【事件驱动架构】Apache Kafka再平衡协议:再平衡协议101
自从Apache Kafka 2.3.0以来,Kafka Connect和消费者特别使用的内部再平衡协议经历了几次重大变化。
再平衡协议不是一件简单的事情,有时看起来像魔术。在这篇文章中,我建议回到这个协议的基础,也就是Apache Kafka消费机制的核心。然后,我们将讨论其局限性和目前的改进。
Kafka和再平衡协议101
让我们回到一些基本的东西
Apache Kafka是一个基于分布式发布/订阅模式的流媒体平台。首先,称为生产者的流程将消息发送到主题中,主题由代理集群管理和存储。然后,称为消费者的流程订阅这些主题,以获取和处理发布的消息。
主题分布在许多代理中,以便每个代理管理每个主题的消息子集——这些子集称为分区。分区的数量是在创建主题时定义的,可以随着时间的推移而增加(但是要小心操作)。
要理解的重要一点是,对于Kafka的生产者和消费者来说,分区实际上是并行的单位。
在生成器端,分区允许并行地写入消息。如果使用密钥发布消息,那么在默认情况下,生成器将散列给定的密钥以确定目标分区。这保证了具有相同密钥的所有消息都将被发送到相同的分区。此外,使用者将保证按照该分区的顺序获得消息传递。
在使用者方面,主题的分区数量限制了使用者组中活动使用者的最大数量。使用者组是Kafka提供的一种机制,用于将多个使用者客户机分组为一个逻辑组,以便负载平衡分区的使用。Kafka保证一个主题分区只分配给组中的一个使用者。
例如,下图描述了一个名为a的消费者组,其中有三个消费者。用户已经订阅了主题A,分区分配为:P0到C1、P1到C2、P2到C3和P1。
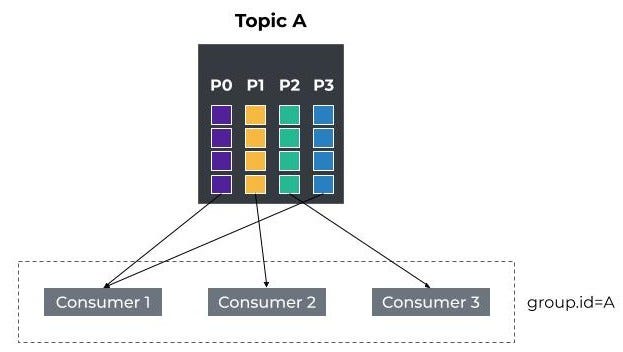
Apache Kafka -消费者组
如果一个使用者在有控制的关闭或崩溃后离开组,那么它的所有分区将在其他使用者之间自动重新分配。同样,如果一个使用者(重新)加入一个现有组,那么所有分区也将在组成员之间重新平衡。
消费者和客户在一个动态群体中合作的能力是通过使用所谓的Kafka再平衡协议而实现的。
让我们深入研究这个协议,了解它是如何工作的。
再平衡协议简述
首先,让我们给出一个术语“再平衡”在Apache Kafka上下文中含义的定义。
再平衡/再平衡:一系列使用Kafka客户端和/或Kafka协调器的分布式进程组成一个公共组,并在组的成员之间分配一组资源的过程(来源:增量合作再平衡:支持和政策)。
上面的定义实际上没有引用消费者或分区的概念。相反,它使用成员和资源的概念。造成这种情况的主要原因是,rebalance协议不仅限于管理使用者,还可以用于协调任何一组流程。
以下是一些协议再平衡的用法:
- Confluent模式注册表依赖重新平衡来选择leader节点。
- Kafka Connect使用它在工人(workers)之间分配任务和连接器。
- Kafka Streams使用它为应用程序流实例分配任务和分区。
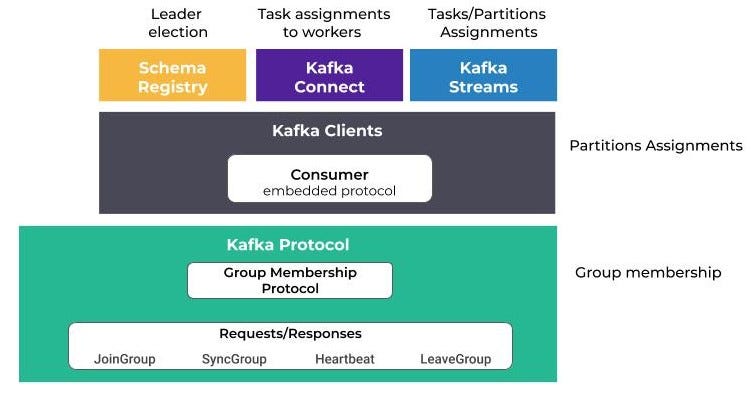
Apache Kafka重新平衡协议和组件
另外,真正需要理解的是,再平衡机制实际上是围绕两种协议构建的:组成员协议和嵌入客户端协议。
组成员协议,顾名思义,负责组成员之间的协调。参与组的客户机将使用充当协调器的Kafka代理执行一系列请求/响应。
第二个协议在客户端执行,允许通过嵌入第一个协议来扩展第一个协议。例如,使用者使用的协议将把主题分区分配给成员。
现在我们对什么是再平衡协议有了更好的理解,让我们来演示它在消费者组中分配分区的实现。
JoinGroup
当使用者启动时,它发送第一个FindCoordinator请求,以获得负责其组的Kafka代理协调器。然后,它通过发送一个JoinGroup请求来启动再平衡协议。
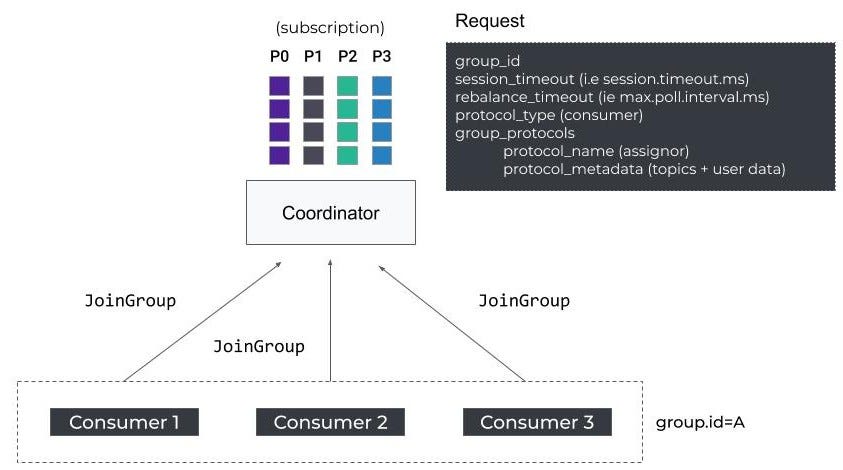
用户-再平衡协议-同步组请求
可以看到,JoinGroup包含一些客户端配置,比如session.timeout。和最大值。max.poll.interval.ms。如果成员不响应,协调器将使用这些属性将其踢出组。
此外,该请求还包含两个非常重要的字段:成员支持的客户端协议列表,以及用于执行嵌入式客户端协议之一的元数据。在我们的示例中,客户机协议是为使用者(i)配置的分区分配程序列表。i.e : partition.assignment.strategy)。元数据包含使用者订阅的主题列表。
请注意,如果您不知道这些属性是干什么用的,我建议您阅读官方文档。
JoinGroup充当屏障,意味着只要没有接收到所有消费者请求,协调器就不会发送响应(i.e group.initial.rebalance.delay.ms)或达到重新平衡超时。
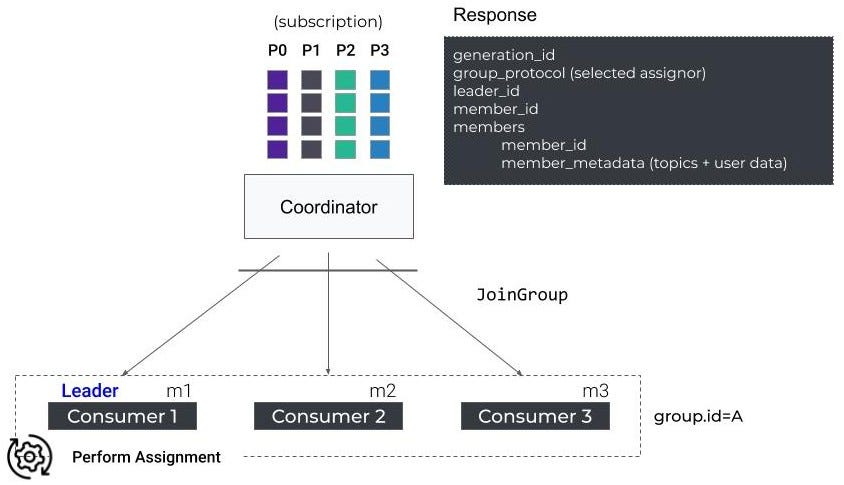
用户-再平衡协议-同步组请求
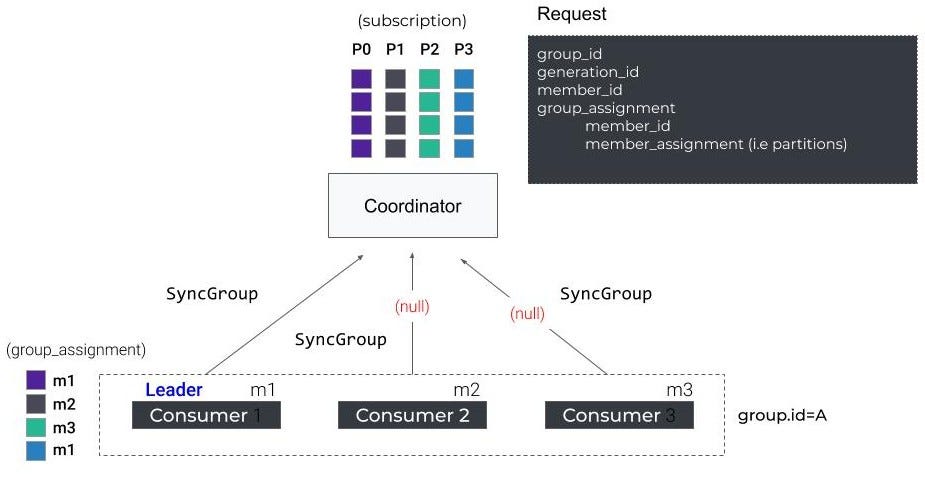
组中的第一个使用者接收活动成员列表和所选的分配策略,并充当组长,而其他使用者接收空响应。组长负责在本地执行分区分配。
SyncGroup
接下来,所有成员向协调器发送一个SyncGroup请求。组长附加了计算后的分配,而其他人只是响应一个空请求。
一旦协调器响应allsyncgrouprequest,每个使用者就会接收到他们分配的分区,调用配置的侦听器上的theonPartitionsAssignedMethod,然后开始获取消息。
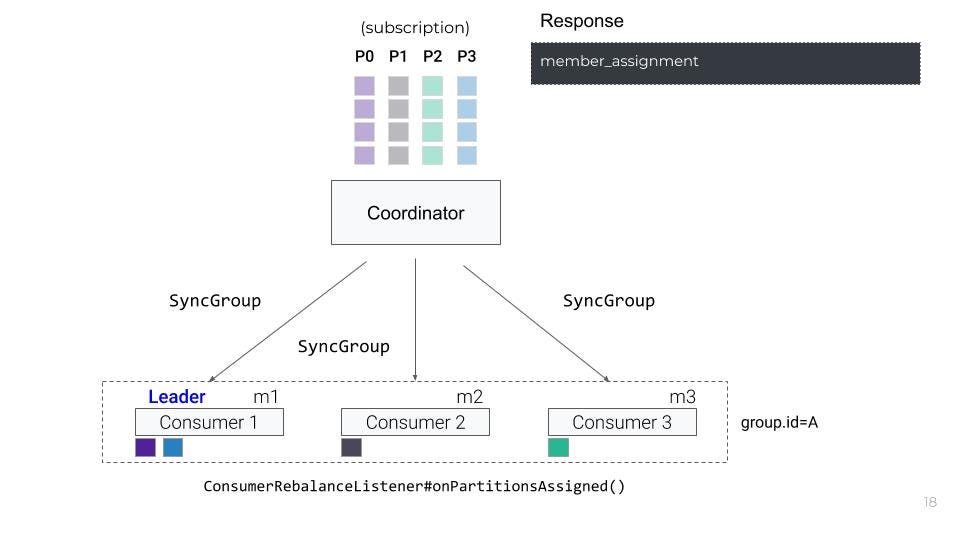
消费者-再平衡协议-同步集团反应
心跳
最后但并非最不重要的是,每个使用者定期向代理协调器发送一个Heatbeat请求,以使其会话保持活动状态(参见:heartbeat.interval.ms)。
如果再平衡正在进行,协调者使用Heatbeat响应来指示消费者,他们需要重新加入该组织。
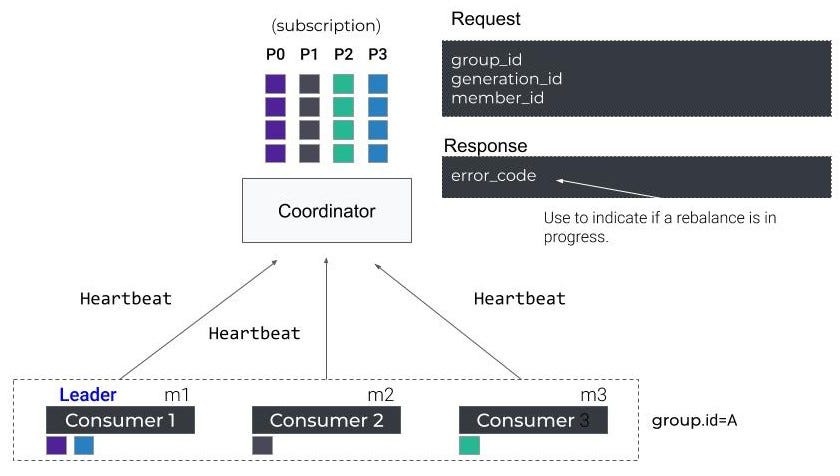
消费者-再平衡协议-心跳
到目前为止一切都很好,但是正如您应该知道的那样,在实际情况中,尤其是在分布式系统中,会发生故障。硬件可以失败。网络或用户可能会出现瞬态故障。不幸的是,对于所有这些情况,再平衡也可能被触发。
一些警告
再平衡协议的第一个限制是,我们不能简单地再平衡一个成员而不停止整个集团(停止世界效应)。
例如,让我们正确地停止一个实例。在第一个重新平衡场景中,使用者将在停止之前向协调器发送一个LeaveGroup请求。
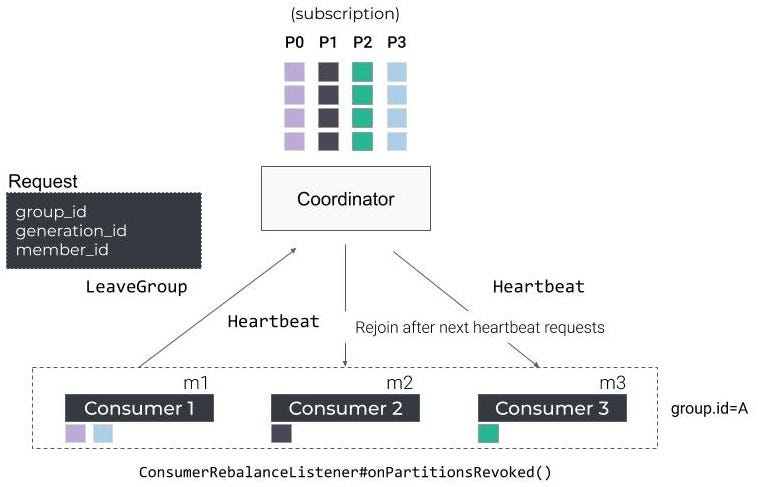
消费者-再平衡协议-离开集团
剩余的使用者将被通知必须在下一个心跳上执行再平衡,并将启动一个新的JoinGroup/SyncGroup往返,以便重新分配分区。
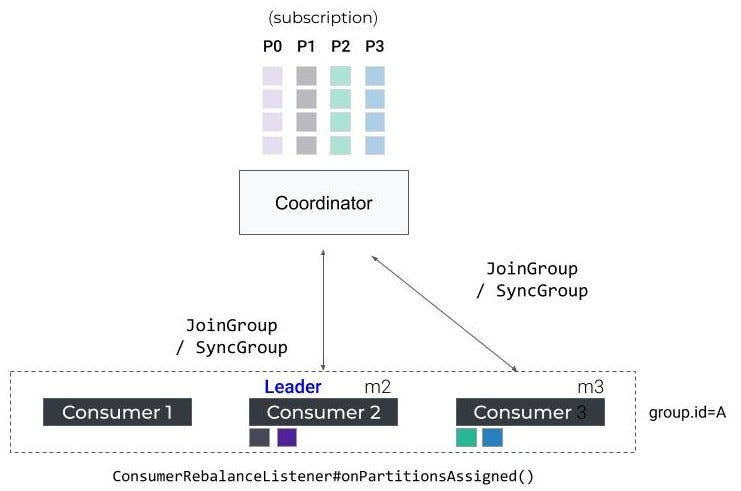
消费者-再平衡协议-重新加入
在整个重新平衡过程中,即只要没有重新分配分区,消费者就不再处理任何数据。默认情况下,重新平衡超时固定为5分钟,这可能是一段很长的时间,在此期间不断增加的用户延迟可能会成为一个问题。
但是,如果使用者只是在短暂故障后重新启动,会发生什么呢?嗯,消费者在重新加入这个群体的同时,将触发一种新的再平衡,导致所有消费者(再一次)停止消费。
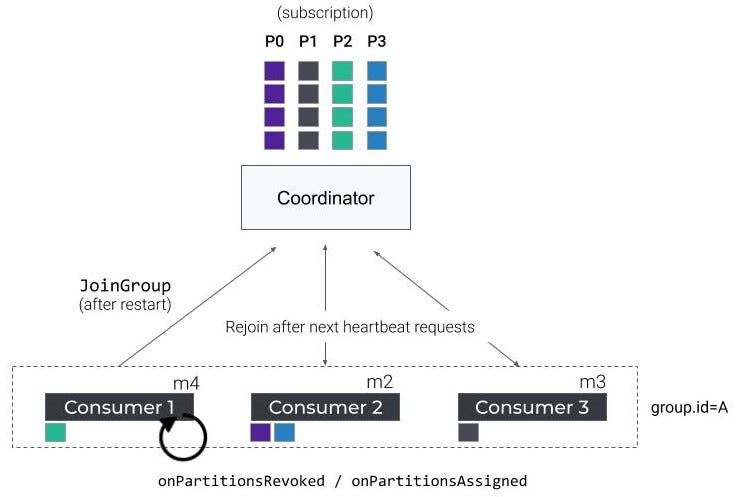
消费者-再平衡协议-重启
另一个可能导致消费者重启的原因是集团的滚动升级。不幸的是,这种情况对消费组来说是灾难性的。实际上,对于一组三个使用者,这样的操作将触发6个重新平衡,这可能对消息处理产生重大影响。
最后,在Java中运行Kafka使用者时的一个常见问题是,由于网络中断或长时间GC暂停而丢失一个心跳请求,或者由于处理时间过长而没有定期调用KafkaConsumer#poll()方法。在第一种情况下,协调器不会接收到超过session.timeout的心跳。认为消费者已经死了。在第二个示例中,处理轮询记录所需的时间优于max.poll.inteval.ms。
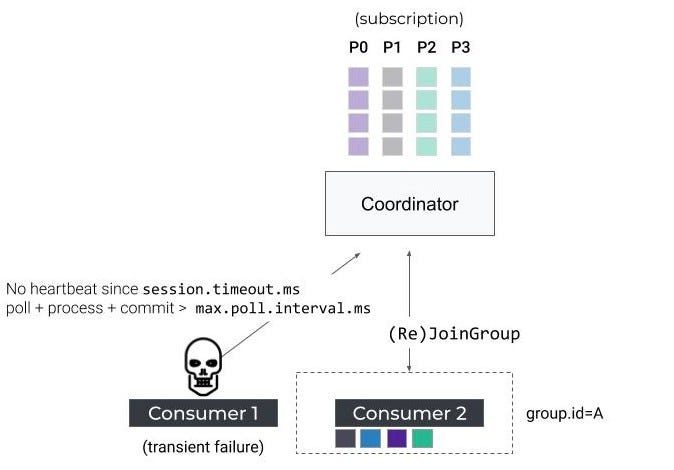
消费者-再平衡协议-超时
本文:http://jiagoushi.pro/node/1113
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 112 次浏览