成指定的列。从技术上讲,它与关系数据库表相同。
- 模式RDD: Spark Core包含称为RDD的特殊数据结构。Spark SQL适用于模式、表和记录。因此,用户可以使用模式RDD作为临时表。这样用户就可以把这个模式称为数据框架
- Data Frame 能力:数据框架在单个节点集群上处理从千字节到千兆字节的数据,
- Data Frame支持不同的数据格式(CSV, elasticsearch, Cassandra等)和存储系统(HDFS, HIVE表,MySQL等),它可以集成与所有大数据工具/框架通过Spark-Core,并提供API的语言,如Python, Java, Scala,和R编程。
- Presto是一个分布式引擎,可以在集群设置中工作。Presto体系结构易于理解和扩展。Presto客户端(CLI)将SQL语句提交给管理处理的主守护进程协调器。
- 使用Presto的公司:Facebook、Netflix、Airbnd、Dropbox等。
- Apache Spark用例可以在金融、零售、医疗保健和旅游等行业中找到。许多电子商务网站,如eBay、阿里巴巴、Pinterest都在其电子商务平台上使用Spark SQL来分析数百PB的数据。
比较Spark SQL和Presto表
下面是SQL和Presto之间最顶层的比较。
|
比较的基础 |
Presto | Spark SQL |
|
生态系统/平台 |
Hadoop、大数据处理等 | Spark框架、大数据处理等 |
| 目的 |
Presto是为在大数据(巨大的工作负载)上运行SQL查询而设计的。 它是由Facebook设计来处理他们巨大的工作量。 |
Spark SQL是Apache Spark Core的组件之一。 Spark Core是Spark平台的基本执行引擎 |
| 安装 |
|
|
|
功能/特性 |
Presto允许对许多数据源进行数据查询;例如,数据可能驻留在数据存储中:Hive、Cassandra、RDBMS和其他一些专有数据存储中。 | Spark SQL提供了使用数据框架和JDBC连接器与其他数据源集成的灵活性。 |
|
连接器 支持 |
Presto支持可插拔连接器。这些连接器为查询提供数据集。 下面是presto中可用的几个预先存在的连接器,同时presto还提供了与定制连接器连接的能力。 下面是it支持的一些连接器
|
数据框架接口允许不同的数据源在Spark SQL上工作。 Spark SQL包括一个具有行业标准JDBC和ODBC连接的服务器模式。 |
|
联邦查询 |
Presto支持联邦查询。Presto可以配置连接到不同的DBs,一旦配置;它的CLI可以用来启动“联邦查询”。 在一个Presto查询中,用户可以组合来自多个数据源的数据并运行查询。 |
Spark SQL带有一个使用JDBC连接其他数据库的内建特性,即“JDBC到其他数据库”,它有助于联邦特性。 Spark利用scala/python API使用JDBC:数据库特性创建数据框架,但它也可以直接与Spark SQL Thrift server一起工作,并允许用户像其他hive/ Spark表一样毫不费力地查询外部JDBC表。 |
|
谁在使用 |
数据分析师、数据工程师、数据科学家等等 | 数据分析师、数据工程师、数据科学家、Spark开发人员等等 |
结论
Spark SQL和Presto都是市场上可用的SQL分布式引擎。
Presto在处理双类型查询时非常有用,而Spark SQL在大型分析查询中的性能领先。与配置相比,Presto的设置比Spark SQL简单。Spark SQL和Presto在市场上的地位是平等的,它们解决的是不同类型的业务问题。
推荐的文章
这是Spark SQL与Presto的一个指南。在这里,我们讨论了Spark SQL与即时头对头比较、关键区别以及信息图和比较表。你也可以看看下面的文章来了解更多-
- Apache Spark vs Apache Flink -你需要知道的8件有用的事情
- Apache Hive vs Apache Spark SQL - 13惊人的差异
- Hadoop和SQL之间的最佳6个比较
- Hadoop与Teradata——有价值的区别
原文:https://www.educba.com/spark-sql-vs-presto
本文:http://jiagoushi.pro/node/1129
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 1517 次浏览
【技术选型】比较MongoDB和PostgreSQL
在我们开始之前:MongoDB和Postgres都是很好的数据库管理系统。这篇文章的目的是让你快速了解每个数据库的个性,以及每个数据库最适合的用例类型。
MongoDB和PostgreSQL:一个简单的比较
MongoDB是主要的文档数据库。它构建在分布式、向外扩展的架构上,并已成为一个用于管理和向应用程序交付数据的综合云平台。MongoDB可以大规模地处理事务、操作和分析工作负载。如果您关心的是上市时间、开发人员的生产力、支持DevOps和敏捷方法,以及构建无需操作操作就可伸缩的东西,那么MongoDB就是最好的选择。
PostgreSQL是一个坚如磐石的、开放源码的企业级SQL数据库,30年来一直在扩展它的功能。你想从关系数据库中得到的所有东西都可以在PostgreSQL中找到,它依赖于一个扩展的架构。如果您关心的是兼容性,从数百个表中提供数千个查询,利用现有的SQL技能,并将SQL推到极限,PostgreSQL将会做得非常出色。
这两个数据库都很棒,但是您需要什么呢?
作为一个精明的读者应该已经知道,真正的问题不是MongoDB和Postgres,而是最好的文档数据库和最好的关系数据库。两个数据库都很棒。
如果您正在为处理快速变化、多结构数据的现代事务和分析应用程序寻找分布式数据库,那么MongoDB就是最佳选择。
如果SQL数据库符合您的需要,那么Postgres是一个很好的选择。
你需要的正确答案当然是基于你正在尝试做的事情。在本文中,我们的目标是帮助解释每个数据库的个性和特征,以便您更好地了解它是否满足您的需要。
但是通常在开发项目的开始阶段,项目负责人通常很好地掌握了用例,但是对于他们的业务和用户将需要的具体应用程序特性并不是很清楚。他们不得不打赌谁最适合。本文的其余部分旨在提供有助于进行安全打赌的信息。
Postgresql vs MongoDB概述
但是,对于那些想要马上了解故事的人,这里是我们的一般指导的一个总结:
- 如果你在一个开发项目的开始阶段,试图通过敏捷的开发过程找出你的需求和数据模型,MongoDB将会大出风头,因为开发人员可以在他们需要的时候,自己重塑数据。MongoDB允许您管理任何结构的数据,而不仅仅是预先定义的表格结构。
- 如果你支持一个应用程序,你知道它需要扩展流量或数据大小(或两者都需要),并且需要跨区域分布数据本地或数据主权,MongoDB的扩展架构将自动满足这些需求。
- 如果你想要一个在每个公共云上都以相同方式工作的多云数据库,可以在特定的地理区域存储客户数据,并支持最新的无服务器和移动开发范例,MongoDB Atlas是正确的选择。
- 如果你是一个SQL商店,引入一个新的范例所花费的成本比上面提到的任何好处都要高,那么PostgreSQL是一个很可能满足你所有需求的选择。
- 如果你想要一个关系数据库,运行复杂的SQL查询,并与许多现有的基于表格、关系数据模型的应用程序一起工作,PostgreSQL可以完成这项工作。
- 如果你是一个创造性的SQL开发人员和想把SQL索引限制通过使用先进的技术,存储和搜索大量的结构化数据类型,创建用户定义的函数在不同的语言中,和调优数据库第n个学位,你可能能够更进一步,比任何其他RDBMS PostgreSQL。
所以,现在不耐心的人已经得到了满足,患者可以深入到MongoDB,然后是PostgreSQL,然后进行比较。
MongoDB:可伸缩的文档数据库,已成为一个数据平台
文档模型的美丽之处
MongoDB的文档数据模型自然地映射到应用程序代码中的对象,使得开发人员可以很容易地学习和使用它。文档使您能够表示层次关系,从而方便地存储数组和其他更复杂的结构。JSON文档可以将数据存储在字段中,作为数组,甚至作为嵌套的子文档。这样就可以将相关信息存储在一起,通过丰富而富有表现力的MongoDB查询语言进行快速查询访问。
MongoDB以名为BSON(二进制JSON)的二进制表示形式将数据存储为文档。字段可以因文档而异;不需要向系统声明文档的结构—文档是自描述的。如果需要将新字段添加到文档中,那么可以在不影响集合中的所有其他文档的情况下创建该字段,不需要更新中央系统目录、更新ORM,也不需要使系统脱机。可选地,模式验证可用于对每个集合实施数据治理控制。
这种灵活性在合并来自不同来源的信息或适应随时间变化的文档时非常有用,特别是在不断部署新的应用程序功能时。
PostgreSQL和MongoDB的术语和概念
MongoDB的文档模型中使用的许多术语和概念与PostgreSQL的表格模型相同或相似:
| PostgreSQL | MongoDB |
|---|---|
| ACID Transactions | ACID Transactions |
| Table | Collection |
| Row | Document |
| Column | Field |
| Secondary Index | Secondary Index |
| JOINs, UNIONs | Embedded documents, $lookup & $graphLookup, $unionWith |
| Materialized Views | On-demand Materialized Views |
| GROUP_BY | Aggregation Pipeline |
文档模型的增强
MongoDB允许您以几乎任何结构存储数据,并且每个字段——甚至是那些嵌套在子文档和数组中的字段——都可以建立索引并有效地搜索。
MongoDB向文档模型和查询引擎添加元素,以处理数据的地理空间和时间序列标记。这扩展了可以在数据库上执行的查询和分析类型。
BSON包含了JSON数据中没有的数据类型(例如,datetime、int、long、date、浮点数、decimal128和字节数组),提供了对多种数字类型的严格类型处理,而不是通用的“数字”类型。
模式验证允许您对模式应用治理和数据质量控制。
用于对许多文档进行更改的ACID事务
ACID事务是关系数据库中使编写应用程序更加容易的最强大的特性之一。关于如何定义和实现ACID事务的细节充斥着许多计算机科学教科书。计算机科学领域的许多讨论都是关于数据库事务中的隔离级别的)。PostgreSQL默认为read committed隔离级别,并允许用户将其调优到serializable隔离级别。
需要记住的重要事情是,事务允许在组中对数据库进行许多更改或在组中回滚。
在关系数据库中,所涉及的数据将在表模式中跨独立的父-子表建模。这意味着一次更新所有记录将需要一个事务。
从某种意义上说,文档数据库更容易实现事务,因为它们将数据聚集在文档中,而写和读文档是原子操作,因此不需要多文档事务。可以在单个操作中写入一个或多个字段,包括对多个子文档和数组元素的更新。MongoDB保证了文档更新时的完全隔离。任何错误都将触发更新操作回滚,恢复更改并确保客户端接收到文档的一致视图。
MongoDB还支持跨多个文档的数据库事务,因此相关的大块更改可以作为一个组提交或回滚。凭借其多文档事务功能,MongoDB是少数几个将传统关系数据库的ACID保证与文档模型的速度、灵活性和强大功能结合起来的数据库之一。
从程序员的角度来看,MongoDB中的事务就像开发人员在PostgreSQL中已经熟悉的事务一样。MongoDB中的事务是多语句的,具有与快照隔离类似的语法(例如starttransaction和committransaction),因此对于任何有事务经验的人来说都很容易添加到任何应用程序中。
比较MongoDB查询语言和SQL
PostgreSQL使用的关系数据库模型依赖于将数据存储在表中,然后使用结构化查询语言(SQL)进行数据库访问。
要做到这一点,在PostgreSQL和所有其他SQL数据库中,必须在填充数据之前创建数据库模式和建立数据关系。相关信息可以存储在不同的表中,但是通过使用外键和连接进行关联。模式中的大多数更改都需要迁移过程,迁移过程可能会使数据库离线或降低应用程序在运行时的性能。
SQL的强大之处在于它的强大且广为人知的查询语言,以及大量的工具。
使用关系数据库的挑战是需要预先定义其结构。加载数据后更改结构通常非常困难,需要跨开发、DBA和Ops的多个团队紧密地协调更改。
现在在MongoDB的文档数据库世界中,数据的结构不需要预先在数据库中规划,而且更改起来更容易。开发人员可以决定应用程序中需要什么,并相应地在数据库中更改它。
MongoDB默认不使用SQL。相反,为了处理MongoDB中的文档并提取数据,MongoDB提供了自己的查询语言(MQL),它提供了与SQL相同的大部分功能和灵活性。例如,与SQL一样,MQL允许您引用来自多个表的数据,转换和聚合这些数据,并筛选所需的特定结果。与SQL不同,MQL的工作方式对于每种编程语言都是惯用的。
MongoDB中的查询性能可以通过在文档和子文档的字段上创建索引来提高。MongoDB允许文档的任何字段,包括那些深深嵌套在数组和子文档中的字段,被建立索引并有效地查询。
下面的图表比较了SQL和MongoDB查询数据的方法,并展示了一些SQL语句的例子以及它们如何映射到MongoDB:
查询语言映射
PostgreSQL和MongoDB都有丰富的查询语言。下面是一些SQL语句的示例以及它们如何映射到MongoDB。在MongoDB文档中可以找到更全面的语句列表。
| SQL | MongoDB |
|---|---|
|
Not Required |
|
|
|
|
|
|
|
|
查看这些资源来进行更多的比较:
敏捷性和协作
文档模型还具有突出的特性,使开发和协作更容易、更快。
从开发人员个人的角度来看,MongoDB使数据更像代码。开发人员可以定义JSON或BSON文档的结构、进行一些开发、查看如何进行、随时添加新字段并随意修改数据,这就是文档模型的美妙之处。这种灵活性避免了要求DBA重新构造数据定义语言语句,然后重新创建和加载关系数据库,或者让开发人员做这些工作所带来的延迟和瓶颈。
在文档数据库中,开发人员或团队可以拥有文档或文档的一部分,并根据需要对其进行改进,而不需要在不同的团队之间使用中介和复杂的依赖链。
可伸缩性、弹性和安全性
MongoDB是为向外扩展而构建的。因此,需要超级快速查询和大量数据(或者两者都需要)的用例可以通过由小型机器组成更大的集群来处理。
MongoDB基于分布式架构,允许用户跨多个实例向外扩展,并被证明可以支持大型应用程序,无论是通过用户还是数据大小来衡量。向外扩展策略依赖于使用大量较小且通常廉价的机器。这种策略可以扩展到数百台机器。
在PostgreSQL中,扩展的方法取决于你说的是写数据还是读数据。对于写,它是基于一个扩展的架构,在这个架构中,运行PostgreSQL的单个主机器必须尽可能强大才能扩展。对于读取,可以通过创建副本扩展PostgreSQL,但是每个副本必须包含数据库的完整副本。
MongoDB可伸缩的基础是集群中跨实例智能分区(分片)数据的思想。MongoDB不分解文档;文档是独立的单元,这使得它更容易分布在多个服务器上,同时保持数据的局部性。
在完全管理的全球MongoDB地图集云服务中,跨地区分发数据很容易。某些文档可以被标记,因此它们将总是物理地存储在特定的国家或地理区域。这样的位置感知可以:
- 通过将数据存储在目标用户附近来减少延迟
- 帮助遵守有关数据可能被合法存储的地方的法律
每个MongoDB碎片都作为一个副本集运行:一个由三个或多个独立服务器组成的同步集群,在它们之间不断复制数据,提供冗余,并在面临系统故障或计划维护时防止停机。还可以跨数据中心安装副本,从而提供针对区域中断的弹性。在MongoDB Atlas中,创建和配置这样的集群变得更加容易和快速。
MongoDB已经实现了一套现代化的网络安全控制和集成,包括内部版本和云版本。这包括强大的安全范例,如客户端字段级加密,它允许在数据通过网络发送到数据库之前对其进行加密。
PostgreSQL有完整的安全特性,包括许多类型的加密。所有主要的云服务提供商都提供了PostgreSQL。虽然数据库是相同的,但操作和开发人员工具因云供应商的不同而不同,这使得不同云之间的迁移更加复杂。MongoDB Atlas以相同的方式运行在所有三大云提供商之间,简化了迁移和多云部署。
成熟的平台生态系统
随着数据库等基础技术的发展,它将得到由服务、集成、合作伙伴和相关产品组成的平台生态系统的支持。MongoDB平台生态系统的中心是数据库,但它有许多层,提供附加价值和解决问题。
MongoDB已经被大量采用,并且是最流行的现代数据库,根据Stackoverflow开发人员调查,它是开发人员最想使用的数据库。多亏了MongoDB工程和社区的努力,我们已经建立了一个完整的平台来满足开发者的需求。
PostgreSQL可以作为一个安装的、自管理的版本,或者作为一个数据库即服务在所有领先的云服务提供商上运行。每一个实现都按照创建它们的云提供商所希望的方式工作。要获得对PostgreSQL的支持,你必须使用云版本或者第三方提供的专门服务
MongoDB有以下几种形式:
- MongoDB Atlas是一个数据库即服务的产品,运行在所有主要的云平台上(AWS、微软Azure和谷歌云平台)。
- MongoDB Community edition是一个开放的免费数据库,可以安装在Linux、Windows或Mac OS上。
- MongoDB企业版基于MongoDB社区版,附加的功能只能通过MongoDB企业高级订阅获得。Enterprise Advanced包括对MongoDB部署的全面支持。它还添加了面向企业的特性,如LDAP和Kerberos支持、磁盘加密、审计和操作工具。MongoDB Enterprise可以安装在Linux、Windows或Mac OS上。
此外,MongoDB支持多种编程语言。为十多种语言提供了本地的惯用驱动程序——社区还构建了更多的驱动程序——支持特别查询、实时聚合和富索引,以提供强大的编程方法来访问和分析任何结构的数据。
MongoDB有一个强大的开发者社区,它代表了从爱好者到最具创新性的初创企业到最大的企业和政府机构的每个人,包括众多的系统集成商和顾问,他们提供广泛的商业服务。
MongoDB Atlas也通过MongoDB Realm进行了扩展,以简化应用程序开发,通过Lucene提供的Atlas搜索,以及支持在云对象存储上构建的数据湖的特性。
PostgreSQL和MongoDB都有强大的开发人员和顾问社区,他们随时准备提供帮助。
MongoDB的适合目的
在开发的这个阶段,MongoDB提供了业界领先的可伸缩性、弹性、安全性和性能:但它的最佳位置在哪里呢?
MongoDB擅长处理现代应用程序和api生成的数据结构,理想的定位是支持敏捷、快速变化的当今开发实践的开发周期。
真正的问题是你的数据最终会是什么样子。如果数据与应用程序代码中的对象一致,那么就可以很容易地用文档表示它。MongoDB在开发和生产中都是一个很好的选择,特别是当你需要扩展的时候。
但是,如果您有许多基于关系数据模型的现有应用程序,并且团队只熟悉SQL,那么像MongoDB这样的文档数据库可能不太合适。
文档数据库可以进行连接,但是它们与多页SQL语句不同,多页SQL语句有时是必需的,通常由BI工具自动生成。也就是说,MongoDB确实有一个ODBC连接器,允许SQL访问,主要来自BI工具。
Posrgresql:一个现代的SQL数据库
和Linux一样,PostgreSQL是一个管理良好的开源项目的例子。作为采用最广泛的关系数据库之一,PostgreSQL起源于1986年加州大学伯克利分校的POSTGRES项目,并随着时代的发展而发展。
PostgreSQL是一个对象关系数据库
PostgreSQL自称是一个开源的对象关系数据库系统。
它是一个SQL数据库,它有一些处理索引、增加并发性和实现优化和性能增强的策略,包括高级索引、表分区和其他机制。
PostgreSQL的对象部分与许多扩展相关,这些扩展使它能够包含其他数据类型,如JSON数据对象、键/值存储和XML。
核心SQL支持
PostgreSQL的设计原则强调SQL和关系表,并允许扩展性。
PostgreSQL提供了许多方法来提高数据库的效率,但在其核心上它使用了一种扩展策略。
像MySQL和其他开放源码关系数据库一样,PostgreSQL已经在许多行业中被证明是具有高要求用例的坩埚。
在我们进行比较的主要问题之前,让我们先介绍一下PostgreSQL的一些优势:什么时候表格、关系模型和sql最适合应用程序?
PostgreSQL采取了一种实用的、工程思维的方法来处理几乎所有的事情。例如,考虑以下关于符合最新SQL标准的声明:
“PostgreSQL试图遵循SQL标准,这样的一致性不会与传统特性相冲突,也不会导致糟糕的架构决策。”
对他们有利。正如他们正确指出的那样:
“在撰写本文时,没有任何关系数据库完全符合本标准。”
在SQL的世界中,有很好的SQL引擎,可以很好地处理一组简单的查询,也有更健壮的SQL引擎,带有查询优化器,可以处理复杂的查询,并且总是能够得到正确的结果。PostgreSQL是一个健壮的SQL引擎。
这种稳健性来自于长期的稳定发展。一个应该给SQL迷留下深刻印象的细节是,它支持“SQL标准中定义的所有事务隔离级别,包括serializable”。“这是一个工程水平,大多数长期使用的商业数据库都不会为此烦恼,因为它很难以足够的性能实现。”
性能、安全性和可靠性
因为PostgreSQL依赖于一个扩展策略来扩展写入或数据量,所以它必须充分利用可用的计算资源。PostgreSQL通过各种索引和并发策略来实现这一点。
PostgreSQL提供了各种强大的索引类型来最佳匹配给定的查询工作负载。索引策略包括b -树、多列、表达式和部分,以及高级索引技术,如GiST、SP-Gist、KNN GiST、GIN、BRIN、覆盖索引和bloom过滤器。
除了一个成熟的查询规划器和优化器,PostgreSQL还提供了性能优化,包括并行化读取查询、表分区和即时(JIT)表达式编译。
该数据库遵守广泛的安全标准,并具有许多特性来支持可靠性、备份和灾难恢复(通常通过第三方工具)。
可扩展性
PostgreSQL支持多种方式的可扩展性,包括存储函数和过程,从过程性语言(如PL/PGSQL、Perl、Python等)访问,SQL/JSON路径表达式,以及使用标准SQL接口连接到其他数据库或流的外部数据包装器。
许多扩展提供了额外的功能,包括PostGIS,一个用于地理空间分析的模块。
领导和标准化
因为PostgreSQL被广泛使用,所以可以肯定的是,大多数开发工具和其他系统都已经用它进行过测试,并且是兼容的。
PostgreSQL所采取的将语言的api连接到它的数据库的方法已经被许多其他数据库模仿,使得运行在PostgreSQL上的程序更容易移动到另一个SQL数据库上,反之亦然。
PostgreSQL是符合目的的
正如我们在开始所说的,问题不是“MongoDB vs PostgreSQL?”而是“什么时候使用文档数据库vs关系数据库有意义?”因为每个数据库都是其特定数据库格式的最佳版本。
SQL的优点包括为使用SQL数据库而构建的工具、集成和编程语言的庞大生态系统。您可以很容易地找到帮助,使您的SQL数据库项目在一般情况下和PostgreSQL项目在特定情况下工作。PostgreSQL还有很多部署选项。
MongoDB还是PostgreSQL?
放弃SQL意味着离开已经使用SQL的大型技术生态系统。如果您正在开发一个新的应用程序,或者计划对现有的应用程序进行现代化,那么这样做会更容易。
许多数据管理和BI工具都依赖于SQL,并以编程的方式生成复杂的SQL语句,以便从数据库中获得正确的数据集合。PostgreSQL在这种情况下做得很好,因为它是一个健壮的、企业级的实现,被许多开发人员理解。
此外,如果您有一个扁平的、表格式的数据模型,它不会经常更改,也不需要向外扩展,那么关系数据库和SQL可能是一个强大的选择。
但是,必须考虑SQL的预期好处带来的成本。
与MongoDB相比,PostgreSQL的缺点是它依赖于关系数据模型,而这种模型对开发人员在代码中使用的数据结构不友好,而且必须提前定义,因此每当需求发生变化时,开发进度就会变慢。
MongoDB之所以能够很好地支持快速、迭代的开发周期,是因为文档数据库在开发人员的控制下将数据转换为代码。这种速度被关系数据库中使用的严格的表格数据模型的性质所破坏,数据库管理员通常必须通过一个中间过程对其进行重塑,从而降低了整个开发过程。这样的瓶颈会阻碍创新。
当一个应用程序上线时,PostgreSQL用户必须准备好与可伸缩性进行斗争。PostgreSQL使用了一种扩展策略。这意味着在某些情况下,对于高性能用例来说,您可能会遇到瓶颈,或者不得不转移资源,通过缓存或反规范化数据或使用其他策略来寻找其他扩展方法。
在MongoDB中,这类技术通常是不需要的,因为通过本地分片内置了可伸缩性,支持水平向外扩展的方法。在正确分片集群之后,您总是可以添加更多实例并继续向外扩展。MongoDB Atlas拥有广阔的多云、全球感知的平台随时待命,一切为您全面管理。
PostgreSQL可以支持复制,但自动故障转移等更高级的功能必须由独立于数据库开发的第三方产品支持。这种方法比MongoDB内置的自修复功能更复杂,运行速度更慢,无缝性也更差。
您的数据模型将走向何处?
您的数据和目标用例的性质也非常重要。那些拥有大量SQL技能和工具的生态系统以及大量现有应用程序的用户可以选择继续使用关系数据模型。
但是MongoDB已经成功了,尤其是在企业中,因为它打开了通向开发人员生产力新水平的大门,而静态关系表常常带来障碍。如果您有需要大规模交付的数据,那么可以从开发人员对模式的控制中获益,或者满足您一开始并不能完全理解的需求,那么像MongoDB这样的文档数据库就很适合。
MongoDB和PostgreSQL都是优秀的数据库。我们希望这次讨论能给您一些新的启发,使您能更好地满足您的需要。
原文:https://www.mongodb.com/compare/mongodb-postgresql
本文:http://jiagoushi.pro/node/1138
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 214 次浏览
【数据库架构】构建具有更好性能的强一致性的Cassandra:YugaByte
在之前关于数据库一致性的博客中,我们详细讨论了应用程序在处理最终一致的NoSQL数据库时所面临的风险和挑战。我们也打破了一致星展银行最终比强烈一致星展银行表现更好的神话。在这篇博客中,我们将更深入地研究YugaByte数据库是如何在提供强一致性的同时优于Apache Cassandra这样的最终一致性数据库的。注意,YugaByte DB保留了与Cassandra Query Language (CQL) API的drop-in兼容性。
YugaByte DB vs Apache Cassandra性能
雅虎云服务基准测试(YCSB)是一个广为人知的NoSQL数据库基准测试。我们对YugaByte DB和Apache Cassandra运行了YCSB测试,并且兴奋地发现YugaByte DB在吞吐量和百分之99 (p99)延迟上都比Apache Cassandra要好。

YCSB—读写吞吐量(越多越好)
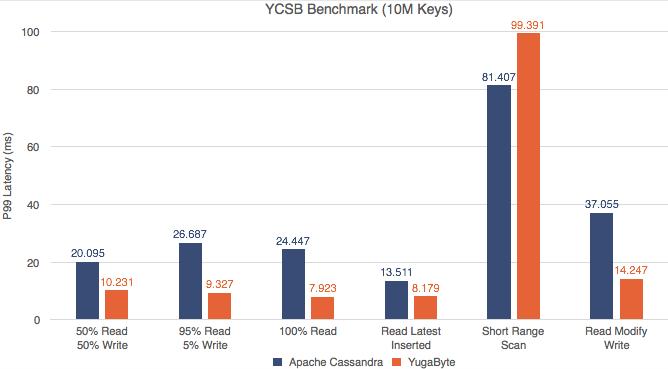
YCSB -读取和写入P99延迟(越少越好)
不仅YugaByte的DB性能更好,而且随着数据密度(更多的键)的增加,边际也会扩大。对详细的性能数字和测试配置感兴趣的读者可以在这里查看我们的文章。
为什么YugaByte DB优于Apache Cassandra?
YugaByte DB优于Apache Cassandra有6个重要的架构上的原因。
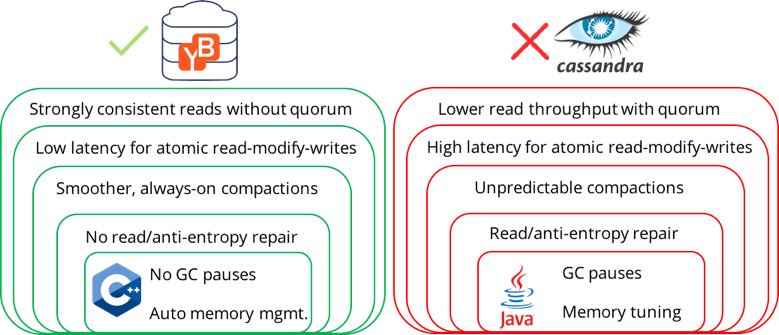
1. 较高的读取吞吐量和较低的延迟
为了使用仲裁读取在最终一致的DB中实现强一致性(到某一点),读操作需要从仲裁中的所有副本中读取数据,以返回大多数仲裁同意的结果。因此,读取的次数乘以复制因子(3x或更多)。同样的复制因子放大了系统负载,从而对系统的吞吐量产生了负面影响。
不仅负载放大了,而且由于从副本读取所需的额外网络往返,响应时间也增加了一倍以上。当网络被额外的流量堵塞时,情况会变得更糟。另外,在读取的关键路径上放置3台服务器会对p99延迟产生不利影响。由于这些架构上的约束,Apache Cassandra的吞吐量较低,延迟较高。
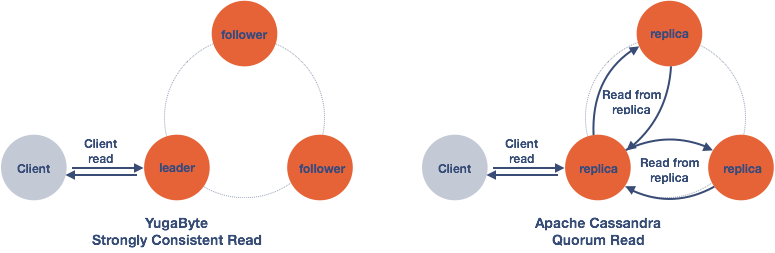
1x vs 3x读取YugaByte vs Apache Cassandra
让我们将其与在读取操作期间执行的YugaByte进行比较。由于使用了RAFT consensus协议,quorum leader持有的数据保证是一致的。所以读操作只需要从前导器读取一次(1x)。因此,如下表所示,YugaByte可以提供更好的性能,因为它既没有读取放大也没有到其他副本的往返。
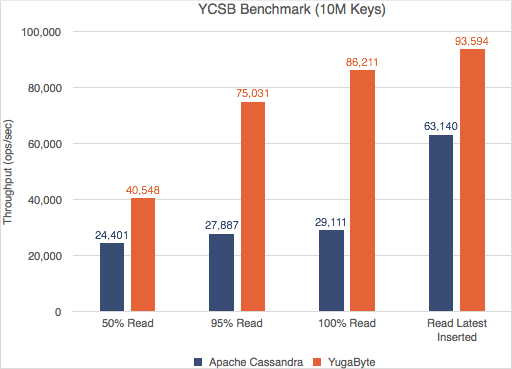
YCSB – Read Throughput (More is Better)
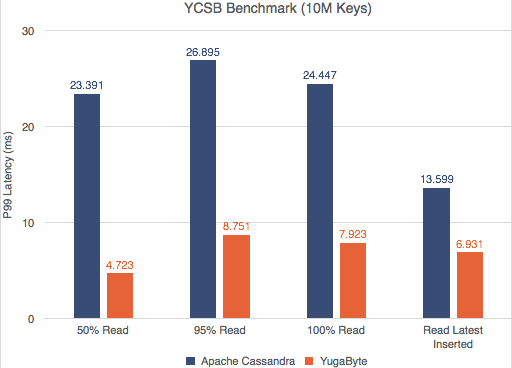
YCSB -读取P99延迟(越少越好)
2. 较高的读-修改-写吞吐量和较低的延迟
非原子的读-修改-写:在上面的读-修改-写工作负载中,YCSB使用两个独立的不带原子性的读和写数据库语句对读-修改-写操作建模。因此,我们已经看到YugaByte DB比Apache Cassandra更好。
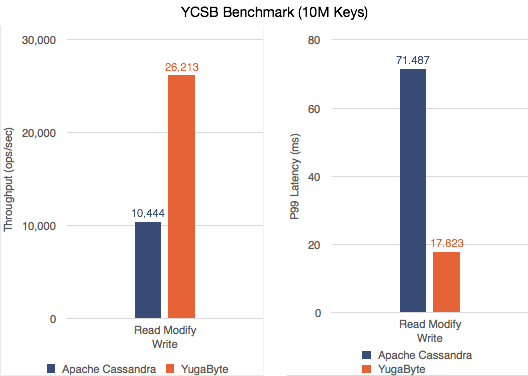
YCSB—读写吞吐量(越多越好)和P99延迟(越少越好)
原子的读-修改-写:为了实现原子性,读-修改-写操作可以作为一个轻量级事务(LWT)执行。在Apache Cassandra中,LWT从leader到副本总共需要4次往返,以准备、读取、提议和提交事务。许多往返会导致严重的延迟和LWT性能差,对用户应用程序产生负面影响。
在ygabyte DB中,因为quorum leader总是保存一致的并且是最新的数据副本,所以LWT只需要一次(1x)往返到副本来更新数据。这种更好的一致性设计使YugaByte执行LWT比Apache Cassandra更快。
3.压缩期间的可预测性能
Apache Cassandra中另一个导致速度变慢的主要原因是后台压缩。当运行主要的压缩时,用户经常抱怨他们的应用层有较高的前台延迟。
这是因为长时间运行或主要压缩会“饿死”较小但关键的压缩作业。这种饥饿会导致读取延迟的增加。完成较大的压缩之后,就可以运行较小的压缩,延迟也会降低。这使得延迟在应用程序端不可预测。高级技术用户通常会在非高峰时间在后台安排自己的压缩,但这既困难又不总是可能的。
在YugaByte DB中,我们将压缩分为主压缩和小压缩,并将它们安排在不同的队列中,并具有不同的优先级。这保证了较小的关键压缩具有一定的服务质量,将后台压缩对用户应用程序的影响降到最低。
4. 没有读取/反熵修复
在像Apache Cassandra这样最终一致的数据库中,任何副本中都可能存在不一致的数据。有两种处理方法。
读修复:一个读操作需要从所有副本读取以确定一致的结果。每当在任何副本中检测到不一致的数据时,该副本将需要立即进行前台读修复。
反熵维护:此外,最终一致的数据库还需要定期的后台反熵维护,对所有副本中的数据进行比较,并修复任何不一致的数据。
上面的操作开销很大,需要大量的CPU和网络带宽来将数据的副本发送给副本并进行比较。对于最终用户应用程序,这表现为更高的/不可预测的延迟,以及系统无法有效地支持更大的数据集。
在YugaByte DB的情况下,由于筏协议保证了强一致性,既不需要读修复,也不需要反熵维护。这将导致较低且可预测的p99延迟。我们使用Netflix数据存储基准(NDBench)进行了7天的基准测试,很高兴地看到p99的延迟低于6毫秒,甚至p995的延迟低于7毫秒。
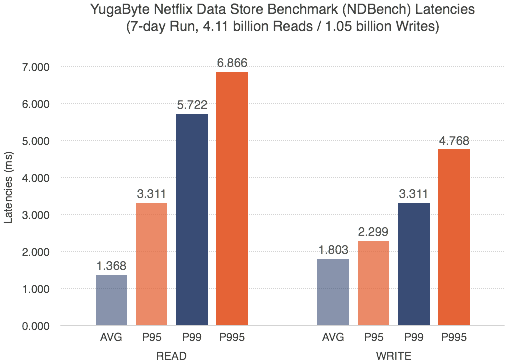
NDBench - YugaByte DB vs Cassandra Latency
5. 没有垃圾收集暂停
在基于java的NoSQL数据库(如Apache Cassandra)中,长时间的垃圾收集(GC)暂停是生产环境中的一个众所周知的问题。当垃圾收集器暂停应用程序、标记和移动正在使用的对象以及丢弃未使用的对象以回收内存时,就会发生这种情况。在一个长时间运行的数据库中,这种GC暂停通常会导致周期性的系统不可用和长响应时间(“长尾”问题)。虽然最先进的垃圾优先(Garbage First, G1) GC可以通过限制暂停时间在一定程度上缓解这个问题,但不幸的是,它是以降低吞吐量为代价的。最后,用户将不得不牺牲应用程序吞吐量或延迟。
因为YugaByte DB是用c++实现的,不需要垃圾收集,所以我们的用户可以毫无妥协地拥有最大的吞吐量和可预测的响应时间。
6. 利用更大的内存来获得更好的性能
除了GC调优,Java内存调优是Apache Cassandra用户面临的另一个典型挑战。它需要非常了解JVM堆大小应该是什么,哪些数据存储在堆外缓冲区中。而且,将更多内存分配给Java堆可能会损害性能,因为GC暂停时间更长。所有这些都增加了用户需要克服的操作复杂性。
另一方面,YugaByte DB可以在大内存机器上高效运行,有效利用可用内存,而不需要手动调整和调优。
总结
在这篇博客中,我们深入探讨了YugaByte DB如何通过更好的设计和实现来提供强大的一致性和卓越的性能。
原文:https://blog.yugabyte.com/building-a-strongly-consistent-cassandra-with-better-performance/
本文:http://jiagoushi.pro/node/1140
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 110 次浏览